조인
개요
테이블을 합치는 연산.
흔히 집합으로 표현되고는 하는데, 이는 관계형 대수 이론에 근거하고 있다.
정규화가 진행된 테이블에는 필연적으로 조인을 사용하게 된다.
종류
당시 S-오라클 600 에러 트러블 슈팅(한글 인코딩) 이러한 에러가 발생하여 제대로 실습을 진행하며 정리하지는 못 했다.
이후에 또 기회가 된다면, 그때 조금 더 제대로 해볼까 한다.
INNER JOIN(EQUI JOIN)
join 조건에 동일한 값이 있는 행만 반환한다.
동등(equi) 조인이라고도 한다.
가장 일반적인 방식이라, join할 때 따로 앞에 뭘 안써주면 그냥 inner join으로 실행된다.
from에 두 테이블을 명시하고, where 절에서 = 조건을 넣는다.
이건 흔히 오라클에서 사용되는 조인 방식이다.
흔히 join을 명시하고 어떤 조건으로 매칭을 할지 on 조건절을 써준다.
이러한 방식을 ANSI 표준 방식이라 부른다.
근데 조금 더 직관적으로 보기 위해 join이란 연산자가 만들어지고 join 조건을 on으로 명시하는 게 생긴 것이다.
여기에서는 별칭을 쓰지 않으면 에러가 발생한다.
어떤 컬럼이 어떤 놈의 것인지 모르기 때문이다.
using 조건절을 통해 쓰는 방법도 있다.
이건 on 조건절에서 A = B 정도에 해당하는 의미이며 간략한 작성이 가능하다.
이때 using 안에는 별칭을 붙일 수 없다고 한다.
어차피 둘 다 존재하는 컬럼을 써야 하니 그렇게 제한을 거는 게 자연스러운 것 같기도 하다.
NATURAL JOIN
위에서 본 내츄럴 조인 개념과 같은 개념이긴 한 것 같은데..
표현은 명확하게 모르겠다.
아무튼 이건 조건을 걸지 않고 조인을 하는 형태이다.
알아서 서로 일치하는 칼럼을 찾고, 이를 토대로 이너 조인을 진행한다.
반대로 말하면 최소한 하나의 일치하는 컬럼이 존재해야만 한다.
단순하게 말하자면, 그냥 매칭되는 컬럼을 전부 기준으로 잡는 이너 조인이긴 하다.
create table tb_dept_6_1_6
(
dept_cd char(4)
, dept_nm varchar2(50)
, constraint pk_tb_dept_6_1_6 primary key(dept_cd)
);
insert into tp_dept_6_1_6 (dept_cd, dept_nm) values ('D001', '데이터팀');
insert into tp_dept_6_1_6 (dept_cd, dept_nm) values ('D002', '영업팀');
insert into tp_dept_6_1_6 (dept_cd, dept_nm) values ('D003', 'IT개발팀');
commit;
create table tb_emp_6_1_6
(
emp_no char(4)
, emp_nm varchar2(50)
, dept_cd char(4)
, dept_nm varchar2(50)
, constraint pk_tb_emb_6_1_6 primary key(emp_no)
);
insert into tp_emp_6_1_6 (emp_no, emp_nm, dept_cd) values ('E001', '이경오', 'D001');
insert into tp_emp_6_1_6 (emp_no, emp_nm, dept_cd) values ('E002', '이수지', 'D001');
insert into tp_emp_6_1_6 (emp_no, emp_nm, dept_cd) values ('E003', '김영업', 'D002');
insert into tp_emp_6_1_6 (emp_no, emp_nm, dept_cd) values ('E004', '박영업', 'D002');
insert into tp_emp_6_1_6 (emp_no, emp_nm, dept_cd) values ('E005', '최개발', 'D003');
insert into tp_emp_6_1_6 (emp_no, emp_nm, dept_cd) values ('E006', '정개발', 'D003');
commit;
alter table tm_emp_6_1_6
add constraint fk_tb_emp_6_1_6 foreign key (dept_cd)
references tb_dept_6_1_6(dept_cd);
간단한 실습 테이블을 만든다.
