인덱스
개요
인덱스는 원하는 데이터를 빠르게 찾을 수 있도록 마련된 별도의 자료구조이다.
인덱스 설정을 하면 설정된 컬럼을 기준으로 정렬한 후, 그 컬럼을 데이터로 담는다.
그러면? 나중에 데이터를 인덱스를 통해 꺼낸다 하면 여기에 저장된 디스크 주소를 보고 바로 데이터를 불러오면 된다는 것이다.
이렇게만 들으면 좋은 것 같지만, 테이블에 삽입이나 삭제가 일어나면 인덱스는 이것들의 정렬 기준에 부합하도록 수정이 일어나야 하기에 추가 연산이 들어간다.
그래서 적당히, 쿼리에 잘 쓰일 것 같은 컬럼에 인덱스를 걸어두는 게 좋다.
B+ 트리
흔한 인덱스 자료구조는 비플 트리이다.
자세한 구조는 다음에 노트를 따로 파겠다.
여러 번 들어봐서 대충 느낌은 아는데 명확하게 말로는 아직 설명하지 못하는 두루뭉술한 상태이다.
실제 sqld에서 나오는 내용까진 아니라 당장의 목표에서 벗어나므로 잠시 미룬다.
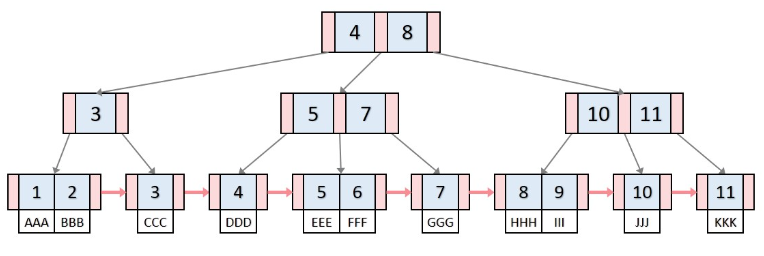
보면 좀 신기하게 생겼다.
빨간 건 포인터 블록인데, 다음 노드의 위치를 가리키는 역할을 한다.
맨 아래, 리프에 해당하는 노드들은 인덱스 설정 때 기준이 된 컬럼의 값들과, 해당 행 번호(rowid)까지 담긴다고 한다.
이 rowid라는 것에 담긴 정보를 통해 디스크의 어디에 정보가 있는지 알 수 있고, 이를 토대로 데이터를 바로 불러올 수 있게 된다는 것이 이 자료구조의 핵심이다.
책에서 이야기 하는 인덱스 구조는 다음과 같다.
- 루트와 브랜치 블룩은 하위 블록에 대한 주소값을 가지고 있다.
- 리프 블록에는 키 값 순으로 정렬되어 있으며, 테이블의 주소값을 가진다.
- 주소로 찾아간 블록에는 이전 블록에서 올 때 참고했던 값보다 작거나 같은 값이 저장돼있다.
- 인덱스 키 값이 같다면 rowid순으로 정렬된다.
사실 rowid가 정확하게 뭘 가지고 있다는 것인지 감이 안 잡혔는데 바로 내용이 나와있다.
- rowid
- 데이터 블록 주소
- 데이터 파일 번호
- 블록 번호
- 데이터 파일 내에서 부여된 상대적 순번
- 로우 번호 - 블록 내에서의 순번
- 데이터 블록 주소
그러니까 데이터 블록의 주소가 있고 그 속에서 로우 번호로 해당 블록 안에서 값을 얻어낸다.
데이터 블록 주소는 데이터 파일 번호가 있는데, 여기에서 또 블록 번호를 통해 구체적으로 어떤 블록인지 특정하게 된다.
인덱스 스캔 효율화
인덱스를 이용해 스캔하는 방법은 where절에 인덱스를 이용한 조건을 넣는 것이다.
정확하게는 조건을 거는 모든 부분에 인덱스 컬럼이 들어가면 활용된다.
가령 group by, order by 등.
(인덱스를 트리 구조를 탐색해 들어가는 과정을 인덱스를 탄다고 흔히 표현한다.)
이때 어떤 식으로 인덱스를 활용하는지는 매우 중요한 최적화 부분 중 하나이다.
where substr(출생, 1,4) = 2000이라고 쓰면 사실 모든 인덱스를 찾게 된다.
where 출생 between 2000.01.01 and 2000.12.31라고 조건을 거는 방식이 유효하다.
인덱스는 컬럼들을 엮어서 만들 수도 있다.
