DML
개요
Data Manipulation Language.
한글로는 데이터 조작어
SQL에서 가장 많이 쓰이는 언어이다.
구조가 잡힌 테이블에 각종 조작을 가할 때 사용한다.
핵심적으로 딱 4가지라고 말할 수 있다.
삽입, 조회, 수정, 삭제.
즉, CRUD를 할 때 사용하는 언어라는 것이다.
이중에서 가장 중요한 언어는 역시 [[#select]]라고 할 수 있다.
결국 데이터를 넣고 빼고 수정하는 행위는 해당 데이터를 조회하기 위해서라고 말할 수 있을 정도로 사용 비중이 높다.
이후에 보게 될 TCL로 커밋하고, 롤백하는 것이 가능한 언어이다.
INSERT
Create, 즉 삽입에 해당한다.
INSERT INTO TB_SUBWAY_STATN_TMP T
(
T.SUBWAY_STATN_NO , T.LN_NM , T.STATN_NM
)
VALUES
(
'000032' , '2호선' , '강남'
)
;
insert into라는 방식으로 사용한다.
그 뒤에는 어떤 값을 넣을지 넣어주면 된다.
한번에 여러 개를 넣는 것도 가능하다.
또한 null이 가능한 컬럼에 대해서는 값을 넣지 않는 것도 가능하다.
UPDATE
Update, 말 그대로 수정에 해당한다.
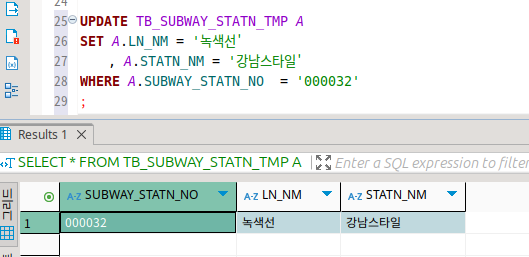
이건 사진으로 대체.
update set 변경값 where 조건
테이블의 컬럼에 변경을 가한다.
이때 where을 넣어서 어떤 행들을 변경할 것인지 써줘야 한다.
where을 넣지 않으면 모든 행이 바뀌는 대참사가 날 수 있다.
DELETE
Delete, 삭제.
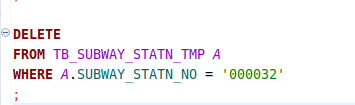
delete는 select와 비슷하게 구문을 작성한다.
from을 통해 어떤 테이블에서 삭제를 할지 정한다.
SELECT
Read, 조회에 해당한다.
가장 중요한 구문해서 뒤로 뺐다.
이걸 얼마나 잘 쓰냐에 데이터를 꺼내오는 시간이 달라지는 것이다.
이것은 단순히 조회하는 것이기에, 데이터에 조작을 가하지는 않는다.
기본적으로는 select 컬럼 from 테이블 형태를 가지고 있고, 여기에 다양한 추가 조건을 넣을 수 있다.
SELECT [ALL | DISTINCT] 컬럼명 [,컬럼명...]
FROM 테이블명 [,테이블명...]
WHERE 조건식
GROUP BY 컬럼명[,컬럼명...]
HAVING 조건식
ORDER BY 컬럼명[,컬럼명...]
LIMIT 숫자
기본적으로 이렇게 작성한다.
여기에서 필수로 들어가는 예약어는 select, from까지고, 나머지는 선택이다.
select * from dual; 간단하게는 이런 식으로도 작성할 수 있다는 말이다.
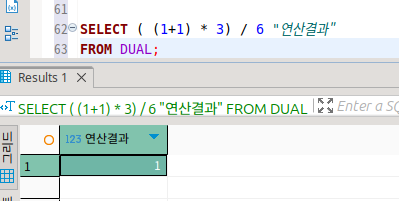
오라클에는 dual이라는 X라는 컬럼 하나에 행도 하나인 껍데기 테이블이 있다.
이걸 이용해서 select를 수행하여 각종 연산을 수행할 수 있다.
행이 있는 테이블보다 작기에 from의 부하가 적어서 사용하기 좋다.
쿼리 실행 순서
select 문에는 딱 봐도 많은 절(예약어)들이 들어갈 수 있는데, 실제 이 쿼리가 발생하면 어떤 순서로 쿼리문이 읽히게 되는가?
이걸 알아야 쿼리를 쓸 때 실수하는 일이 적다.
