3주차 - 스토리지
개요
쿠버 스토리지에 대한 내용은 전부 알고 있다고 생각하고, 관련한 정리를 이미 마친지 오래다.
그래서 한다면 efs, ebs 스토리지 드라이버를 사용하면서 테스트를 하는 내용을 정리하자.
추가적으로 인스턴스 스토어를 잘 활용하는 방식에 대한 탐구를 넣는 것도 조헧다.
이후에는 각 노드 그룹에 대한 테스트를 정리하며 될 것 같다.
각각을 세팅하는 방법에 대해서는 어느 정도 쉽게 해낼 수 있다고 생각한다.
그러므로, 각각을 세팅한 이후에 차이점을 정리하는 게 주 정리의 대상이 될 것이다.
efs가 그냥 nfs를 사용하는 방식이라면, 퍼블릭으로 노출되는 것은 심각한 보안 위협이 생기지않나 싶다.
스토리지 성능 측정 도구, kubestr

기본 설치를 하고 그냥 해당 명령어를 사용하면 현재 존재하는 스토리지 프로비저너를 확인할 수 있다.
세팅한 EKS에는 아무런 세팅 없이도 과거의 잔재인 인트리 ebs 프로비저너가 세팅은 돼있다.
그러나 막상 이걸 이용해봐도 아무런 동작은 하지 않는다.
이 친구는 ebs csi 드라이버를 세팅했을 때 비로소 사용할 수 있다.

이 녀석은 kubernetes.io/로 시작하며 나중에 볼 ebs 드라이버가 사용하는 프로비저너 이름과 다르다.
그럼 이제 본격적으로 각종 스토리지들을 테스트해보자!
로컬 프로비저닝 테스트
로컬 프로비저너로도 동적으로 할 수 있도록 지원하는 프로젝트가 있다.
https://github.com/rancher/local-path-provisioner
그러나 쿠버네티스에서 기본으로 지원하는 방향은 아니며, 또 더불어 앞으로도 지원할 계획은 없다고 알려져있다.
현재 이 프로비저너는 사이즈 제한을 지원하지도 않기에, 정말 실습용 그 이상 그 이하도 아니라고 개인적으로 생각한다.
그래도 ConfigMap을 활용해 동적 설정 변경 기능을 지원하니, 연습하기에는 좋을 것이라 생각한다.
kubestr은 동적 프로비저닝 기능을 기반으로 테스트를 진행하기에, 이걸 세팅해서 기본 로컬의 속도를 측정해보자.
kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/v0.0.31/deploy/local-path-storage.yaml
단순히 속도 측정을 위해 설치를 하기에 그냥 단순하게 설치한다.
기본값으로 테스트하면 100Gib로 테스트를 하게 되는데, 이건.. 내가 미리 할당 받은 양보다 너무 크다..
kubestr fio -s local-path -z 10
그러므로 설정값을 미리 둔다.

기본으로 진행된 테스트는 이렇다.
각각의 설정 차이와 결과 차이를 비교해보겠다.
각 기본 세팅은 kubestr#fio 작성법에 담겨있다.
- read_iops
- block size 4k, 랜덤 읽기
- iops는 243, bw(대역폭)은 990
- read_bw
- block size 128k, 랜덤 읽기
- iops는 239, bw(대역폭)은 31241
- 블록 사이즈가 늘어남에 따라, 단위 전송량이 커졌고 이에 따라 iops는 소폭 하향 하는 대신 대역폭은 늘었다.
- write_iops
- block size 4k, 랜덤 쓰기
- iops는 216, bw(대역폭)은 880
- read_iops와 얼추 비슷한 성능으로 보인다.
- write_bw
- block size 128k, 랜덤 쓰기
- iops는 745, bw(대역폭)은 96021
- 블록 사이즈가 늘어났는데 iops가 증가했다.
- 이 부분에 대해
내부 캐시 및 쓰기 합병 효과 등을 활용, 오버헤드가 상대적으로 줄어들고 한 번에 더 많은 데이터가 전송라는 지피티의 답변이 있었다.
현재 사용되고 있는 블록은 gp3로, 최대 iops가 3000이며 처리량은 125로 설정돼있다.
write bw에서 iops가 더 높았다는 것은 조금 신기한데, 이론적으로는 블록 사이즈가 작을수록 iops가 높을 것이라 생각했기 때문이다.
[global]
ioengine=libaio
direct=1
bs=4k
runtime=120
time_based=1
iodepth=16
numjobs=16
group_reporting
size=1g
[read]
rw=randread
read 테스트는 이렇게 진행한다.
[global]
ioengine=libaio
direct=1
bs=4k
runtime=120
time_based=1
iodepth=16
numjobs=16
group_reporting
size=1g
[write]
rw=randrw
rwmixread=0
rwmixwrite=100
write 테스트는 이렇게 진행한다.
이번에는 스터디에서 제공해준 파일을 그대로 이용한 것이다.
기본 설정값과 크게 달라진 점은 numjobs의 수를 16으로 하여 병렬적으로 작업이 일어나게 했다는 것이다.
또 시간을 120초로 늘리고 direct=1을 설정하여 os 차원의 캐시는 발생하지 않는다.
이전 세팅과 동일하게 비동기 작업을 실행하는 대신 각 잡은 동시에 최대 16의 요청을 보내므로 256 개의 요청이 동시적으로 일어날 수 있다.
총체적으로는, 실제 디바이스에 행해지는 작업에 대해서 오랜 시간 결과를 수집하므로 비교적 안정적인 결과를 기대할 수 있을 것이다.
후술할 것이나, efs 관련 이슈로 인해 나중에는 numjobs를 8로 줄여 진행했다.
EBS CSI 드라이버 세팅 및 테스트
테라폼 세팅
resource "aws_eks_addon" "ebs-csi" {
cluster_name = module.eks.cluster_name
addon_name = "aws-ebs-csi-driver"
addon_version = "v1.39.0-eksbuild.1"
resolve_conflicts_on_update = "PRESERVE"
configuration_values = jsonencode({
defaultStorageClass = {
enabled = true
}
node = {
volumeAttachLimit = 31
enableMetrics = true
}
# controller = {
# serviceAccount = {
# annotations = {
# # "eks.amazonaws.com/role-arn" = module.ebs_csi_irsa.iam_role_arn
# "eks.amazonaws.com/role-arn" = "arn:aws:iam::${data.aws_caller_identity.current.account_id}:role/ebs-csi"
# }
# }
# }
})
service_account_role_arn = module.ebs_csi_irsa.iam_role_arn
}
module "ebs_csi_irsa" {
source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-accounts-eks"
version = "5.52.2"
attach_ebs_csi_policy = true
force_detach_policies = true
role_name = "ebs-csi"
oidc_providers = {
eks = {
provider_arn = module.eks.oidc_provider_arn
namespace_service_accounts = ["kube-system:ebs-csi-controller-sa"]
}
}
}
간단하게 클러스터가 세팅된 이후 테스트를 해본 이후, 테라폼으로 세팅을 옮겼다.
기존에는 eks 모듈 내에서 애드온 양식을 만들었으나, 설정 오류 시에 매번 eks 모듈 전체를 다시 프로비저닝해야 한다는 불편함과 정확한 양식을 알기 힘들다는 단점까지 고려하여 리소스로 따로 분리하는 것이 좋다고 판단하였다.
기존에 세팅을 해뒀던 대로 IRSA 설정 역시 직접 전부 만들까 생각했는데, 설정이 복잡하지도 않은 주제에 어렵지도 않으면서 너무 코드가 길어진다는 단점, 꽤나 자료가 확보된 모듈이 이미 있다는 점에서 aws에서 지원하는 모듈을 활용하기로 마음 먹었다.[^4]