SELECT DEPT_CD
, A.DEPT_NM
, B.EMP_NO
, B.EMP_NM
FROM TB_DEPT_6_1_6 A NATURAL JOIN TB_EMP_6_1_6 B
ORDER BY DEPT_CD
;
natural join이라고 명시를 해주는데, 이렇게 하면 일반 inner join과 동일하게 작동한다는 것.
근데 natural join할 때는 별칭을 사용할 수 없다고 하던데, 버전 차이가 이런 문제를 낳는 것이려나.
이때 동일한 컬럼이 두 개 존재한다면 그 모두를 활용하게 된다.
자연 조인을 할 때 원하는 컬럼만 사용하고 싶다면 using을 명시하면 된다.
근데 어차피 결국 inner join으로 구현가능한 부분이다..
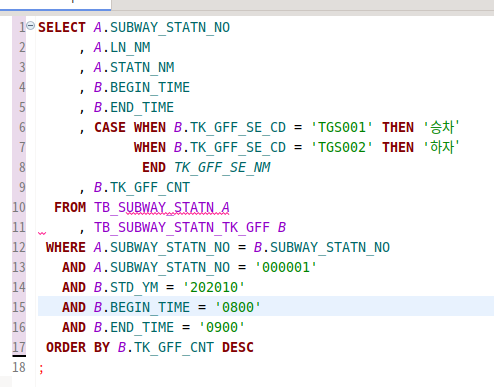
SELECT SUBWAY_STATN_NO
, A.LN_NM
, A.STATN_NM
, B.BEGIN_TIME
, B.END_TIME
, CASE WHEN B.TK_GFF_SE_CD = 'TGS001' THEN '승차'
WHEN B.TK_GFF_SE_CD = 'TGS002' THEN '하차'
END TK_GFF_SE_NM
, B.TK_GFF_CNT
FROM TB_SUBWAY_STATN A JOIN TB_SUBWAY_STATN_TK_GFF B
USING (SUBWAY_STATN_NO)
WHERE SUBWAY_STATN_NO = '000001'
AND B.STD_YM = '202010'
AND B.BEGIN_TIME = '0800'
AND B.END_TIME = '0900'
ORDER BY B.TK_GFF_CNT DESC
;
이제 귀찮아서 그냥 복붙하련다..
이번에는 natural join이라 명시를 하지 않았지만, using이 있어서 그리 인식된다.
CROSS JOIN
위에서 본 product 연산자의 실제 구현이다.
그냥 join조건 없는 join에 대해 일어나는 방식이다.
발생할 수 있는 경우가 나온다.
SELECT ROWNUM AS RNUM
, NVL(A.DEPT_CD, '(Null)') AS A_DEPT_CD
, NVL(A.DEPT_NM, '(Null)') AS A_DEPT_NM
, NVL(B.EMP_NO , '(Null)') AS B_EMP_NO
, NVL(B.EMP_NM , '(Null)') AS B_EMP_NM
, NVL(B.DEPT_CD, '(Null)') AS B_DEPT_cD
FROM TB_DEPT_6_1_10 A
, TB_EMP_6_1_10 B
ORDER BY RNUM
;
이건 단순히 두 테이블을 from에서 나열하기만 하면 된다.
ANSI 방식으로는 cross join이라고 하면 된다.
이건 보통 특정 테이블의 데이터를 복제하고자 할 때 많이 사용한다고 한다.
쉽게 데이터를 불리는 것이 가능하다..!
OUTER JOIN
inner join에 대비되는 개념이며, 동일하지 않는 값이어도 행을 출력할 수 있다.
각 테이블을 집합으로 생각해보면 표현이 잘 이해될 것이다.
한쪽 집합의 내용을 전부 포함해서 표현한다면, 합쳐질 때 겹치지 않는 부분은 null로 나올 것이다.