가령 아래에서 볼 별칭을 쓸 때 실행 순서에 맞지 않게 별칭을 쓴다면 쿼리는 오류가 발생한다.
이러한 순서를 따른다.
from - where - group by - having - select - order by - limit
익숙해지면 당연한 순서이긴 하다.
일단 테이블을 불러오는 from, 이후에는 조건을 걸고 집계를 하며 어떤 것들을 보여줘야 하는지 구체화 시킨다.
이후에 실제로 보여줄 데이터를 보여주는데, 이때 정렬이나 보여줄 개수 지정을 해준다.
그럼 이제 본격적으로 각 절에 대한 세부 설명을 해보겠다.
SELECT절
컬럼 부분에 *를 넣어주면 모든 컬럼을 출력한다.
DISTINCT
이제부터는 select에 같이 쓰는 각종 예약어들을 보자.
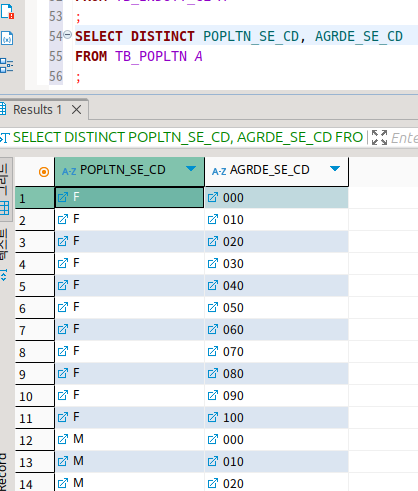
select 바로 뒤에 distinct를 작성하면 중복행을 제거해서 출력한다.
이때 출력할 행들을 전부 참고해서 중복을 따지기 때문에 첫 컬럼은 중복이 보인다.
반대로 말하자면, 유일성이 보장된 컬럼을 포함해서 출력을 진행하는 경우에는 무조건 모든 행이 다 보이게 된다는 말이다.
아, 그래도 null에 대해서는 중복을 제거할 것 같다.
FROM절
테이블을 지정하는 절.
여러 개의 테이블을 지정할 수 있다.
또한 여기에서 조인을 걸어서 테이블을 결합하는 방법도 존재한다.
서브 쿼리도 가능하다!
WHERE절
원하는 조건에 맞춰 데이터를 걸러내기 위한 절.
여러 연산자를 활용해서 조건을 걸 수 있다.
이건 select하고만 쓰이는 게 아니라 update, delete에서도 쓰이기는 한다.
다만 여기에서 가장 많이 쓴다고 확언할 수 있기에 여기에서 다룬다.
GROUP BY절
특정 컬럼을 기준으로 집합을 그룹화한다.
이때 where절이 있으면 먼저 실행되는데, 이때문에 집계함수는 where 절에서 쓰일 수 없다.
이렇게 where가 이뤄진 후, 그룹화된 후에 집계가 적용된다.
그룹 함수
그룹 함수는 특정 집합의 소계, 중계, 합계, 총합계를 구하는 함수다.
SQL 함수이기는 한데, group by에서만 쓰이는 특수 함수인 관계로 여기에 정리한다.
이렇게 부르니까 사실 SQL 함수#집계 함수들이랑 헷갈리는데, 용어를 잘 구분해서 정리하는 게 좋을 것 같다.
원래는 합계를 구할 때 쿼리를 귀찮게 날려야 하는데, 이걸 조금 간소화시켜주는 친구들이라 보면 되겠다.
기본적으로 group by 절에서 사용하는데, 이 자체를 연산자라고 부르는 것 같다.
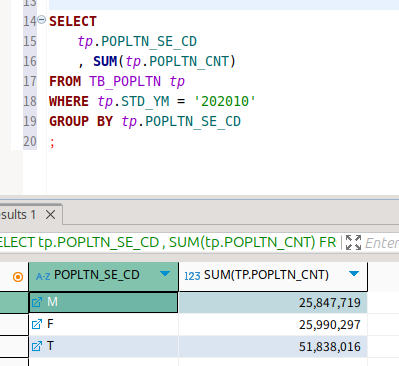
이 친구가 예시로 들 쿼리이다.
연령대별 인구 합계를 보여주고 있다.
rollup
소그룹 간의 소계를 내는 기능이다.
인자로 지정된 칼럼의 소계를 낸다.