iam 모듈에서는 다양한 iam 사용 사례에 대한 예시를 전부 정리해뒀고, 세팅도 간편하게 돼있어 활용하기에 좋다고 생각했다.
구축 확인

세팅이 제대로 됐다면 데몬셋으로 각 노드에서 마운팅을 도와주는 파드와, aws api에 접근해 볼륨을 받아내는 컨트롤러가 배포되는 것을 확인할 수 있다.
재밌는 점은 윈도우를 위한 데몬셋도 같이 배포는 된다는 점인데, 아마 세팅에서 이건 바꿀 수 있지 않을까 한다.
k get daemonsets.apps ebs-csi-node -o jsonpath='{.spec.template.spec.containers[*].name}'
# ebs-plugin node-driver-registrar liveness-probe
노드 데몬셋에는 세 가지 컨테이너가 위치하고 있는데, 재밌게도 liveness probe 용 컨테이너가 따로 있다.
k get csinodes.storage.k8s.io ip-192-168-2-230.ap-northeast-2.compute.internal -o yaml

관련된 CRD를 확인해볼 수 있는데, 여기에 초반에 설정한 세부스펙이 나온다.
설정으로 할당할 수 있는 드라이버의 개수를 31개로 늘린 것이 여기에서 확인된다.
k get deployments.apps ebs-csi-controller -o jsonpath='{.spec.template.spec.containers[*].name}'
# ebs-plugin csi-provisioner csi-attacher csi-snapshotter csi-resizer liveness-probe
디플로이먼트에는 6개의 컨테이너가 돌아가고 있다.
k get sc ebs-csi-default-sc -o yaml | yh
처음에 기본 스토리지가 만들어지도록 설정을 했으므로 이미 스토리지 클래스가 만들어져 있다.

테스트
kubestr fio -f read.fio -s ebs-csi-default-sc --size 10G --nodeselector node.kubernetes.io/instance-type=t3.medium
kubestr fio -f write.fio -s ebs-csi-default-sc --size 10G --nodeselector node.kubernetes.io/instance-type=t3.medium
간단하게 똑같이 테스트를 해볼 수는 있는데, 어차피 기본으로 세팅되는 것은 현재 인스턴스에서 사용하는 gp3로 똑같기 때문에 성능 상의 차이는 발생하지 않는다.

read 테스트에서 iops는 3000, bw 12000

write에서 iops 3000, bw 12000.
gp3를 기본 세팅했을 때 설정된 값으로서 기본 ec2의 ami가 설치된 ebs와 당연히 결과는 같다.

테스트가 이뤄지고 있는 사이 콘솔에서 확인해보면 pvc를 위한 볼륨이 하나 만들어진 것을 확인할 수 있다.

ebs 드라이버는 복수의 노드에서 마운팅을 할 수 있도록 하는 ReadWriteMany 옵션을 지원하지 않아서 해당 옵션을 사용하면 에러가 난다.
애초에 ebs 자체가 multi-attach 기능을 활성화하지 않는 이상 블록 스토리지로서 다중 마운팅을 지원하지 않기도 하고, 또한 기본 사용 방향성이 AZ간 교차가 불가능하도록 설계됐기 때문이다.
볼륨 확장 테스트
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ebs-claim
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
storageClassName: ebs-csi-default-sc
---
apiVersion: v1
kind: Pod
metadata:
name: app
spec:
terminationGracePeriodSeconds: 3
containers:
- name: app
image: centos
command: ["/bin/sh"]
args: ["-c", "while true; do echo $(date -u) >> /data/out.txt; sleep 5; done"]
volumeMounts:
- name: persistent-storage
mountPath: /data
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: ebs-claim
볼륨 확장을 테스트하기 위한 파드와 pvc를 만들어보자.

현재 이 친구는 1기비바이트의 용량을 가지고 있다.
여기에서 바로 pvc에 대해 k edit등의 방법으로 크기를 확장시킬 수 있다.

나는 2기비바이트로 늘려봤는데, 시간은 조금 걸리는 게 보인다.

콘솔에서는 업데이트가 느리나, 클러스터에서 추적하기로는 2분 정도의 시간이 소요된 것으로 보인다.

확장되는 속도의 차이의 이유는 잘 모르겠지만, 다른 양식으로 테스트할 때는 또 엄청 빠르게 됐다.
참고로 볼륨 확장은 돼도 축소는 되지 않는다.
설계 의도의 관점에서는 볼륨 확장은 필요한 용량을 안전하게 추가 확보하기 위해 마련된 기능이지 자유자재로 볼륨 크기를 조절하라고 내준 기능이 아니기 때문이다.
용량 확보를 위해 새로운 pvc, 새로운 자원을 만들어야 한다면 기존의 데이터를 유지하는데 난항이 생기기에 만들어진 기능일 뿐이다.
하지만, 축소가 가능한 경우가 있기는 하다.

Kubernetes v1.32 - Penelope 기준으로 베타가 된 기능인데, 볼륨 확장 실패에 대해서 축소하는 방향을 리사이징을 하는 것이 기본값으로 설정됐다.
가능한 범위보다 크게 확장을 시도한 경우인데, gp3 기준으로는 16테비바이트 이상으로 두면 된다..[^5]

20테라 바이트를 넣어주니 리사이저가 할 일이 많아 좋아 죽으려고 한다.

는 생각해보니.. 지금 내가 설치한 버전이 1.31이라 기본값이 false...
온프렘으로 할 땐 항상 최신 버전으로 쓰다보니 당연히 됐는데 ㅂㄷㅂㄷ

혹시나 하고 해당 노드에 들어가서 kubelet 설정을 건드려봤으나 바뀌는 건 없었다.
애초에 validation에서 막히고 있다는 것은, api 서버쪽에서도 피쳐 게이트를 명시적으로 설정을 해줘야 한다는 것으로 해석할 수 있고, api 서버는 사용자가 건드릴 수 있는 영역이 아니므로 처음부터 클러스터를 구축할 때 버전을 잘 세팅하는 수밖에 없을 것 같다.
간단한 스테이트풀 어플리케이션 테스트
볼륨 스냅샷 기능까지 써보기 위해, 기본적인 예제를 만들어보자.
기본 예제는 여기에서 전부 받아서 실행한다.[^6]
kubectl label namespace default elbv2.k8s.aws/pod-readiness-gate-inject=enabled
여기에 나는 커스텀 세팅을 조금 더 했다.
ALB Controller를 쓰므로 레디네스 게이트 설정을 해준다.
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
annotations:
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
spec:
ports:
- port: 80
selector:
app: wordpress
tier: frontend
type: LoadBalancer
명확하게 어노테이션도 미리 달아뒀다.
k apply -k .
디렉토리를 하나 파고, kustomize를 이용해 전체 파일을 한번에 빌드한다.
참고로 말하자면, 이 예시에서는 디플로이먼트를 사용하나 replica가 1이다.
현재 활용하는 ebs 드라이버는 한 노드에서만 마운팅하도록 제한하므로, 만약 여러 노드에 걸쳐 파드가 분산되면 먼저 만들어진 파드만 배치가 될 것이다.

테스트를 위해 Topology Spread Constraints로 파드를 분산시켰는데 다른 노드에 볼륨이 없어 스케줄이 될 수 없다고 표시되고 있다.

