옵티마이저
개요
옵티마이저는 사용자의 sql문의 최적 실행 방법을 결정하는 역할을 한다.
이러한 실행 방법은 실행계획이라 부른다.
룰 기반, 비용 기반의 두 가지 방법이 있으나 실질적으로는 후자만 사용된다.
비용 기반은 dbms 객체 정보, 통계 정보를 활용해 비용이 적게 드는 방법을 선택하는 것이다.
테이블, 인덱스 등의 정보를 통해 산출된다.
가령, 테이블을 전체를 따지는 것보다는 인덱스를 이용해 스캔하는 게 이득이라면 알아서 그쪽으로 선택한다는 것.
구성요소
구체적으로는 3가지의 구성 요소를 순서대로 거친다.
- 질의 변환기
- 사용자의 sql문을 처리하기 용이한 형태로 변환
- 비용 예측기
- 여러 실행 계획들의 비용을 예측
- 연산의 중간 집합 크기, 결과 집합 크기나 분포도를 예측한다.
- 즉, 정확한 통계 정보가 요구된다.
- 이를 위해 데이터 딕셔너리가 내부적으로 존재한다.
- 대안계획 생성기
- 동일한 결과를 생성하는 다양한 실행계획을 생성
- 연산 적용 순서, 방법 변경, 조인 순서 등이 다른 계획들을 만든다.
- 이 중에서 최적을 선택하면 최적화 완료!
사용 정보
결국 가장 중요한 것은 옵티마이저가 어떤 정보를 활용하는가, 이것이다.
다음의 정보들을 활용한다.
- 테이블, 칼럼, 인덱스 구조에 대한 기본 정보
- 오브젝트 통계
- 테이블, 인덱스, 히스토그램
- 시스템
- cpu 속도, 단일 블록 I/O 속도, 다중 블록 I/O 속도
- 옵티마이저 관련 파라미터
실습
이것 역시 간단해 따로 토픽으로 분류하지 않는다.
sqlplus sqld/1234
set autotrace traceonly explain;
SELECT A.ADSTRD_CD
, A.STD_YM
, A.POPLTN_SE_CD
, A.AGRDE_SE_CD
, A.POPLTN_CNT
, B.ADSTRD_NM
FROM TB_POPLTN A
, TB_ADSTRD B
WHERE A.ADSTRD_CD = B.ADSTRD_CD
AND A.ADSTRD_CD = '1154551000' --서울특별시 금천구 가산동
;
위의 설정을 넣어주면 실행계획이 출력된다.
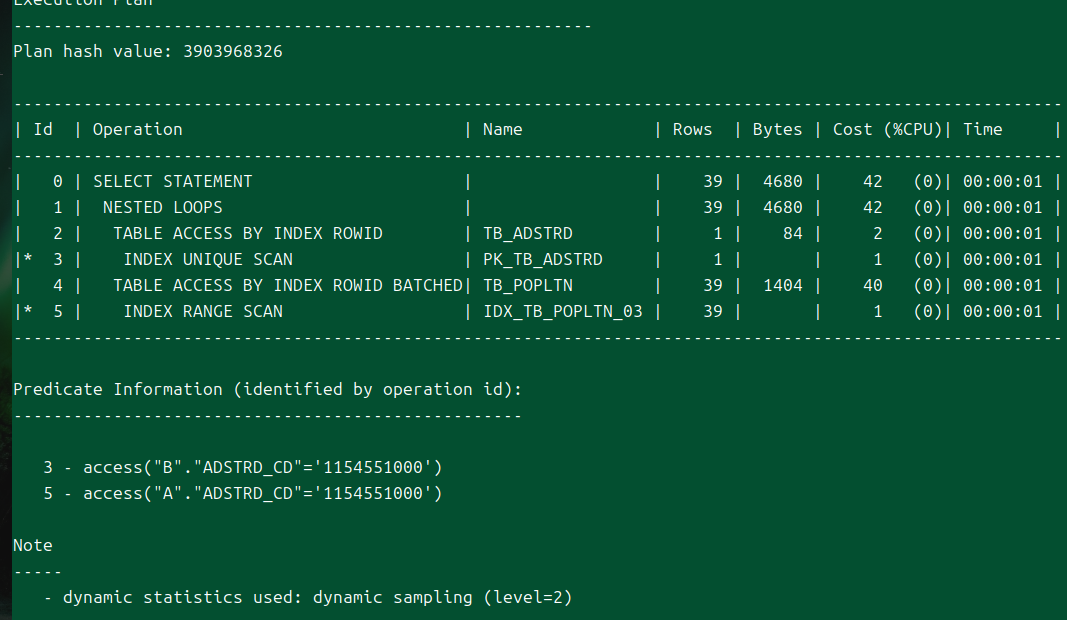
이렇게 말이다.
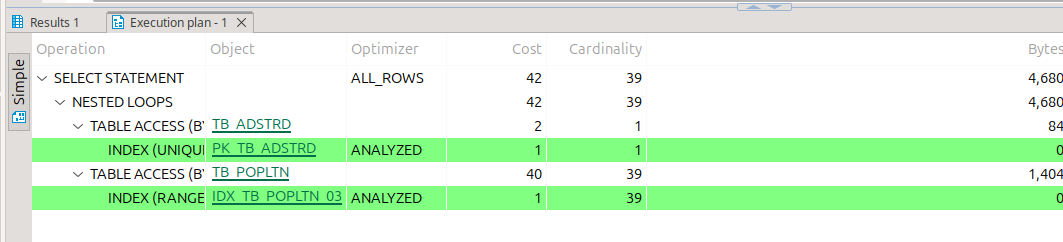
dbeaver에서는 실행계획 보기를 누르거나, shift+ctrl+e를 누르면 된다.