그룹화 컬럼의 수가 n개면 n+1개의 소계가 만들어진다.
인자 순서에 따라 결과 역시 달라진다
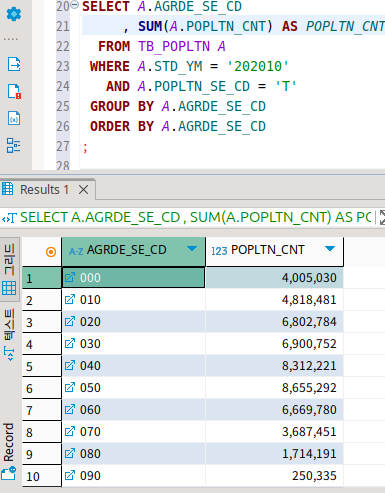
rollup을 하니 한 칸이 더 생겨서 총합이 나오는 것이 보인다.
즉, group by가 된 곳에 집계 함수에 소계를 내어준다는 것이다.
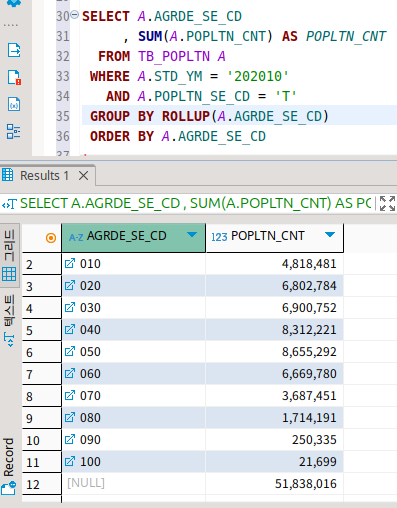
이렇게 하면 두번 group by가 일어나고, 단위마다 순서대로 소계가 나온다.
또한 마지막에 총계가 나온 것이 보인다.
현재 쿼리의 의미대로 해석해보자면, 일단 group by 된대로 연령대별로, 성별로 나눈 후에 기본적인 합계가 나왔다.
이후 먼저 작성된 연령대 별로 소계를 내고, 전체 합계를 냈다.
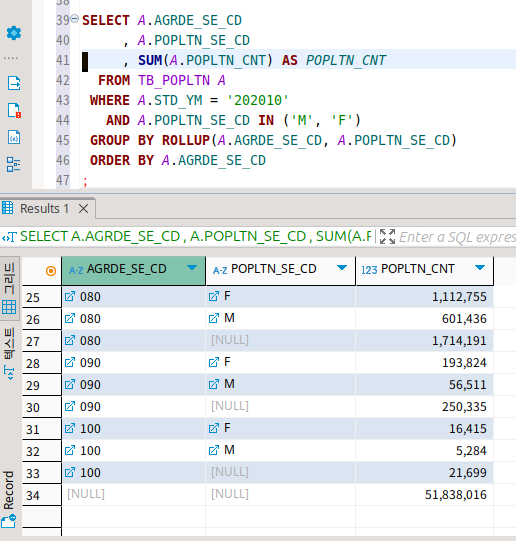
SELECT CASE WHEN GROUPING(A.AGRDE_SE_CD) = 0
THEN A.AGRDE_SE_CD
ELSE '전체합계' END AS AGRDE_SE_CD
, CASE WHEN GROUPING(A.POPLTN_SE_CD) = 0
THEN A.POPLTN_SE_CD
ELSE '연령대별합계' END AS POPLTN_SE_CD
, SUM(A.POPLTN_CNT) AS POPLTN_CNT
FROM TB_POPLTN A
WHERE A.STD_YM = '202010'
AND A.POPLTN_SE_CD IN ('M', 'F')
GROUP BY ROLLUP(A.AGRDE_SE_CD, A.POPLTN_SE_CD)
ORDER BY A.AGRDE_SE_CD
;
grouping이라는 인라인 함수가 존재한다.
이렇게 하면 위의 결과에 null이 나온 부분에 텍스트를 넣어줄 수 있다.
이것은 해당 행이 그룹함수로 인해서 빈칸이 담기는 행일 때 1을 출력한다.
그래서 이걸로 소계에 대한 추가 정보를 제공해줄 수 있다.
cube
다차원 소계를 진행한다.
결합 가능한 모든 값에 대해 집계를 진행한다.
그렇기에 cube 내 컬럼이 n개면 2의 n승 개의 소계가 생성된다.