이때 표현되는 쪽이 더 많은 부분을 나타내고 있으니 outer라고 볼 수 있겠다.
가령 직원 테이블과 부서 테이블을 연결하는데, 만약에 아직 부서가 없는 직원이 있다 쳐보자.
그냥 inner join을 하면 그 직원은 사라지게 된다.
이럴 때는 직원 테이블은 전부 값이 남도록 하고 join될 때 부서 부분이 null이 된 상태로 불러오는 게 낫다.
이럴 때 사용되는 것이 outer join이다.
크게 3가지 방식이 존재한다.
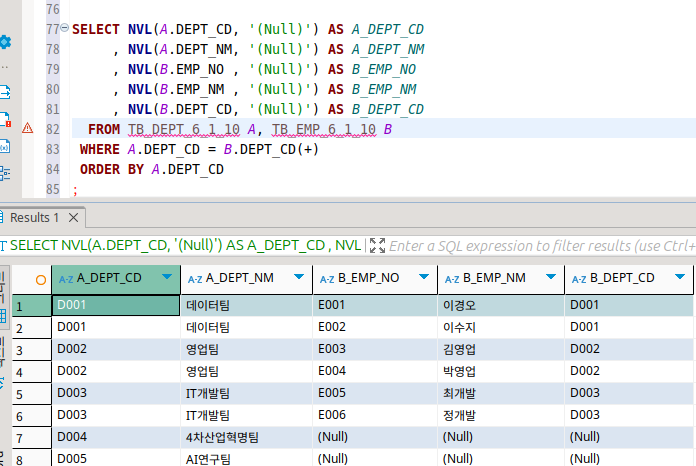
이것은 left join, 다른 쪽은 null이 나온다.
이게 바로 left, right outer join이다.
한쪽 테이블은 전부 표현하는 방식.
from 기준으로 첫번째로 작성한 테이블이 왼쪽, 다른 쪽이 오른쪽이다.
오라클에서는 null이 포함되는 쪽에 (+)로 표현을 하는 것이 보인다.
말 그대로 플러스 알파..
ANSI 방식으로는 LEFT (OUTER) JOIN이라고 하면 된다.
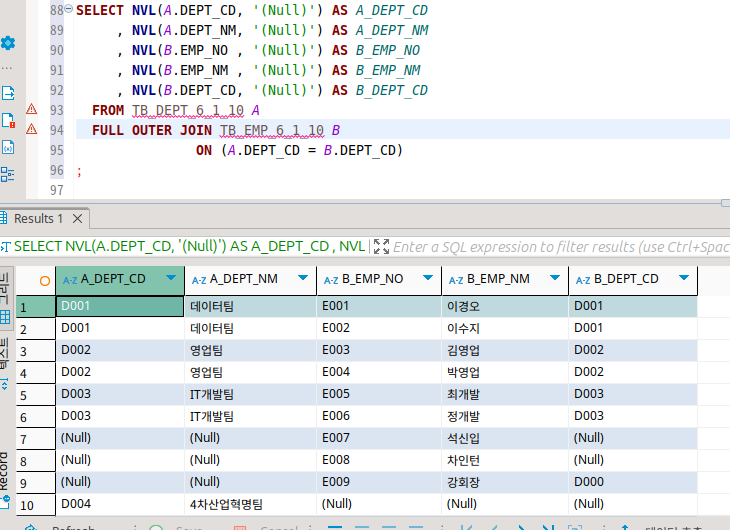
이건 full outer join
양쪽 테이블의 모든 것을 표현한다.
위에서 본 cross join하고는 다르니 주의!
매칭 되는 놈끼리는 확실히 매칭해준 뒤에 매칭 안 된 놈들이 전부 나열되는 방식이다!
참고로 이놈은 오라클 만에 그 이상한 (+) 방식이 존재하지 않는다고 한다.
조인 수행 원리
조인은 쿼리 성능에 영향이 많이 미치는 요소 중 하나이다.
인덱스와 더불어 조인 역시 최적화의 영역이 많이 존재한다.
