Ceph
개요

분산 클러스터에 구현되는 오픈소스 오브젝트 소프트웨어 정의 스토리지 플랫폼.
말이 너무 길다..
일단 4.RESOURCE/KNOWLEDGE/개념/스토리지 서비스를 구성하는 소프트웨어라는 것을 알면 되시겠다.
그러니까 하드웨어 여러 대를 뭉쳐서 이걸로 묶어서 스토리지를 제공할 수 있다는 말이다.
현존하는 대부분의 클라우드 서비스는 사실 내부적으로 이것으로 구현되어 있다는 말을 봤다.
최소한 오픈스택 진영에서는 거의 필수적으로 사용한다는 듯.
특징
이름에 모든 특징이 다 들어가 있다고 보면 된다.
- 분산 클러스터 구성
- 여러 대의 노드를 이용하여 고가용성, 안정성을 확보한다.
- 오브젝트 스토리지
- 기본적으로 오브젝트 스토리지로 구현되어 있다고 한다.
- 3-in-1
- 그러나 블록, 파일시스템, 오브젝트 모든 인터페이스를 제공한다.
- 어디에든 써먹을 수 있다는 뜻
- 오픈소스
- 소프트웨어 정의
- SDS를 말한다.
- 플랫폼
- 스토리지를 제공하는 툴, 서비스
그러니까 대규모의 다양한 스토리지가 필요한 환경에서 사용할 수 있는 올인원 수준의 소프트웨어라고 보면 될 듯..?
확장도 가능하고 신뢰성도 있고, 성능도 떨어지지 않는 그냥 최고봉 느낌인 것 같다.
규모가 크니까, 작은 기업에서 사용할 급은 아니라는 것 같다.
구조
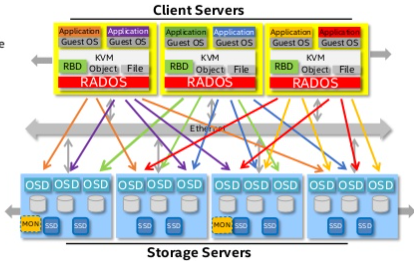
일단 전체 구조는 대충 이렇게 생겼다..
보기만 해도 어지러운데 크게는 하드웨어 근처의 저장과 관리 방식을 정의하는 노드 영역과, 그걸 사용할 수 있도록 하는 클라이언트 영역으로 나뉜다고 보면 되겠다.
여기에서 일단 위에서 말한 특징들을 볼 수 있기는 하다.
이중화되어있다는 것은 소프트웨어 정의 스토리지라는 특징을 여실히 보여준다.
또 분산되어 있고 확장가능하다는 것 역시 이를 통해 유추가 가능하다.
클라이언트 영역
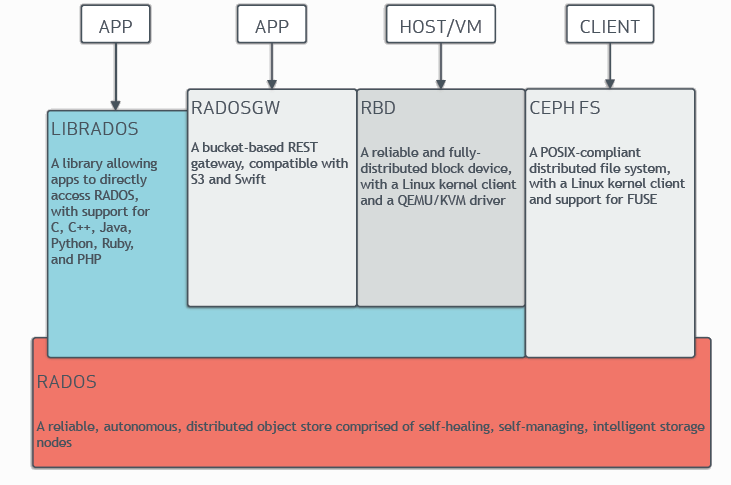
사용하는 입장에서의 아키텍쳐 구조.
일단 여기 있는 것들부터 살펴보자면
RADOS
Reliable, Autunomous, Distrubuted Object Store
그러니까 위에서 말한 스토리지 노드들과의 연결점 정도가 되시겠다.
사실 이 표현이 하드웨어 클러스터 부분을 뭉쳐 지칭하는 건가?
명확하게는 아직 모르겠다.
LIBRADOS
LIBrary allowing to access RADOS
라도스와 연결되는 라이브러리들.
각종 언어로 구현이 가능하다.
만약 사용자는 자신만의 스토리지 형태를 구현하고 싶다면 이 라이브러리를 이용해서 구현하면 된다.
RADOSGW
RADOS GateWay
진짜 이름 킹받네
버킷 베이스의 REST 게이트웨이
즉, 오브젝트 스토리지로 사용할 때 제공되는 인터페이스 정도 되시겠다.