말만 들어도 엄청난 부하.
SELECT CASE WHEN GROUPING_AGRDE_SE_CD = 1 AND GROUPING_POPLTN_SE_CD = 1
THEN '전체합계'
WHEN GROUPING_AGRDE_SE_CD = 1 AND GROUPING_POPLTN_SE_CD = 0
THEN '연령대별합계'
WHEN GROUPING_AGRDE_SE_CD = 0 AND GROUPING_POPLTN_SE_CD = 1
THEN '성별합계'
WHEN GROUPING_AGRDE_SE_CD = 0 AND GROUPING_POPLTN_SE_CD = 0
THEN '연령대+성별합계' ELSE '' END AS 합계구분
, NVL(AGRDE_SE_CD, '연령대합계') AS AGRDE_SE_CD
, NVL(POPLTN_SE_CD, '성별합계') AS POPLTN_SE_CD
, POPLTN_CNT
FROM
(
SELECT A.AGRDE_SE_CD
, GROUPING(A.AGRDE_SE_CD) AS GROUPING_AGRDE_SE_CD
, A.POPLTN_SE_CD
, GROUPING(A.POPLTN_SE_CD) AS GROUPING_POPLTN_SE_CD
, SUM(A.POPLTN_CNT) AS POPLTN_CNT
FROM TB_POPLTN A
WHERE A.STD_YM = '202010'
AND A.POPLTN_SE_CD IN ('M', 'F')
GROUP BY CUBE(A.AGRDE_SE_CD, A.POPLTN_SE_CD)
ORDER BY A.AGRDE_SE_CD
) A
;
이 쿼리는 인라인 뷰가 핵심 쿼리이다.
근데 이렇게 보면 결과를 보기 어려워서 이런 식으로..
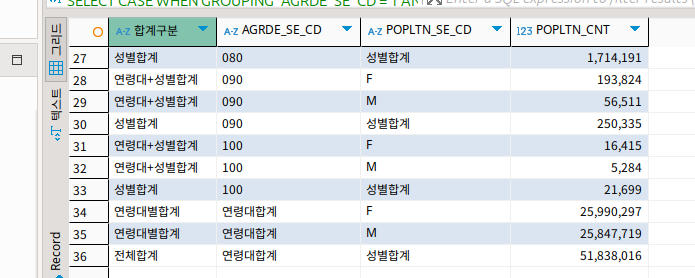
결과는 대충 이런 식으로 나온다.
말 그대로 모든 집계가 나왔다.
일단 group by가 보내는 결과인 연령대와 성별을 합친 합계가 나왔다.
이후에 연령대별로의 합계가 나왔고, 이후에는 성별로 또 합계를 나누어서 합계가 나왔다.
마지막으로 그냥 전체 합계가 나왔다.
grouping sets
특정 항목에 대한 소계를 계산한다.
내가 원하는 놈들을 지정할 수 있게 해준다.
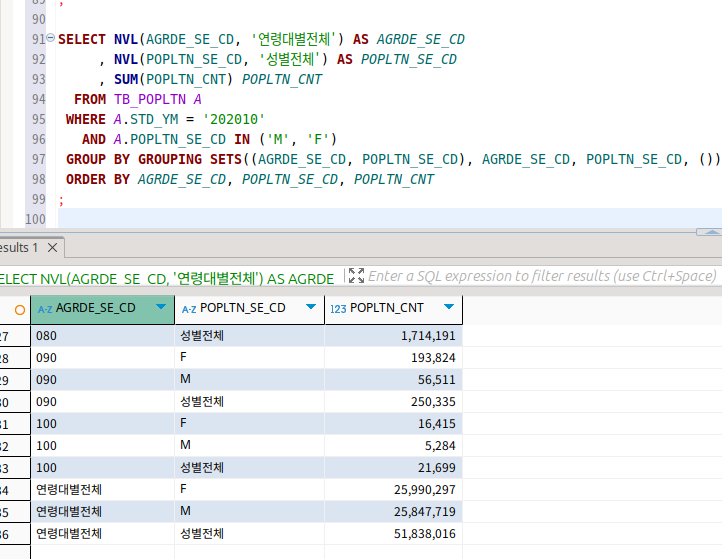
아까와 같은 결과를 내고 있는 쿼리문이다.
group by에 내가 소계를 내고 싶은 놈들을 아예 명시를 해버린 것이 보인다.