근데 사실 해당 예제는 같은 노드에 전부 스케줄링을 한다고 해도 디비 락 때문에 두번째 파드부터는 제대로 동작하지 않는다 ㅋ

아무튼 레디네스 게이트가 활성화됐으니, 실제 로드밸런서가 제대로 만들어지고 그쪽에서도 파드로의 헬스체크가 제대로 완료됐다는 것을 알 수 있다.

성공적으로 내 로컬환경에서도 서비스가 접근된다.

딸깍 글을 만들었다.
k exec -ti wordpress-mysql-bbb4fcd55-86wfk -- /bin/bash
mysql -u wordpress -p1234 wordpress
show tables;
describe wp_posts;
select id, post_author, post_name, post_status from wp_posts;
각 명령을 차례차례 실행하여 실제 데이터가 어떻게 담겼는지 확인해본다.
유저 정보는 처음 mysql을 배포할 때 환경변수로 설정된 값이니 양식을 참고하면 된다.

한글이 깨져 나와서 test란 이름으로 글 하나를 더 만들었다.
스냅샷 구축 및 테스트
이제 이 데이터가 제대로 보전될 수 있는지 확인해보자.
kubectl kustomize https://github.com/kubernetes-csi/external-snapshotter/client/config/crd | kubectl create -f -
스냅샷 crd는 해당 레포에서 다운받을 수 있다.[^7]

crd들이 성공적으로 설치됐고, 다음으로는 이 crd를 활용할 수 있도록 하는 컨트롤러를 설치한다.
kubectl kustomize https://github.com/kubernetes-csi/external-snapshotter/deploy/kubernetes/snapshot-controller | kubectl create -f -

이제부터 해당 오브젝트들을 사용할 수 있다.
이미 나는 스냅샷을 지원하는 ebs 드라이버를 가지고 있으므로 바로 사용이 가능하다.
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-ebs-csi-driver/master/examples/kubernetes/snapshot/manifests/classes/snapshotclass.yaml

ebs드라이버의 예제 스냅샷클래스를 받아왔다.
이제 본격적으로 스냅샷을 뜨고, 이걸 이용해서 복원을 진행해보자.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: mysql-snapshot
spec:
volumeSnapshotClassName: csi-aws-vsc
source:
persistentVolumeClaimName: mysql-pv-claim

현재 pvc를 스냅샷으로 만드려고 하니 1분도 안 돼서 스냅샷이 사용 가능한 상태가 됐다.

스냅샷의 id와 스냅샷에 해당하는 볼륨의 정보가 나와있다.

이 값은 콘솔에 나오는 값과 정확하게 일치한다.
정적 스냅샷 컨텐트 생성
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
name: static-volumesnapshot-content
spec:
deletionPolicy: Delete
driver: ebs.csi.aws.com
source:
snapshotHandle: snap-08601e327de7f4464
sourceVolumeMode: Filesystem
volumeSnapshotClassName: csi-aws-vsc
volumeSnapshotRef:
name: recovered-snapshot
namespace: default
콘솔에서 확인한 스냅샷 id를 이용해서 source 부분을 작성한다.
생각하지 못한 지점은, volumeSnapshotRef를 반드시 지정해야 한다는 것이다.
나중에 만들고자 하는 스냅샷의 이름을 지정해주었다.

크기에 대한 정보가 제대로 가져와진 것으로 보아, 정상적으로 스냅샷 정보를 읽은 듯하다.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: recovered-snapshot
spec:
source:
volumeSnapshotContentName: static-volumesnapshot-content
그대로 스냅샷도 만들어주었다.

기존 앱 삭제 후 데이터 복원
k delete -k .

이제 남은 pvc가 없는 상태이다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
dataSourceRef:
name: recovered-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
여기에 자동으로 만들어진 스냅샷을 써도 되겠지만, 정적으로 만든 녀석을 한번 써보자.
쿠스토마이즈 파일에서 mysql pvc를 하던 부분의 코드를 수정했다.

이런 식으로 파일을 복사 분할했는데, 쿠스토마이즈로 이를 효율적으로 하는 방법이 있을지도 모르겠다.

추가적으로 실험을 해보고 싶어서 일부러 스토리지 용량 자체는 더 작은 값인 10Gi로 해봤는데 에러가 발생한다.

다시 볼륨 크기를 맞추고 실행하자 제대로 이전 데이터가 남은 채로 어플리케이션이 실행됐다.
스냅샷을 활용한 멀티 az 마운팅
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: dup-binding
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
dataSourceRef:
name: mysql-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
어차피 한 스냅샷에 대해서 여러 개의 볼륨을 만들어내는 게 가능하다면, 이를 통해 여러 노드에서 한 스냅샷을 활용할 수 있지 않을까?
문득 궁금해져 시험해봤다.

결론적으로, 가능하다.
물론 파일시스템 스토리지처럼 실시간 동기화를 하는 것은 불가능하겠지만, 같은 데이터를 여러 az에서 보는 것만이 목적이라면 이런 방법도 있다 정도로 생각하면 좋을 듯하다.
EFS CSI 드라이버 세팅 및 테스트
이번에는 AWS EFS CSI Driver를 사용해본다.
테라폼 세팅
resource "aws_efs_file_system" "efs" {
creation_token = "my-product"
lifecycle_policy {
transition_to_ia = "AFTER_30_DAYS"
}
}
data "aws_iam_policy_document" "efs" {
statement {
sid = "efs-mount"
effect = "Allow"
principals {
type = "AWS"
identifiers = ["*"]
}
actions = [
"elasticfilesystem:ClientMount",
"elasticfilesystem:ClientWrite",
]
resources = [aws_efs_file_system.efs.arn]
}
}
resource "aws_efs_file_system_policy" "efs" {
file_system_id = aws_efs_file_system.efs.id
policy = data.aws_iam_policy_document.efs.json
}
resource "aws_efs_mount_target" "efs" {
count = length(module.eks_vpc.public_subnets_id)
file_system_id = aws_efs_file_system.efs.id
subnet_id = module.eks_vpc.public_subnets_id[count.index]
security_groups = [
data.aws_security_group.cluster.id
]
}
먼저 efs를 만들어주는 작업을 한다.
기본적으로 aws 리소스에서 파일시스템에 마운팅과 읽기 작업을 할 수 있도록 정책을 적용하고, eks 클러스터에서 마운팅할 수 있도록 타겟을 만들어준다.
세팅의 편의성을 위해 별도의 보안그룹을 만들지 않고 클러스터 노드들이 가지는 보안그룹을 설정해주어 바로 마운팅이 가능하도록 만들었다.