RBD
Realiable and fully distributed Block Device
블록 디바이스.
리눅스나 가상 머신에 블록을 붙일 때 사용하는 드라이버.
CEPH FS
POSIX 와 호환되는 파일시스템
이게 파일 스토리지.
이런 다양한 방식으로 우리는 ceph에 접근할 수 있다! ㅎㅎ..
스토리지 클러스터 영역
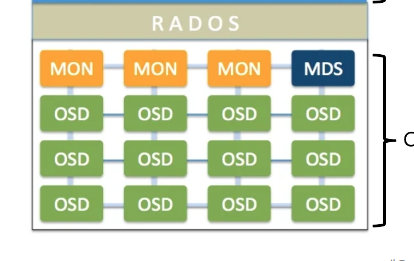
대충 이런 식으로 생긴 모양이다.
MON
MONitor, 모니터.
클러스터의 상태를 저장하고 감시하는 데몬.
고가용성을 위해 최소 3개가 돌아간다.
OSD
Object Storage Daemon
실질적인 데이터 저장 역할을 한다.
MGR
ManaGeR
ㅋㅋㅋㅋ
위에는 안 보이지만 모니터 데몬과 함께 붙어서 실질 모니터링을 제공하던 데몬.
12 버전부터는 이게 없으면 안 돌아간다고 한다.
MDS
MetaData Server
파일 스토리지로 사용될 때 꼭 필요한 놈.
파일시스템의 모든 메타데이터를 저장한다.
데이터 저장 원리
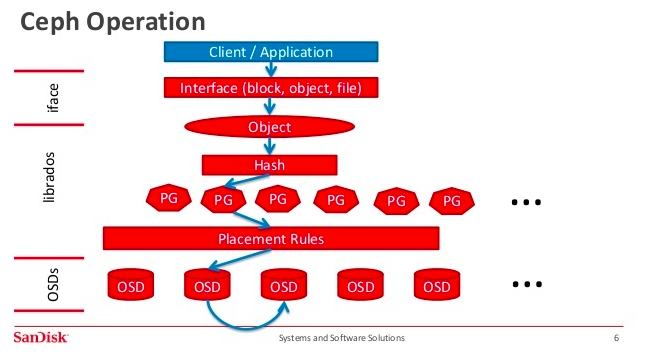
동작은 대충 이렇게 된다고 한다.
데이터가 들어오면, 일단 적당한 크기로 오브젝트화시킨다.

이게 오브젝트의 저장 방식이다.
이런 구조의 핵심은 ID로 문자열을 통해 정렬을 하게되는 파일시스템과 다르게 직관적이고 빠르게 데이터를 관리할 수 있다나..
일단 10기가를 한번에 불러오는 것보다는 1기가를 10개의 노드로부터 불러오는 게 더 빠르긴 할 것이다.
그래서 노드로 관리되는 환경에서는 매우 적합하다는 것 같다.
오브젝트화된 데이터들은 Placement Group으로 짝지어진다.
짝지어진 놈들끼리는 같은 OSD에 저장되게 된다.
이때 적당히 RAID 구성을 하듯이 각 데이터는 각 PG에 적당히 중복돼서 들어간다.
CRUSH
저장은 이렇게 하는데, 불러올 때는 어떻게 불러올까?
4번 데이터는 12번 OSD, 7번 데이터는 6번 OSD.. 이렇게 일일히 테이블을 가지고 있는 것은 꽤나 비효율적이다.
Ceph에서는 Controlled Replication Under Scalable Hashing, 즉 CRUSH라는 알고리즘으로 이를 해결한다.
완벽히 이해는 못 했으나, 어떤 PG가 어떤 OSD에 저장되는지를 계산하는 배치 알고리즘이라고 한다.
달리 말하자면 '어디에 뭐가 저장됐다'를 조회해서 게 아니라, 어떤 식을 계산해보니 '이 데이터는 어디에 저장돼있겠다'라는 방식으로 위치를 알 수 있다는 것.
이 방식의 장점은 중앙 서버가 필요없이 각 클라이언트가 데이터 저장 위치를 계산해낼 수 있다는 것.
중앙 서버가 없으니 분산돼있고, 부하가 몰릴 일도 없다.
나중에 이건 조금 더 자세히 정리해보는 것으로 하자.
설치
사실 이것 때문에 글을 썼다.
기본적으로는 cephadm을 통해 클러스터를 구성한다.
그러나! 쿠버네티스 환경에서 클러스터를 구성하는 방법이 있으니..
이름하야 Rook.
자세한 내용은 저쪽 문서로..
참고
- 공식
- 컨테이너
- 그림
- 크러시
- 기타