()는 전체에 대한 소계를 나타낸다.
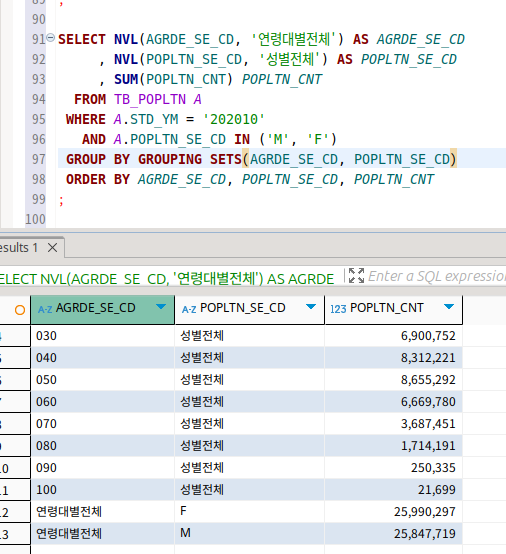
보다시피 sets 안 속에 들어간 녀석들에 대해서 각각 소계가 나온 것이 보인다.
이것은 union을 이용해서 표현할 수도 있다.
사실 그룹함수가 다 그렇다.
그런데 이것을 편하게 만들어주는 함수가 바로 그룹함수라는 것을 기억하면 된다.
HAVING절
그룹화된 이후에 조건을 걸고 싶을 때는 having을 사용한다.
where에는 집계함수가 들어갈 수 없지만, 여기에는 들어갈 수 있다.
가령 위의 예시에서 sum의 값이 얼마 이상인 것만 조회하고 싶다면 having이 제격이다.
일반적으로는 group by 아래에 나오지만, 순서는 사실 위에 나와도 된다고 한다.
또한 무조건 group by가 있어야만 쓸 수 있는 것도 아니다.
조건을 걸기는 거는데 집계를 통해서 걸고 싶은 것이 있다면 사용하는 것이다.
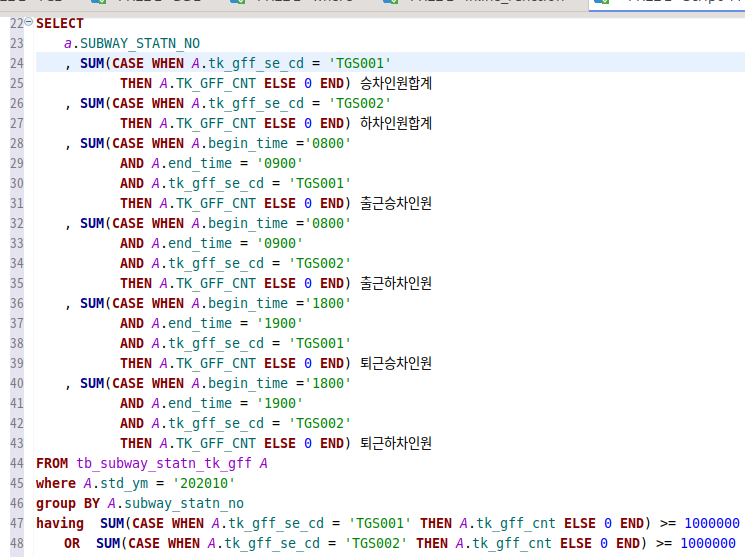
이를 응용해서 어렵게 쿼리문을 만들었다.
이건 출퇴근 시간 따라 승차 하차 인원을 구한 스크립트이다.
이것을 통해 어떤 역에 사람이 출퇴근 시간에 유동이 많은지 파악할 수 있다.
출근 시간에는 승차, 퇴근 시간에는 하차가 많은 지역이라면 거주지가 많은 동네일 것이다.
ORDER BY절
정렬을 위한 절.
이것은 select 뒤에 실행되기에 select에서 정한 별칭을 사용할 수 있다.
기본은 오름차순, asc로 되어 있으며 거꾸로 하고 싶다면 desc를 적으면 된다.
오라클을 기준으로 null을 가장 큰 값으로 간주해 일반 정렬 시 null은 마지막에 위치하게 된다.
이건 따로 실습하지 않겠다.
한가지 알아둬야 할 것은 있다.
원래는 select에 없는 칼럼을 기준으로 정렬하는 게 가능하다.