프로비저닝이 완료되면, 이렇게 efs 네트워크 탭에 들어가 이렇게 마운팅 타겟이 설정된 것을 확인할 수 있다.
resource "aws_eks_addon" "efs_csi" {
cluster_name = module.eks.cluster_name
addon_name = "aws-efs-csi-driver"
addon_version = "v2.1.4-eksbuild.1"
resolve_conflicts_on_update = "PRESERVE"
configuration_values = jsonencode({ })
service_account_role_arn = module.efs_csi_irsa.iam_role_arn
}
module "efs_csi_irsa" {
source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-accounts-eks"
version = "5.52.2"
role_name = "efs-csi"
attach_efs_csi_policy = true
force_detach_policies = true
oidc_providers = {
eks = {
provider_arn = module.eks.oidc_provider_arn
namespace_service_accounts = ["kube-system:efs-csi-controller-sa"]
}
}
}
다음으로 클러스터가 구축된 이후 바로 애드온이 설치되도록 irsa와 애드온 세팅을 해주었다.
애드온 설정에서 기본 스토리지 클래스를 만드는 옵션이 없어서 별도의 세팅을 넣지는 않았다.
구축 확인 및 세팅
aws efs describe-file-systems --query "FileSystems[*].FileSystemId" --output text
nfs 서버에서 주소를 넣어주듯이, efs 볼륨의 id를 먼저 알아내야 한다.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: efs-sc
provisioner: efs.csi.aws.com
parameters:
provisioningMode: efs-ap # 엑세스엔드포인트 모드. 다른 것 불가능
fileSystemId: fs-92107410
directoryPerms: "700"
basePath: "/dynamic_provisioning" # 해당 볼륨의 어디를 활용할 건지
subPathPattern: "${.PVC.namespace}/${.PVC.name}" # optional
ensureUniqueDirectory: "true" # 알아서 디렉 이름이 고유하도록 uuid 붙이는 설정
reuseAccessPoint: "false" # optional
동적 프로비저닝을 위해 이렇게 스토리지 클래스를 만들었다.
filesystemId에 위에서 알아낸 파일시스템 id를 기입해주면 된다.
테스트
kubestr을 통해 efs는 스토리지 성능이 어느 정도 되는지 확인해본다.

read의 경우 iops 18435, bw 73741.
이전과 똑같이 세팅을 해서 진행하려 했으나, num jobs가 16일 때는 계속 context deadline exceeded 오류가 떠서 제대로 테스트를 할 수 없었다.
csi 드라이버와 efs 자체적으로 처리량에 대한 옵션이 없는 것으로 보아, 일단 efs 자체의 한계일 것이라 감안하고 어쩔 수 없이 num jobs를 8로 낮춘 결과이다.

write의 경우에는 iops 6000, bw 24000 정도.
ebs에서는 iops가 3000, bw 12900 정도로 고정돼있던 결과와 사뭇 다르다.
efs의 경우에는 직접적으로 iops, bw값을 설정할 수가 없으며 사용량에 따라 알아서 유동적으로 조정이 된다.
최소한 기본 ebs값보다는 높게 나오는 것이 확인된다.

여담이지만, 테스트를 하니까 바로 처리량 alert가..
다중 노드 동시 접근
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: efs-claim
spec:
accessModes:
- ReadWriteOnce
storageClassName: efs-sc
resources:
requests:
storage: 5Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: efs-app
name: efs-app
spec:
replicas: 3
selector:
matchLabels:
app: efs-app
template:
metadata:
labels:
app: efs-app
name: efs-app
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: efs-app
containers:
- name: app
image: centos
command: ["/bin/sh"]
args: ["-c", "while true; do echo $(hostname ; hostname -I) >> /data/out; sleep 5; done"]
volumeMounts:
- name: persistent-storage
mountPath: /data
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: efs-claim
세팅은 이렇게 했다.
워크로드는 토폴로지 스프레드를 걸어 확실하게 모든 파드가 각 노드에 스케줄링되도록 유도했다.
그리고 각 파드는 자신의 이름과 ip 주소를 출력하여 같은 공간에 입력한다.
언뜻 보면 이상할 수도 있는 부분으로, pvc에서 ReadWriteOnce를 모드로 명시하고 있다.
Once는 한번에 한 노드에서만 접근이 가능하다는 것을 나타내는 것이라 안 될 수 있겠다고 생각할 수 있다.
그러나 어디까지나 액세스 모드는 pv와 pvc를 매칭하기 위한 조건으로 사용되는 필드라는 것을 명심해야 한다.
실제로 해당 필드는 접근 방식에 대한 어떠한 제한도 걸지 않으며, 이에 대한 구현과 적용은 전적으로 csi 드라이버에서 담당할 뿐이다.
nfs와 마찬가지로 efs는 파일시스템 볼륨으로서 여러 공간에서의 동시 접속을 지원하기 때문에 실상 ReadWriteOnce로 접근 모드 필드를 작성하더라도 아무런 영향이 없다.
k exec -ti efs-app-6f95dfc768-p5d29 -- cat /data/out

적당한 파드 하나 잡아서 출력을 걸어보면, 각 노드에 위치한 컨테이너들이 열심히 일을 하고 있는 것을 볼 수 있다.

콘솔에서 확인해보면 클레임 하나에 한 액세스포인트가 만들어진 것이 보인다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: efs-pv1
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: efs-sc
csi:
driver: efs.csi.aws.com
volumeHandle: fs-e8a95a42::fsap-068c22f0246419f75
귀찮아서 굳이 더 하진 않았지만, 만약 액세스포인트별로 접근을 하고 싶을 때 쓰는 방법이 있다.
먼저 액세스 포인트를 만들어둔 이후에 {efs id}::{ap id}를 넣어주면 된다.
https://github.com/kubernetes-sigs/aws-efs-csi-driver/blob/master/docs/efs-create-filesystem.md
s3 드라이버
인스턴스 스토어 활용하기
이번에는 인스턴스 스토어를 활용해서 조금 더 빠른 스토리지를 활용하는 방법을 보도록 한다.
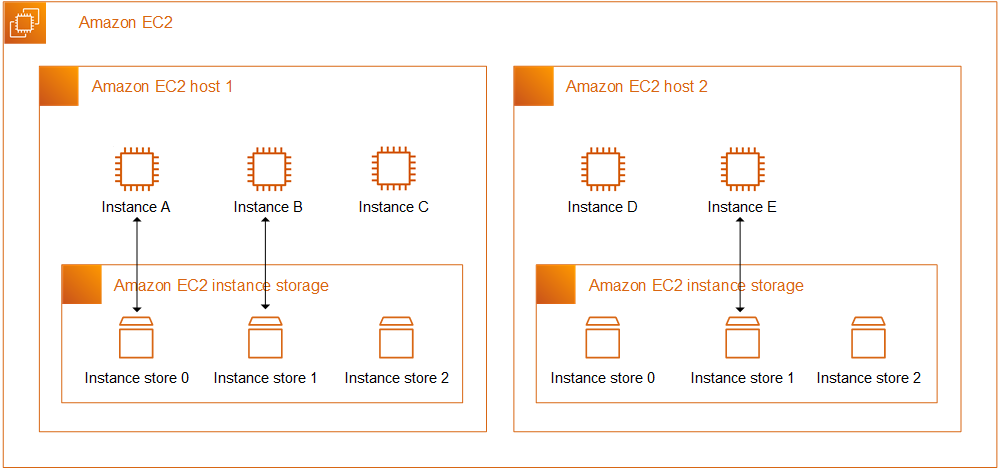
인스턴스 스토어는 실제 해당 인스턴스의 물리적 위치에 존재하는 스토리지 공간을 말한다.
몇 가지의 인스턴스 유형을 제외하고 이를 사용할 수 있는데, 아무래도 네트워크를 타야하는 다른 스토리지보다는 훨씬 속도가 빠를 수밖에 없다.
ami 단에서 미리 세팅을 하거나, 보통 nvme를 사용하는 타입은 포맷이 되지 않은 채로 블록이 붙어있다.[^3]
이 저장 공간은 인스턴스와 수명을 같이 하는데, 중지되거나 절전이 되도 데이터를 보장하지 않는다.
그래서 실질적으로 활용할 때는 메모리처럼 빠르면서 휘발성있는 공간으로 생각하는 편이 좋다.
물론 메모리만큼 빠를 순 없다.
인스턴스 스토어 기본 세팅 및 확인
aws ec2 describe-instance-types \
--filters "Name=instance-type,Values=c*" "Name=instance-storage-supported,Values=true" \
--query "InstanceTypes[].[InstanceType, InstanceStorageInfo.TotalSizeInGB]" \
--output table
이렇게 해봤을 때, t 시리즈에는 인스턴스 스토어가 없는 것 같다.
여기에서도 t에 대한 내용은 나오지 않는다.[^2]
이걸로 테스트를 해보려면 다른 사양으로 도전해야 할 듯.

c 시리즈 중 가장 저려미인 c5d.large를 선택해본다.