사실 조인에도 여러 기법이 존재한다.
일단 조인 순서에 대해.
조인은 기본적으로 한번에 두 테이블씩 조인된다.
여러 개의 조인을 걸어도 실제 조인되는 것은 두 테이블씩 합쳐지면서 조인이 일어난다는 것.
그리고 앞에 있는 테이블의 조인의 기준이 된다.
이 표현은 아래 조인 기법을 보면서 더 다루기로 한다.
기법
NL 조인
Nested Loop 조인은 첫 집합 건수만큼 이후 집합을 조회하며 매칭되는 행들을 리턴한다.
대충 이중 반복문 느낌이 되는 건데, 전체 루프는 첫 집합의 행 수가 결정하기에 첫 집합의 행 수가 중요하게 작용한다.
그래서 부분범위처리가 가능한 OLTP(Online Transaction Processing)환경에서 적합하다.
즉, 최신 데이터 위주로 조회한 후 실시간으로 쿼리를 날리는 환경을 말한다.
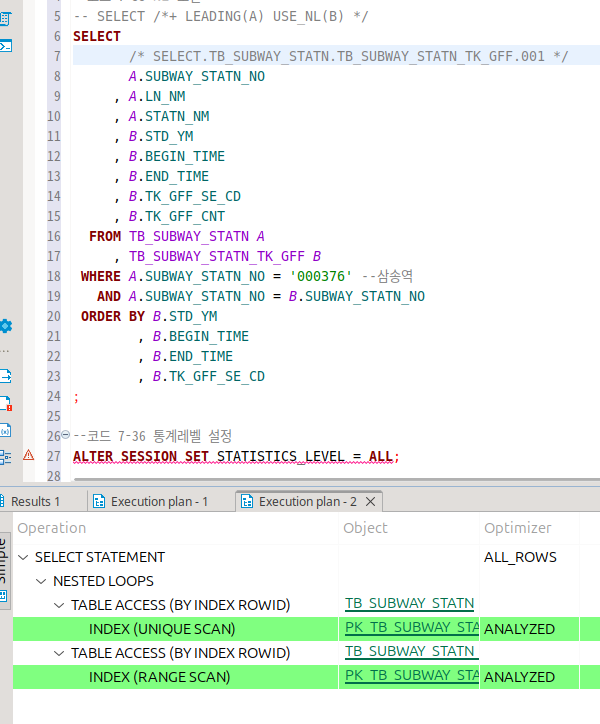
유니크 스캔이 일어난 테이블을 기준으로, nl 조인을 진행한다.
소트 머지 조인
두 테이블을 조인 컬럼 기준으로 정렬한다.
그 이후에 두 집합을 머지하면서 결과를 만든다.
머지 소트랑 비슷한 느낌이긴 하다.
두 리스트가 생긴 상황에서 이 둘을 토대로 새로운 테이블을 만드는 과정이란 점에서 그러하다.
또한 두 리스트가 이미 정렬이 된 상태라는 점에서도 그러하다.
이 조인은 인덱스의 유무에 영향을 받지 않는다.
정렬과정에서 인덱스를 사용하기도 하는데, 아무튼 조인 자체는 정렬 이후에 일어나는 작업이라 노상관.
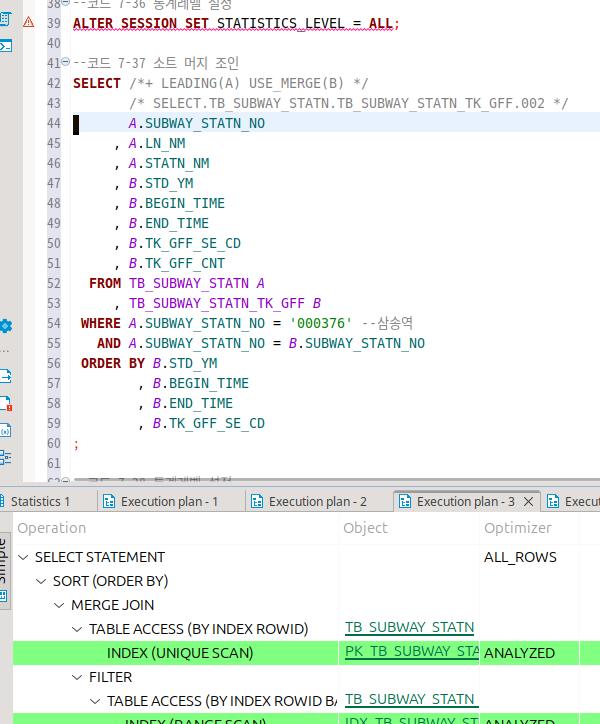
이 친구는 힌트를 안 주면 잘 안 된다.