그런데 이때 컬럼의 순서가 스캔 효율성을 좌지우지한다.
카디널리티가 낮은, 즉 도메인의 분포도가 넓은 컬럼일수록 효율이 좋다(표현이 적확한지 모르겠다).
가령 성별은 대체로 두 값밖에 없다.
이런 것보다는 차라리 이름, 그것보다는 주민번호가 스캔 효율이 좋다는 이야기다.
인덱스 스캔 vs 테이블 풀 스캔
또한 간혹 인덱스를 스캔하는 것보다 테이블 풀 스캔을 하는 것이 더 이득인 상황이 존재한다.
인덱스에서 정렬이 되어 있다고 디스크에서 그렇게 저장되어 있진 않기에 실제로는 데이터를 디스크의 순서가 없는, '무작위' 위치들을 불러오게 되는데, 이를 테이블 랜덤 액세스라고 부른다.
사실 이것은 가장 피해야 하는 상황이다.
인덱스를 통해 디스크 블록을 읽을 때는 single block i/o를 사용한다.
이것은 한번의 요청에 하나의 블록을 읽는 것이다.
그러나 dbms는 기본 i/o 콜에서 128개 정도의 블록을 읽는다.
즉, 인근에 위치한 블록을 한꺼번에 읽어들이는 것이다.
당연히 이렇게 스캔을 해버리는 게 하나씩 읽는 것보다 효율적인 상황은 생기기 마련이다.
다음은 책에서 나오는 테이블 풀 스캔과 인덱스 스캔의 비교이다.
- 테이블 풀 스캔
- 일단 테이블을 전부 읽어오고 필요한 놈만 사용
- 이렇게 읽어진 데이터는 메모리 버퍼 캐시에서 금방 제거된다.
- 이러한 스캔이 선택되는 경우
- sql문에 조건이 없는 경우
- 조건이 있어도 사용 가능한 인덱스가 없는 경우
- 옵티마이저가 풀 스캔 때리는 게 낫다고 판단한 경우
- 강제로 sql 힌트를 지정한 경우
- 다중 블록 i/o
- 랜덤 액세스 부하는 일어나지 않는다.
- 인덱스 스캔
- 아까까지 설명한 기본적인 방법
- 참고로 쿼리 문에서 필요한 컬럼이 모두 인덱스로 되어 있다면 sql문은 테이블로 가지 않는다.
- 어차피 인덱스에서 모두 값을 꺼낼 수 있기 때문이다.
- 인덱스 스캔은 인덱스 기준으로 데이터가 정렬된 채로 온다.
- 그러나 진짜 결과 보장을 위해서는 order by 절은 써야 한다.
- 단일 블록 i/o
- 랜덤 액세스 부하가 발생한다.
- 읽은 블록을 또 읽는 비효율도 생긴다.
- 논리적인 i/o 횟수도 늘어난다.
대체로 인덱스 스캔이 좋기는 하다.
근데 아래에서 보게 될 텐데, 생각보다 테이블 스캔이 이득이 되는 경우도 존재한다.
엔지니어로서는 인덱스 스캔의 효율을 높여서, 절대적인 논리적 i/o 자체를 줄이기 위한 고민을 해야 한다.
종류
실습이 많은데, 실습을 해야 잘 이해되는 부분들이라 토픽으로 분류하지 않았다.
인덱스 범위 스캔
인덱스를 통해 1건 이상의 데이터를 추출한다.
CREATE TABLE TB_BSSH_TMP AS
SELECT * FROM TB_BSSH;
ANALYZE TABLE TB_BSSH_TMP COMPUTE STATISTICS;
CREATE INDEX IDX_TB_BSSH_TMP_01 ON TB_BSSH_TMP(ADSTRD_CD);
ANALYZE INDEX IDX_TB_BSSH_TMP_01 ESTIMATE STATISTICS;
ALTER SESSION SET STATISTICS_LEVEL = ALL;
실습을 위해 테이블을 복제해서 만든다.
analyze를 통해 통계를 수집할 수 있도록 만든다.
이후에는 인덱스를 만들고, 해당 인덱스에 대한 통계도 수집한다.
그리고 통계를 보이는 레벨을 all로 설정한다.
SELECT /* SELECT.TB_BSSH_TMP.001 */
A.BSSH_NO
, A.CMPNM_NM
, A.INDUTY_SMALL_CL_CD
, A.ADSTRD_CD
, A.LNM_ADRES
, A.NW_ZIP
, A.LO
, A.LA
FROM TB_BSSH_TMP A
WHERE A.ADSTRD_CD = '4128157000' --경기도 고양시 덕양구 삼송동
ORDER BY A.ADSTRD_CD
;
만든 인덱스를 조건절에 넣고 쿼리를 날린다.