콘솔에서 ec2를 만들 때도 인스턴스 스토어에 대한 간략한 정보를 확인할 수 있다.

현재 노드에 붙은 nvme 모델은 이렇게 확인할 수 있다.

이 부분의 이유는 잘 모르겠는데, 막상 들어가서 확인해보면 디바이스 이름은 nvme0n1이었다.
이건 아직 식견이 좁아 잘 모르겠으나, 차차 알아보는 것으로 하겠다.
아무튼 현재는 블록 형태로 연결만 돼있는 상태로, 파일시스템을 포맷해서 마운팅을 하는 작업을 해야 한다.

기본 루트 파일시스템은 xfs로 포맷팅되어 있고, 같은 방식으로 포맷을 하도록 한다.
mkfs -t xfs /dev/nvme1n1
mkdir /data
mount /dev/nvme1n1 /data
오랜만에 하니까 좀 버벅인다..

아무튼 성공적으로 인스턴스 스토어 저장소를 활용할 준비가 끝났다.
이제 이런 식으로 인스턴스 스토어를 활용하는 노드 그룹을 만들면 되겠다.
이 공간을 사용하는 방법에 대해서는 자료가 어느 정도는 있는 편이다.[^15]
그런데 이 공간을 무엇으로 활용하는가가 또 관건이다.
두가지 정도의 활용 방안이 있을 것 같다.
- 로컬 볼륨 공간
- 메모리 만큼은 당연히 아니겠지만, 그래도 그나마 빠른 속도의 공간이 필요하다면 요긴할 것이다.
- 이렇게 사용한다면, 정적 프로비저닝을 통해 관리하는 게 좋을 것 같다.
- 용도가 명확한 경우에만 사용할 수 있도록 제한하면서, 사용할 수 있는 양도 명확하게 지정을 하는 방식으로 말이다.
- 컨테이너 실행 공간.
- eks는 CRI로서 containerd를 사용한다.
- containerd는 노드의 공간 중 영구 데이터와 컨테이너의 실행시점 상태 데이터를 저장하는 두 가지 공간을 분리해 사용한다.[^8]
/var/lib/containerd에는 이미지, 스냅샷, 플러그인 등의 영구적이면서 containerd가 직접적으로 만들지 않는 데이터가 담긴다./run/containerd에는 임시 데이터, 소켓, 프로세스 id 등 컨테이너가 실행 중일 때 생기는 일시적인 데이터 정보가 담긴다.
- 참고로 containerd.toml에서는 root, state로 표시된다.
https://aws-ia.github.io/terraform-aws-eks-blueprints/getting-started/#prerequisites
https://registry.terraform.io/modules/terraform-aws-modules/eks/aws/20.33.1
containerd는 컨테이너를 실행하며 많은 파일을 노드 로컬에 파생시킨다.
이 파일들 때문에 노드 자체의 공간이 부족해지는 순간이 올 수 있기에, 이 공간을 따로 블록 볼륨으로 관리하는 것이 가능하다.
https://github.com/containerd/containerd/blob/main/docs/ops.md#base-configuration
https://aws-ia.github.io/terraform-aws-eks-blueprints/patterns/stateful/#eks-managed-nodegroup-w-multiple-volumes
해당 공간을 아예 분리하여 쓰는 것이 로컬 공간을 관리하는데 도움이 될 수 있다.
이것들은 인스턴스 스토어에 넣는 것이 좋은 것 같은 게, 사용되는 자원들은 빠르게 파드에서 접근할 수록 좋다.
https://github.com/aws-ia/terraform-aws-eks-blueprints/blob/main/patterns/stateful/main.tf
containerd는 어디에서 disk io가 많이 일어나는가
나는 여기에서 컨테이너 실행 환경에 대한 io를 처리하는 게 중요하지 않을까 생각하고, 그렇다면 어떤 공간을 인스턴스 스토어로 쓰는 게 좋을지 고찰해보고자 한다.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: instance-test
name: instance-test
spec:
replicas: 3
selector:
matchLabels:
app: instance-test
template:
metadata:
labels:
app: instance-test
spec:
nodeSelector:
disk: instance_store
containers:
- image: centos
name: con1
command: ["/bin/sh"]
args: ["-c", "while true; do echo $(date -u) >> /data/out.txt; done"]
- image: centos
name: con2
command: ["/bin/sh"]
args: ["-c", "while true; do echo $(date -u) >> /data/out.txt; done"]
간단하게 노드 셀렉터로 컨테이너 루트 디렉토리에 쓰기 작업을 하는 디플로이먼트를 만들었다.
처음에는 3개만 두지만, 이어서 25개, 50개 정도로 늘리는 테스트까지 겸할 것이다.
단순 디렉토리 사용량 확인
watch -c -n 0.1 du -sh $(pwd)

어떤 녀석이 io가 많이 일어날까, 관련한 자료가 잘 안 나오는 것 같아서 간단히 크기 변동에 대한 테스트라도 해보려고 한다.
왼쪽이 state, 오른쪽이 root이다.

간단한 워크로드를 띄우고 스케일을 계속 높였다.
처음에 이미지를 받는 순간에 root의 크기도 증가했으나, 이후에 계속 스케일 아웃을 할 때마다 state 부분이 크게 올랐다.
어찌보면 당연하다고 할 수 있겠다.
확실하게 알고 말하는 것은 아니다만, 파일 구조를 살짝 보니 root에서 캐시된 이미지나 각종 정보들을 컨테이너를 실행할 때 state에 상당 부분 옮긴 채로 실행하는 것으로 보였다.
워크로드를 지우면 state 부분은 완벽하게 원래 상태로 돌아간다.
컨테이너를 실행하며 생기는 부산물들이니 사라지는 것은 당연한 수순이긴 하다.
이 간단한 실험을 통해 내가 얻고 싶었던 결론은, 어느 파일들이 disk io가 더 많이 발생하는가였다.
사실 현 실험은 디스크에 차지하는 용량을 보는 것이기 때문에 정확히 내가 원하는 결과를 낸다고 할 수 없다.
다만, 컨테이너가 실행된 이후 생긴 부산물에 대해 이뤄지는 작업들은 결국 state의 영역에서 일어난다고 변화를 보며 유추할 수 있었다.
당연히 그러겠거니 생각만하고 있었지만, 직접 보니 확실히 그런 것이 보인다.

아울러 추가적으로 확인한 것은 컨테이너의 루트 파일시스템의 정확한 위치.
state 영역에 runtime이라는 디렉토리에 실제 컨테이너의 thin 레이어가 위치한다.
만약 컨테이너 내부에서 자체적으로 파일을 만드는 경우라면 확실하게 state 영역의 io가 더 많을 것이라 생각해볼 수 있다.
그러나 이렇게 사용하는 케이스가 많지는 않을 것이라 생각한다.
이미지에서 생긴 레이어의 파일에 접근하는 경우라면 이미지 디렉토리가 위치한 root 영역에 많은 io가 일어날 가능성이 있다.
또한 파드가 여러번 생기고 없어지는 환경이라고 한다면 컨테이너를 띄우기 위해 필요한 각종 파일을 읽기 위해 root 영역의 파일에 많은 io가 발생할 것으로 생각된다.
이걸 정확히 확인하려면 iostat을 써봐야 할 것 같다.
그러기 위해서는, disk를 분할할 필요가 있다.
번외 - cloud init을 이용한 amazon 2023 테라폼 세팅
인스턴스 스토어를 활용하도록, 직접 포맷과 마운팅을 적용하는 스크립트를 넣으려고 했다.
그러나 내 맘대로 세팅을 해보려는데 계속 유저데이터가 적용되지 않는 문제가 발생했다.
Note: `disk_size`, and `remote_access` can only be set when using the EKS managed node group default launch template
eks 서브모듈에는 이러한 설명이 있었다.
그래서 remote access를 위해 항상 커스텀 런치 템플릿을 비활성화해뒀는데, 이것 때문인지 계속 내 설정이 완전히 무시되는 상황을 보게 됐다.