실제로도 잘은 안 쓰인다고 한다.
where 조건을 바꿔봐도 해시 조인이 되지 이게 되지는 않았다.
해시 조인
첫 테이블을 기준으로 해시 테이블을 만든다.
그리고 다음 테이블을 해시에 넣으며 비교되는 매칭 건들을 결과에 넣는다.
그러니까 일단 테이블 스캔으로 불러오기는 한다는 것으로 보인다.
첫 테이블의 용량이 hash area 메모리 공간에 전부 담길 수 있을 정도로 작다면, 성능 상 매애우 유리하다고 한다.
왜냐, 소트머지 조인은 정렬 부하가 일어난다.
nl 조인은 범위 스캔을 대체로 먼저 하게 되니 테이블 랜덤 액세스를 실행하게 된다.
그래서 이놈은 대량 데이터 배치가 있는 테이블의 조인에 대해서 주로 사용된다고 한다.
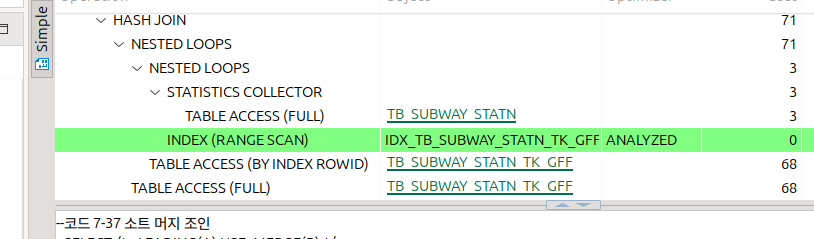
이건 이전 소트머지 조인 상황에서 발생한 해시 조인이다.
일단 둘다 결국 테이블 풀 스캔을 때린다.
그 후에 루프를 돌면서..? 인덱스를 활용하기는 하는데 잘은 모르겠다.
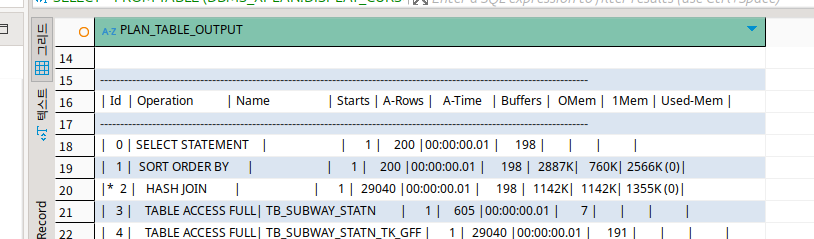
결과 해석이 잘 안돼서 실제로도 내역을 확인했는데, 여기는 조금 더 직관적으로 됐다.
둘다 테이블 스캔 때린다.