그러나 만약 group by를 사용했다면 반드시 정렬 기준은 select에 있어야 한다.
LIMIT절
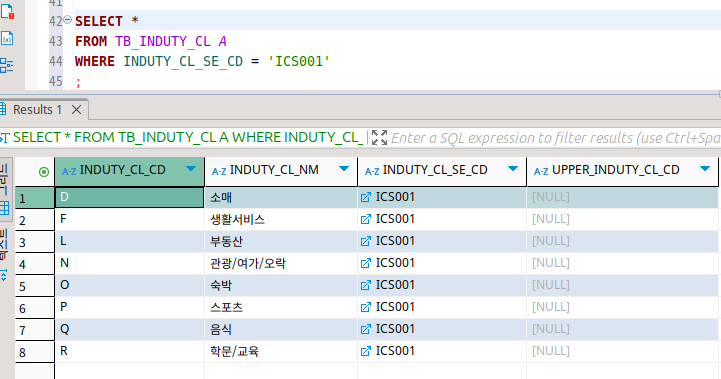
별칭(alias)
AS를 이용해 별칭을 지정할 수 있다.
이걸 넣지 않고 그냥 띄어쓰기만 해도 별칭으로 작용하긴 한다.
오우야.
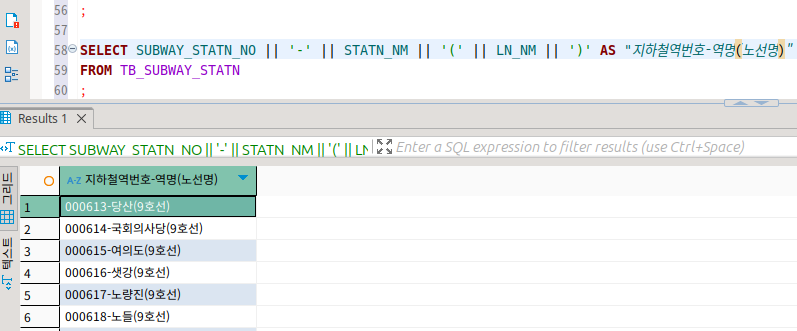
||를 이용해서 컬럼들을 합쳐표현하는 것도 가능하다!
concat을 쉽게 사용하는 방법인 듯.
ROWNUM
예약어를 따로 정리해야 하나 하다가, 일단 select하고 연관이 깊어서 이쪽에 정리한다.
이것은 특정 테이블에서 데이터가 조회될 때 출력되는 순번을 나타내는 가상의 칼럼이다.
이걸로 출력 행 수를 제한할 수도 있다.
수백만 행이 담긴 테이블에서는 조금씩 데이터를 꺼내는 게 아무래도 나은 것이다.
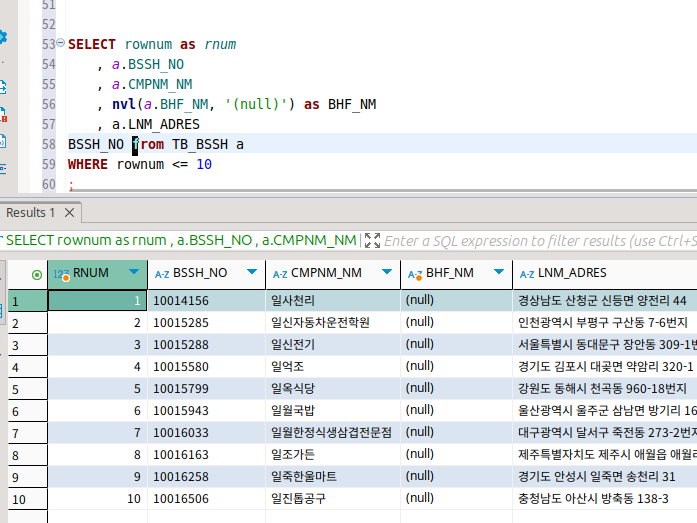
사실 limit으로도 할 수 있긴 한데.. 그래도 이걸 오라클에서는 자주 쓴다고 한다.
일단 과거에는 limit이란 게 없어서 과거와의 호환성을 위해 쓴다.
그리고 limit은 다 불러온 뒤에 자르는데 이놈은 미리 자르고 가져오는 모양이다.
참고로 order by까지 다 되고 붙는 칼럼이라 order by에 당연히 넣을 수 없다.