찾아보니, 기본 리소스에서도 이 설정은 충돌이 난다고 표시됐다.
마운팅 자체는 노드 등록이 되기 이전, 노드 bootstrap이 되기 이전에 시행돼야 하므로 remote access를 초기에 설정할 방법이 필요하다.
관련한 옵션과 글을 찾아보는데, 계속 cloud init이라는 게 눈에 띄었다.
결국 Cloud-init을 조사하고 공부하여 세팅을 했다..
(진짜 이거 시간 잡아먹는 괴물이네)
먼저, 요약적으로 amazon 2023에서 이뤄지는 부트스트랩 순서를 정리한다.
amazon 2와 다르게 2023에서는 bootstrap.sh를 이용하여 노드를 세팅하지 않는다.
대신 nodeadm이라는 툴을 이용하며, 클러스터 관련 설정을 미리 하고 싶다면 여기에 넣어줘야 한다.[^17]
그래서 해당 툴이 실행되기 전 전체 초기화 순서는 대충 이렇게 된다.
- cloud init이 발동될 때 넣어줄 수 있는 세팅들의 순서
- cloud init pre nodeam
- nodeadm
- cloud init post nodeadm

이런 식으로 pre_bootstrap 데이터를 넣어보았으나, 해당 데이터는 실행되지 않았다.

cloud init 쪽에서 행한 기록만 남아있는 것이 확인된다.
즉, bootstrap 관련으로 엮인 설정들은 흔한 유저데이터 넣는 방식으로는 al 2023에서는 적용되지 않으며 al 2에서만 적용된다는 것을 알 수 있다.

테라폼 모듈 코드도 뒤졌는데, bootsrap 유저데이터 설정을 하지 않아도 pre nodeadm 설정은 들어갈 수 있도록 세팅이 돼있더라.
최소한 nodeadm 관련 세팅은 그래도 넣을 수 있다는 것으로 이해하면 되겠다.
cloudinit_pre_nodeadm = [
{
content_type = "multipart/mixed; boundary=\"BOUNDARY\""
content = <<-EOT
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary="BOUNDARY"
--BOUNDARY
Content-Type: text/cloud-config
#cloud-config
ssh_authorized_keys:
- ${aws_key_pair.eks_key_pair.public_key}
--BOUNDARY
Content-Type: text/x-shellscript
#!/bin/bash
yum install nvme-cli links tree tcpdump sysstat ipvsadm ipset bind-utils htop -y
mkfs -t xfs /dev/nvme1n1
systemctl stop containerd
rm -rf /run/containerd/*
mkdir -p /run/containerd
mount /dev/nvme1n1 /run/containerd
systemctl start containerd
echo "/dev/nvme1n1 /run/containerd xfs defaults,noatime 0 2" >> /etc/fstab
--BOUNDARY--
EOT
},
수많은 삽질이 있었는데, 일단 이렇게 설정했다.
cloud init의 경우 user data로 들어간 설정을 이런 식으로 읽어 낸다.
그냥 일반적인 스크립트를 넣을 때는 원래 셔뱅을 넣어줘야 하는데, 그게 알고보니 cloud init이 쉘 스크립트를 인식할 때 사용하는 방식이었다는 것을 처음 알게 됐다.
(토니 쌤에게 알려주면 좋아하시려나)
MIME 타입으로 데이터를 넣되, content-type에 내가 넣고자 하는 값이 어떤 타입인지 명시를 해주면 이를 읽고 cloud init이 반영한다.
하도 많은 자료를 찾다보니 어디에서 뭘 찾았는지는 기억이 잘 안 나는데.. 가장 핵심적으로 본 문서는 이거다.[^12]
또한 여기에서 어떤 식으로 써야 데이터가 제대로 들어가는지 미리 검증을 할 수 있었다.[^13]
이제야.. 제대로 테스트를 해볼 수 있게 됐다.
한 두번의 명령어로 간단하게 해결할 것을 완전히 자동화하려하다보면 대개 몇 단계를 건너서 알아야할 게 항상 생긴다..

cloud init 실행의 로그는 /var/lib/cloud-init.log 이런 식으로 찍힌다.
신기한 것이, cloud config로 세팅하지 않고 쉘 스크립트로 설치한 것들도 전부 제대로 기록된다.

/etc/cloud에 들어가보면 어떻게 설치가 이뤄질지에 대한 설정 파일이 존재한다.
각 단게에서 실행될 모듈에 대한 정보가 담기는데, scripts_user 부분에서 내가 넣은 설정이 들어가게 된다.
알파벳 순으로 설정된다기에 내가 넣은 ssh 설정이 덮어씌워지지 않을까 걱정했으나 그런 일은 없었다.

관련한 런치 템플릿은 두 개가 만들어지는데, 하나는 내 데이터가 들어간 녀석이다.

이를 소스로 하여 nodeadm 설정이 들어간 템플릿이 하나 더 만들어진다.

아쉬운 점은, 콘솔에서 실행 시점의 키페어에 대한 표시를 할 수 없다는 것이다.
내가 더 잘 설정하면 가능할지도 모르겠으나 이건 너무 바운더리를 벗어난다.
이걸 알아낸 것이 의미가 없지는 않은 게, 아마존2023에서 노드 관련 설정은 nodeadm을 통해 이뤄진다.
이때 관련 설정을 넣으려면 cloud init 설정을 어떻게 넣는지를 어느 정도는 알고 있어야 한다.
나중에 nodeadm을 추가로 만져야 한다면 여길 참고하면 되겠다.[^14]
{
content_type = "application/node.eks.aws"
content = <<-EOT
---
apiVersion: node.eks.aws/v1alpha1
kind: NodeConfig
spec:
instance:
localStorage:
strategy: RAID0
EOT
}
아예 컨텐츠 타입으로 이렇게 지정하면 조금 더 간편히 설정을 넣을 수 있을 것이다.
다시 containerd disk io 확인
watch -c -d -n 0.1 iostat

아무튼.. 이제 진짜 테스트 시작이다.
위에서 진행했던 세팅들을 다시 해보자.

힘을 다써서 각각이 뭔지는 사진으로 남긴다.
프로메테우스 스택 설치
아니 또 생각해보니, 프메에서 이런 메트릭 수집해주지 않나..?
굳이 어렵게 보려고 하고 있었네..
사실 자주 써보진 않아서, 다른 글을 참고해 쉽게 설치했다.[^11]
kubectl create namespace monitoring
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install prometheus prometheus-community/kube-prometheus-stack --namespace monitoring
간단하게 그라파나 서비스만 로드밸런서로 바꿔주는 작업을 해서 편하게 접속 가능하도록 만드려했는데, 해당 차트에선 values.yaml파일에 관련 세팅을 제공하지 않는다.
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
type=LoadBalancer
다만 이렇게만 서비스 타입을 바꿔준다.
admin, 패스워드는 prom-operator

는 그라파나로 더 이쁘게 볼 수 있길래 그냥 이걸로 보려고 한다.