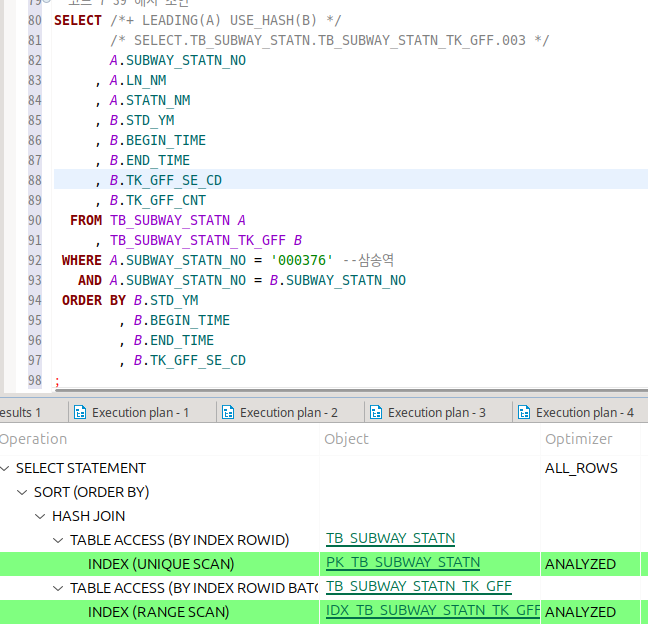
책의 예시에서는 실행 계획 상으로도 단순한 해시조인을 수행한다.
근데 이쪽은 또 보니까 인덱스 스캔을 하는데..
책에서 이야기한 장점은 nl 조인보다 좋은 점이 테이블 랜덤 액세스가 없다는 것이었다.
그런데 이렇게 인덱스 스캔을 하면 랜덤 액세스가 생기게 된다는 것이었는데..
흠냐.
만약 인덱스 스캔을 사용한다면 랜덤 액세스가 발생하게 되고, 해시 조인의 이점이 줄어들게 됩니다. 해시 조인은 큰 테이블 간의 조인에서 풀 스캔을 통해 데이터를 한 번에 읽고 해시 테이블을 만들어 조인 성능을 높이는 방식이라, 네스티드 루프 조인(NL 조인)처럼 인덱스 스캔을 많이 사용하지 않도록 설계된 것입니다.
따라서 해시 조인을 사용할 때 인덱스 스캔보다는 풀 스캔을 하는 게 일반적이고, 테이블이 매우 크거나 인덱스를 통해서도 성능이 개선되지 않는 상황에서 해시 조인을 선호하게 됩니다
그렇다고 한다.
해시 조인에서 인덱스 스캔이 일반적인 상황은 아니라고 이야기를 한다.
비교
- nl 조인
- 순차적
- 부분 범위처리
- 랜덤 액세스 부하
- 조인 조건,순서 중요
- 소트머지 조인
- 동시적
- 전체 범위처리
- sort 부하, pga 과다 사용
- 조인 순서 무관
- 해시 조인
- 동시적
- 전체 범위처리
- 첫 집합이 hash area 초과시 성능 저하
- 즉, 순서가 어무막지하게 중요
- 조인에서 = 조건이 중요함
결국, 조인은 소트머지를 제외하면 무조건 첫 집합이 작은 게 중요하다.
정규화 시의 조인
정규화를 시키면 대체로 조인을 많이 수행해야 한다.
그럼에도 외래키를 잘 걸어두면 조인의 성능이 나쁘지 않다고들 이야기한다.
일단 조인의 일관성이 보장되기 때문이다.
이를 통해 dbms는 최적화된 조인 경로를 알아서 계산해서 진행이 가능해진다.
또 불필요한 검증이 생략된다.
가령 중복 존재 확인 등의 테이블 확인 과정이 생략된다.
여기까지는 지피티의 답변.
https://velog.io/@subutai/매일-2day
오히려 대용량 디비에서는 대체로 외래키를 안 건다고 한다.
삽입이나 테이블 구조 변경 시 어려움이 발생하기 때문.
https://martin-son.github.io/Martin-IT-Blog/mysql/foreign key/performance/2022/02/28/foreign-key-Performance.html
여기에서도 dba 관점에서는 외래키를 안 거는 게 더 낫다고 이야기한다.
어차피 옵티마이저에게 중요한 것은 인덱스이기 때문이다.
https://okky.kr/questions/586565
여기에서는 또 외래키를 그래도 걸어두는 게 낫다는 입장.
관점이 다들 다르다.