이것은 실제 실행계획을 나타내는 것으로 옵티마이저가 최종적으로 선택한 값이다.
의미로만 해석을 해보자면, 일단 두가지 테이블에 액세스했다.
긜고 그곳에서 인덱스 레인지 스캔과, 유니크 스캔을 했다.
결과로는 한 건, 39건이 나왔는데 이것에 대해 루프를 돌면서 작업을 수행하여 출력했다.
유니크 스캔을 할 수 있었던 건 기본키였기 때문.
이건 실행을 어떻게 할 것인지에 대한 계획이고, 이미 실행된 것에 대한 내역도 확인해볼 방법이 있다.
ALTER SESSION SET STATISTICS_LEVEL = ALL;
SELECT /* SELECT.TB_POPLTN.TB_ADSTRD.001 */
A.ADSTRD_CD
, A.STD_YM
, A.POPLTN_SE_CD
, A.AGRDE_SE_CD
, A.POPLTN_CNT
, B.ADSTRD_NM
FROM TB_POPLTN A
, TB_ADSTRD B
WHERE A.ADSTRD_CD = B.ADSTRD_CD
AND A.ADSTRD_CD = '1154551000' --서울특별시 금천구 가산동
;
--코드 7-3 SQL문의 실행 정보 조회
SELECT SQL_ID
, CHILD_NUMBER
, SUBSTR(SQL_FULLTEXT, 1, 40)
FROM V$SQL
WHERE SQL_FULLTEXT LIKE '%SELECT.TB_POPLTN.TB_ADSTRD.001%'
AND SQL_FULLTEXT NOT LIKE '%V$SQL%'
;
--실행내역 출력
SELECT *
FROM TABLE (DBMS_XPLAN.DISPLAY_CURSOR('bjbwq79yht5nn',0,'ALLSTATS LAST -ROWS'))
;
일단 세션의 통계 정보를 all로 해서 모든 통계가 추적되도록 한다.
그리고 쿼리문에 주석을 달아서 내가 조회하고픈 쿼리가 어떤 놈인지 잘 보이게 만들어준다.
(당연히 없어도 되긴 한다)
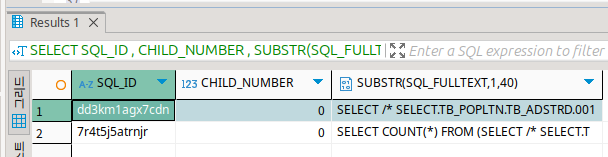
그리고는 V$SQL에서 실행된 쿼리문을 확인한다.
이것은 DBMS에서 관리하는 쿼리 정보를 담는 뷰이다.
여기에서 sql_id를 이용해서 마지막 쿼리는 날려주면 된다.
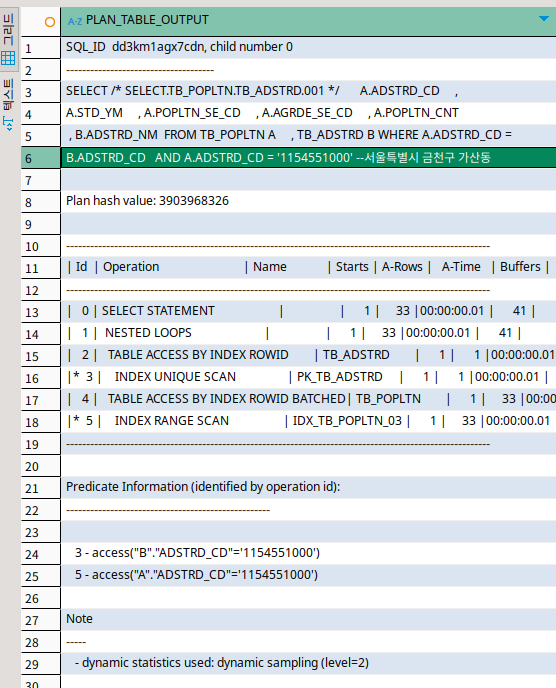
마지막 쿼리에서 세번째 인자는 어떻게 출력할 것인지에 대한 인자이다.
그러면 짜장!
이전 쿼리에 대해서 또 실행 내역이 확인된다.
아까는 실행 계획이었기에 예상되는 값들에 대한 정보였으나, 여기는 실제로 읽은 줄과 실행시간에 대한 정보가 담기게 된다.
name 부분을 보면 어떤 테이블이나 키를 썼는지 나온다.
구체적인 실행 순서는 DFS와 같다.
가장 아래까지 들어가고, 거기에서부터 위로 나온다.
루프가 일어나는 것은 둘을 잇는 조인 연산 때문이다.
첫번째 테이블을 기준으로 반복하게 된다고 한다.
첫번째에서 한 행이 조회됐으므로, 루프는 한번이다.
그래서 조인할 때 순서가 중요한 것이다..