간단한 모니터링 결과는 내 생각과 많이 달랐다.
state 영역의 지표는 거의 보이지도 않는다.
치솟은 작업은 root 영역에 대한 쓰기 작업으로, 처음에는 워크로드를 실행하고 이후에는 스케일아웃을 한 모습이다.
중간에 살짝 올라온 주황색이 state 영역에 일어나는 쓰기 작업인데, 내가 너무 대충 만들어서 그런가 이 자체가 유의미하게 많이 크게 측정되지는 않는다.
오랫동안 파드를 방치해뒀을 때는 두 값 모두 변동 없이 평이한 상태로 유지됐다.

이건 리소스를 지울 때 상황인데, 이때도 root 영역에서 더 많은 disk io가 관측됐다.
간단 결론
이로부터 내가 생각한 바는 이렇다.
disk io에 가장 큰 영향을 주는 것은 컨테이너가 생성, 삭제되는 시점이다.
이때 이미지를 받아서 로컬에 저장하고, 이미지를 읽이서 컨테이너 프로세스를 실행하는 작업으로 인해 큰 io가 발생하게 된다.
그리고 이 동작들은 실행 중일 때의 데이터를 담는 state 영역보다는 root 영역에서 더 많이 일어난다.
state 영역에 thin layer를 만들고, overlay 설정을 하는 순간에는 state에서도 io가 발생하지만, 대체로 root 보다 크지는 않다.
그리고 이건 일부러 컨테이너 내 루트 파일시스템에 쓰기 작업이 일어나도록 유도한 결과인데, 실제 어플리케이션들의 경우에는 외부 스토리지를 사용하거나, 아니면 스토리지 공간을 많이 활용하지 않는다.
그렇게 봤을 때, state 영역에 대한 io 작업은 훨씬 덜 일어날 것이라고 생각해볼 수 있다.
pid, 각종 stdout이 일어난다고 해도 해당 값들이 이 차이를 메꿀 정도로 유의미하게 일어날지는 모르겠다.
다만 state에서 작업이 일어난다고 한다면, 실행 중인 시점에 결과를 내뿜을 것이라고 생각한다.
위의 결과에서는 컨테이너가 실행 중인 시점에는 별 값의 변동이 없었으나, 어플리케이션에 따라서는 그런 시점에 state 영역에 변화가 발생할 가능성도 무시할 수 없다고 본다.
이로부터 나는 이런 결론을 내리고자 한다.
containerd를 쓸 때, 인스턴스 스토어 공간을 활용하기에 적합한 로컬 공간은 root 영역이다.
이 부분에서의 disk io를 최적화한다면 컨테이너 생성 속도도 빨라지며 한편으로 EBS io 제한에서 자유로워지는데 도움이 될 것이다.
로컬 스토리지로서의 인스턴스 스토어
아울러 추가적으로 인스턴스 스토어를 활용하기 좋은 방향 중 하나는 역시 로컬 스토리지로서의 활용이라고 생각이 든다.
다만 이 경우엔 파드와 라이프사이클을 같이 하거나, 영속성이 필요한 데이터의 경우 확실하게 고가용성 및 백업 전략이 마련된 상태에서 활용하는 것이 좋을 것이다.
systemctl stop kubelet
systemctl stop containerd
cp -r /var/lib/containerd /cache/containerd
umount /var/lib/containerd
cp -r /cache/containerd/ /var/lib/containerd
systemctl restart containerd
systemctl restart kubelet
일단 기존에 사용하던 인스턴스 스토어를 재활용하고자 해당 노드에 들어가서 원복시킨다.
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.k8s.io/pause:3.9"
정확한 이유는 모르겠으나, 단순히 이렇게 하는 것만으로는 pause 이미지가 제대로 남지 않는 듯했다.
/etc/containerd/config.toml에서 원격에서 pause 이미지를 가져오도록 수정해주었다.
systemctl restart containerd
systemctl restart kubelet

이제 이놈을 다시 포맷팅해서 로컬 스토리지로 활용하면 될 것이다.
라 생각했는데.. 암만 봐도 문제 없어보이나 계속 disk busy가 떴다.
그래서 그냥 마운팅할 공간에 붙인 뒤에 내부를 싹 지우는 것으로 선회한다.
k -n local-path-storage get cm local-path-config -o yaml
로컬 프로비저너가 프로비저닝에 활용하는 공간을 확인한다.

opt에 있다는 것을 알 수 있으니, 해당 공간에 다시 인스턴스 스토어를 마운팅하자.
mount /dev/nvme1n1 /opt/local-path-provisioner
rm -rf /opt/local-path-provisioner/*
그 다음 싹 날려준다..ㅋ

이제는 준비가 된 것 같다. 아마..?
k -n local-path-storage rollout restart deployment local-path-provisioner
kubestr fio -f read.fio -s local-path --size 10G --nodeselector disk=instance_store
kubestr fio -f write.fio -s local-path --size 10G --nodeselector disk=instance_store
현재 프로비저너는 덮어씌워진 스토리지를 인식하지 못할 가능성이 있다.
mount propagation 설정을 안 해뒀는지 재시작 없이는 제대로 동작하지 않는 듯하다.
간단하게 인스턴스 스토어 스토리지 성능 측정을 해보면..

왜인지, 성능 측정에 계속 실패한다.

aws 문서에는 읽기와 쓰기에 대해 이정도를 지원한다고 한다.


솔직히 실패에 대한 정확한 이유는 모르겠다.
다만 병렬 횟수를 조금 줄여서 다시 시도했을 때, 문서에 나온 정도의 성능은 나와주는 듯하다.
(인스턴스 스토어가 더 부하에 민감한 이유는 무엇일까...)
최소한 ebs를 스토리지로 활용하는 것보다는 훨씬 성능 상에서 이점을 가진다는 것은 충분히 보인 듯하니 여기에서 실험은 종료하고자 한다.
containerd root 영역 세팅 후 검증
추가적인 이슈로, 1.31 버전에서 containerd의 공간을 마운팅해버리니 기존에 있던 pause 이미지가 사라져서 노드 세팅이 정상적으로 이뤄지지 않는다.
상황을 확인해보니 해당 노드의 pause container 이미지를 local에서 받아오는 데에서 문제가 발생한다.
안그래도 따끈하게 비슷한 이슈를 겪은 케이스가 있고, 이를 해결하기 위해선 마운팅 전에 데이터들을 그대로 마운팅한 공간에 넣으라고 한다.[^16]
pause 이미지를 원격에서 가져오는 피하고자 미리 내부에 넣어뒀다가 이 사단이 나는 모양이다.
mkdir -p /cache
cp -r /var/lib/containerd /cache
rm -rf /var/lib/containerd/*
mkdir -p /var/lib/containerd
mount /dev/nvme1n1 /var/lib/containerd
cp -r /cache/containerd /var/lib
그래서 이렇게 잠시 containerd의 내부 파일들을 꺼내온 후 다시 넣어주는 로직을 추가했다.

간단하게 다시 iostat으로 확인해보면, 이전 사진과 비교했을 때 쓰기 작업이 상당히 많이 일어나는 것을 확인할 수 있다.
이미 이걸로만 확인해도 root 영역의 쓰기가 더 많을 것이라는 것을 나이브하게 유추할 수 있다.