쿼리를 날리고 해당 내역을 확인할 수는 있다.
그냥 실행계획을 보기로 했다.
해당 인덱스는 유일한 값은 아니라, 해당 것을 토대로 범위 스캔을 때린다.
유일성이 보장된 인덱스더라도 범위로 조건을 넣어주면 이렇게 진행될 것이다.
인덱스 유일 스캔

유일한 값에 대해서 =를 이용하면 유니크 스캔이라 부른다.
인덱스 풀 스캔
테이블 풀 스캔을 하듯이, 인덱스를 풀 스캔하는 경우도 존재한다.
SELECT /*+ INDEX(A IDX_TB_SUBWAY_STATN_TK_GFF_TMP_02) */
/* SELECT.TB_SUBWAY_STATN_TK_GFF_TMP.003 */
A.STD_YM
, A.BEGIN_TIME
FROM TB_SUBWAY_STATN_TK_GFF_TMP A
WHERE A.BEGIN_TIME >= '0200'
ORDER BY A.STD_YM
;
위의 쿼리는 sql 힌트를 넣어서 풀스캔을 유도했다.
해보니까 힌트를 넣지 않아도 풀 스캔을 하긴 하더라.
근데 이렇게 하지 않으면 아래에서 볼 인덱스 패스트 풀 스캔을 때릴 가능성이 있다고 한다.
그건 시스템의 상황과 옵티마이저의 선택에 달린 것이라, 안전하게 풀스캔을 때리라고 힌트를 넣어주었다.

이렇게 풀스캔이 일어난다.
기본적으로 이럴 때 dbms는 풀스캔을 하려고 한다고 한다.
전부 여기에 담지는 않았으나, 이번에는 order by 절에 들어가는 컬럼과 where절에 들어가는 컬럼이 키가 되었다.
이때 값을 다 가져온 후에 정렬하는 작업을 비효율이라 판단하는 옵티마이저의 판단에 따라 처음부터 인덱스로 모든 값을 불러와버린다는 것이다.
그냥 테이블을 불러오는 것보다야 낫겠지만, 결국 전부 읽는 것은 그렇게 효율적인 작업은 아니다.
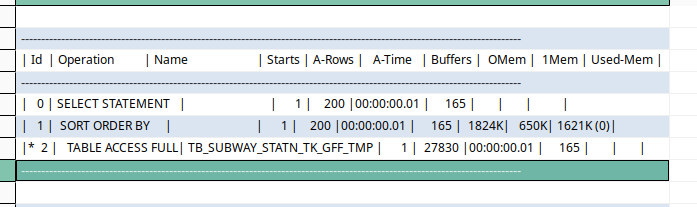
위의 쿼리는 사용하는 컬럼이 인덱스 값이라 저렇게 됐는데, 그냥 전체 컬럼을 뽑으라 하니 테이블 풀스캔을 하는 것이 보인다.
생각보다.. 실행시간에서는 눈에 보이는 차이까지는 없네.
아무튼 옵티마이저는 여기에서 인덱스를 이용하지 않았다 .


실행 코스트에 대한 예상값에서는 차이가 있긴 하다.
왜 갑자기 테이블 스캔을 때렸을까, 제대로 된 인덱스가 없어서?
일까 싶어 명확하게 전체 인덱스 컬럼을 조건절에 넣었으나 이번에도 테이블 스캔을 때렸다.
내 생각에는 이렇다.
어차피 인덱스 풀 스캔을 해야 하는 게 이득이라 옵티마이저는 판단한다.
근데 그 상태에서 모든 컬럼을 꺼내라 하니, 결국 모든 행을 조회해야 한다는 것도 알기 때문에 그냥 처음부터 테이블 스캔을 때리고, 그 다음에 정렬을 진행하는 것이다.
이전에는 인덱스 풀 스캔만 때려도 원하는 값들을 출력할 수 있었으니 테이블까지 갈 필요가 없어서 그리 했을 뿐이다.