처음 이미지를 받아오는 과정에서 순간 많은 쓰기가 발생했고, 이후 스케일업을 할 때는 그나마 root와 state가 비슷한 정도의 쓰기 처리량을 보였다.
별도의 설정을 하진 않은 것 같은데, 컨테이너가 실행되는 중에도 root 영역에 대한 쓰기가 꽤 많이 일어나고 있다는 것이 조금 의외였다.

디스크 사용량에서도, 결국 root 영역에서는 유의미한 차이가 발생했다.
이 상황은 root 영역만 마운팅을 했기 때문에 사실 state 영역에 대한 지표는 노드 전체에서 일어나고 있는 디스크 io 양이 합쳐진 결과라는 것을 감안해야 한다.
그런 점에서 보았을 때 정말 어마무시한 차이가 난다고 생각해볼 수 있다.
그러니까, 디스크 io 제한을 이유로 인스턴스 스토어를 사용한다면 무조건 /var/lib/containerd를 마운팅하는 것이 정답이라고 이제 확정짓겠다.
절취선
https://github.com/terraform-aws-modules/terraform-aws-eks/issues/2551
테라폼 세팅시 나랑 비슷한 이슈가 과거에도 있었다.
최대 파드 개수의 적용이 제대로 되지 않는 이슈..
vpc cni가 먼저 세팅돼야만 노드 그룹이 알아서 최대개수를 적용하는 모양이다.
csi 구조에 볼륨 스냅샷, 클로닝
https://www.inovex.de/de/blog/kubernetes-storage-volume-cloning-ephemeral-inline-volumes-snapshots/
노드 그룹 다양화
buildx 실습
그라비톤실습
#
kubectl get nodes -L kubernetes.io/arch
# 신규 노드 그룹 생성
eksctl create nodegroup --help
eksctl create nodegroup -c $CLUSTER_NAME -r ap-northeast-2 --subnet-ids "$PubSubnet1","$PubSubnet2","$PubSubnet3" \
-n ng3 -t t4g.medium -N 1 -m 1 -M 1 --node-volume-size=30 --node-labels family=graviton --dry-run > myng3.yaml
cat myng3.yaml
eksctl create nodegroup -f myng3.yaml
# 확인
kubectl get nodes --label-columns eks.amazonaws.com/nodegroup,kubernetes.io/arch,eks.amazonaws.com/capacityType
kubectl describe nodes --selector family=graviton
aws eks describe-nodegroup --cluster-name $CLUSTER_NAME --nodegroup-name ng3 | jq .nodegroup.taints
# taints 셋팅 -> 적용에 2~3분 정도 시간 소요
aws eks update-nodegroup-config --cluster-name $CLUSTER_NAME --nodegroup-name ng3 --taints "addOrUpdateTaints=[{key=frontend, value=true, effect=NO_EXECUTE}]"
# 확인
kubectl describe nodes --selector family=graviton | grep Taints
aws eks describe-nodegroup --cluster-name $CLUSTER_NAME --nodegroup-name ng3 | jq .nodegroup.taints
# NO_SCHEDULE - This corresponds to the Kubernetes NoSchedule taint effect. This configures the managed node group with a taint that repels all pods that don't have a matching toleration. All running pods are not evicted from the manage node group's nodes.
# NO_EXECUTE - This corresponds to the Kubernetes NoExecute taint effect. Allows nodes configured with this taint to not only repel newly scheduled pods but also evicts any running pods without a matching toleration.
# PREFER_NO_SCHEDULE - This corresponds to the Kubernetes PreferNoSchedule taint effect. If possible, EKS avoids scheduling Pods that do not tolerate this taint onto the node.
아직 2주차 실습을 전부 마치지 못해서 이것도 꼭 다하자..
acm 등록이 안 돼서 external dns를 아직도 못쓰고잇다.
(조금 더 비싼 도메인 살 걸)
https://gist.github.com/albertogalan/957a11d15c385c07d0be219a3fbf984c
문득 든 생각이, jsonpath에 대해 탭을 통한 자동완성을 지원하면 편할 것 같다.
스터디 진행
이번에는 efs를 만들어서 할 것이다.
efs를 직접 만들면, 이걸 만드느 과정이 매우 귀찮다.
그래서 클포로 같이 만들어지도록 했다.

eks에 처음 세팅할 때, 처음부터 irsa를 넣는 게 가능하다.
애드온 정책은 서트랑, external만 넣었다.
max 파드 개수도 초반 조정을 한다.
이번에는 노드 볼륨을 120기가로 잡는다.
속도 테스트 시 100기가 이하면 에러가 날 때가 있다.
eks는 기본으로 gp2라는 스토리지 클래스를 둔다.
아마존 리눅스 2023은 부트스트랩 스크립트를 쓰지 않고, kubelet의 config 파일을 사용한다.
/etc/kubenetes/kubelet에 보면 config.json이 있다.
디스크 성능 측정은 iops와 쓰루풋.
kubestr로 스클별 속도 측정할 것.
이건 랜덤 읽기 측정
해보면 iops는 3000, 밴드위드도 나온다.
iops가 많이 필요한 어플리케이션이 있따 해보자.
디스크 장애는 나도 괜찮은.
이럴 때 인스턴스 스토어를 쓸 수 있음
이건 데이터 손실 가능성은 있다.
이건 ec2가 있는 물리 서버의 저장소를 쓰는 것.
그래서 엄청 빠르다만.. 손실은 감내해야하는 것.
카프카나 디비의 경우 어차피 어플 딴에서 복제가 일어나기 때문에 이걸 쓰는게 매우 유용할 수 있다.
7배나 빠르기에, 꽤나 유용할 것이다.
스팟에 대한 스케줄 우선순위가 잇ㅇ르까?
# 관련 문서
| 이름 | noteType | created |
| -- | -------- | ------- |
{ .block-language-dataview}
# 참고
[^1]: https://www.youtube.com/watch?v=U3Rt9vcuQdc
[^2]: https://docs.aws.amazon.com/ko_kr/ec2/latest/instancetypes/gp.html#gp_instance-store
[^3]: https://docs.aws.amazon.com/ko_kr/AWSEC2/latest/UserGuide/making-instance-stores-available-on-your-instances.html
[^4]: https://github.com/terraform-aws-modules/terraform-aws-iam/tree/v5.52.2
[^5]: https://docs.aws.amazon.com/ko_kr/ebs/latest/userguide/general-purpose.html#gp3-sie
[^6]: https://kubernetes.io/docs/tutorials/stateful-application/mysql-wordpress-persistent-volume/
[^7]: https://github.com/kubernetes-csi/external-snapshotter
[^8]: https://github.com/containerd/containerd/blob/main/docs/ops.md#base-configuration
[^9]: https://awslabs.github.io/amazon-eks-ami/nodeadm/doc/playground/
[^10]: https://cloudinit.readthedocs.io/en/latest/index.html
[^11]: https://velog.io/@ironkey/Prometheus-Grafana%EB%A1%9C-Kubernetes-%EB%AA%A8%EB%8B%88%ED%84%B0%EB%A7%81%ED%95%98%EA%B8%B0
[^12]: https://cloudinit.readthedocs.io/en/stable/reference/examples.html
[^13]: https://awslabs.github.io/amazon-eks-ami/nodeadm/doc/playground/
[^14]: https://github.com/awslabs/amazon-eks-ami/tree/main/nodeadm
[^15]: https://aws.amazon.com/ko/blogs/containers/eks-persistent-volumes-for-instance-store/
[^16]: https://github.com/awslabs/amazon-eks-ami/issues/2122
[^17]: https://awslabs.github.io/amazon-eks-ami/