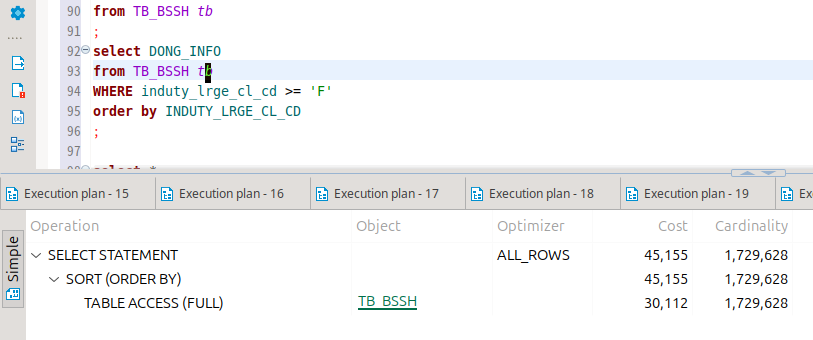
라고 생각하고 데이터가 이빠이 많은 테이블에도 똑같은 짓을 해봤다.
지피티 왈, 데이터가 적은 테이블이라면 그냥 풀스캔을 때리기도 한다고 했다.
다양한 상황이 나왔다.
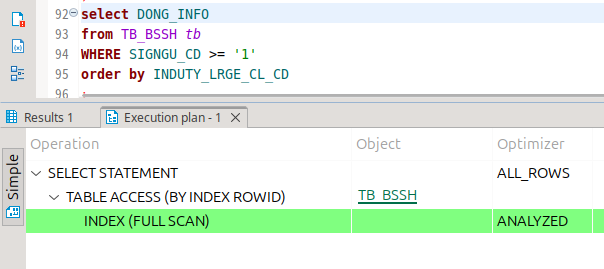
일단 인덱스에 해당하는 컬럼이면 대체로 레인지 스캔을 하더라.
근데 이런 식으로, 컬럼 한 놈은 where에 박고 한 놈은 order by에 박을 때 인덱스 풀 스캔을 때렸다.
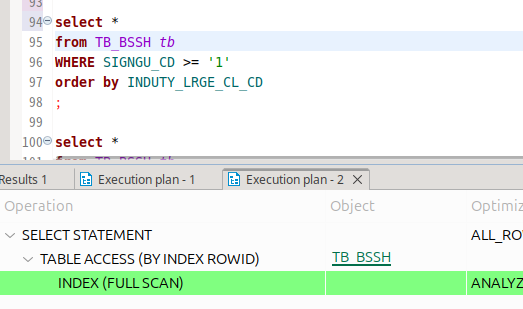
아까처럼 그냥 전체 컬럼 꺼내라고 협박했는데 이번에는 인덱스 풀스캔을 했다.
테이블 풀스캔을 때린 명백히 다른 상황이다.
지피티 선생님의 말에 조금 힘이 실렸다.
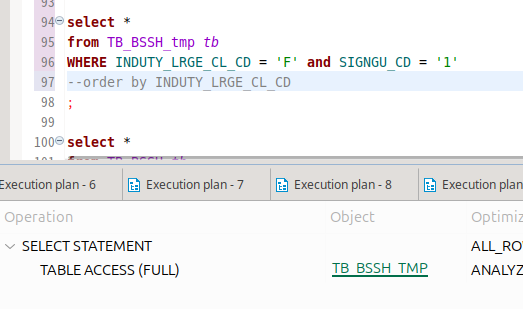
하지만 명확하지는 않다.
일단 위의 테이블을 내가 생각한 놈과 다르게 설정했다.
다시 내가 원하는 놈으로 진행해봤는데, 이번에는 테이블풀스캔을 때렸다.
음.. 다른 때에 해보니까 이번에는 인덱스풀스캔을 때렸다.
와. 이거 생각 이상으로 사람이 가늠하기 어려운 영역인 것 같다.
아직 내공이 부족해서 어떻게 해야 명확하게 테이블 스캔이 되고, 인덱스 풀 스캔이 되고를 모르겠다.
조금 더 깊게 공부할 시간을 가지긴 해야 할 것 같다.
인덱스 스킵 스캔
이것은 인덱스가 여러 개로 만들어졌을 때, 인덱스의 선두 컬럼이 조건절에 없어도 해당 인덱스를 활용하는 스캔이다.
인덱스는 선행, 이후에 후행 순으로 정렬이 된다.
이때 인덱스를 쓰기는 쓰는데 후행만 쓰고 싶다면 어떤 모양이 될까?
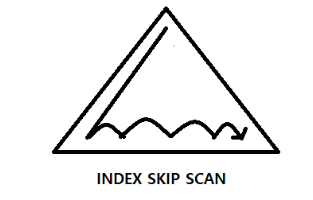
대충 이런 식으로 된다.
리프로 내려가서, 후행 컬럼을 기준으로 꺼내고자 하는 블록들만 점프해가며 값을 불러온다는 것이다.
정렬의 큰 기준은 선행 컬럼인데 해당 컬럼을 무시하는 방식의 절차인 격이다.
선두 컬럼이 도메인이 작고, 후행이 크다면 유용하다고 한다.
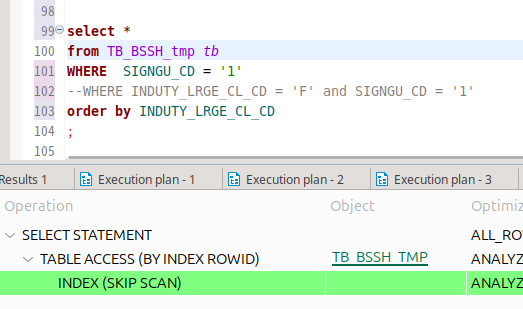
이런 상황에서 스킵 스캔이 나온다.
order by 절에 들어간 놈이 선행 컬럼인데, 값이 d, g, b, f 정도밖에 없다.
당연히 order by 절이 없어도 스킵 스캔이 실행된다.
인덱스 고속 풀 스캔
인덱스 풀 스캔을 때리기는 하는데, 단일 블록 i/o가 아니라 다중 블록 i/o를 시전한다.
또는 여러 프로세스를 돌려 병렬적으로 인덱스 스캔을 실행한다.
인덱스 풀 스캔으로 리프 블록들을 불러오긴 해야 하는데, 정렬되지 않은 채로 빨리 불러오고자 할 때 사용된다고 한다.
그러니 order by 절에 인덱스 값이 없으면 잘 일어난다.
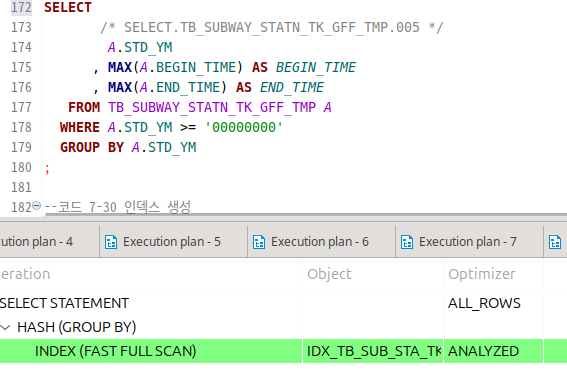
솔직히 책의 예제는 전부 sql 힌트로 하는 식이라 너무 짜친다..
그래도 힌트 없애고 해도 의도대로 나오긴 하니 넘어갑시다.
사용되는 컬럼들은 전부 인덱스에 있어 테이블로 가지는 않았다.
그 상태에서 인덱스로 스캔을 하려니 조건에 인덱스 전체가 없어 결국 인덱스 풀 스캔을 해야 하는 상황.
근데 정렬 기준따위도 없는 그룹바이를 시전한다.
그러니 그냥 일단 리프 블록들을 한땀한땀 읽는 게 아니라 다중으로 확 읽어버린다.
인덱스 역순 범위 스캔
인덱스 리프 블록은 이중 연결 리스트 구조로 되어있다.
그래서 거꾸로 읽어서 정렬되게 하고 싶을 때, 사용된다.
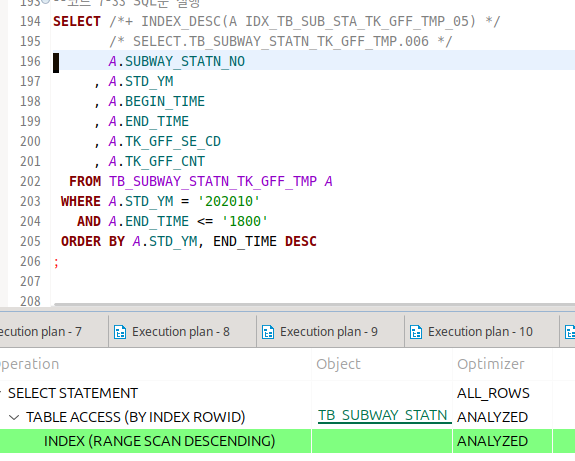
이번엔 힌트 없애니까 그냥 테이블 풀 스캔 때리는데..?
음..왜..?
인덱스 불러와서 읽는 게.. 나은 게 아니야..?
하 아직 감이 잘 안 온다..
암튼 내가 너무 함부로 판단하려 드는 것 같긴 하다.