Argo Workflows
개요

쿠버네티스에서 워크플로우을 만들 수 있는 툴.
워크플로우를 CRD로 구현하여 관리할 수 있게 해준다.
다음의 특징을 가지고 있다.
- 스텝 별 컨테이너를 지정하여 워크플로우를 만들 수 있다.
- 멀티 스텝, DAG 그래프 등을 활용해 복잡한 파이프라인을 짤 수 있다.
- 병렬적으로 워크플로우를 실행할 수 있다.
머신러닝 클러스터를 운영하거나, 대규모 데이터 배치 처리가 필요할 때 많이 쓰인다.
또 CICD를 할 때 활용하기도 한다.
Argo CD는 정말 CD만 가능하니 이걸로 보완하는 식이다.
이밖에도 워크플로우로 단계적으로 무언가를 적용해야할 때 유용하게 쓰인다.
아르고 시리즈는 간단명료하게 사용법이 정해져있는 게 은근히 호감이다.
(생긴 건 징그러운데)
워크플로우 흐름
일단 워크플로우라는 것이 정확하게 어떤 것인지를 알 필요가 있다.
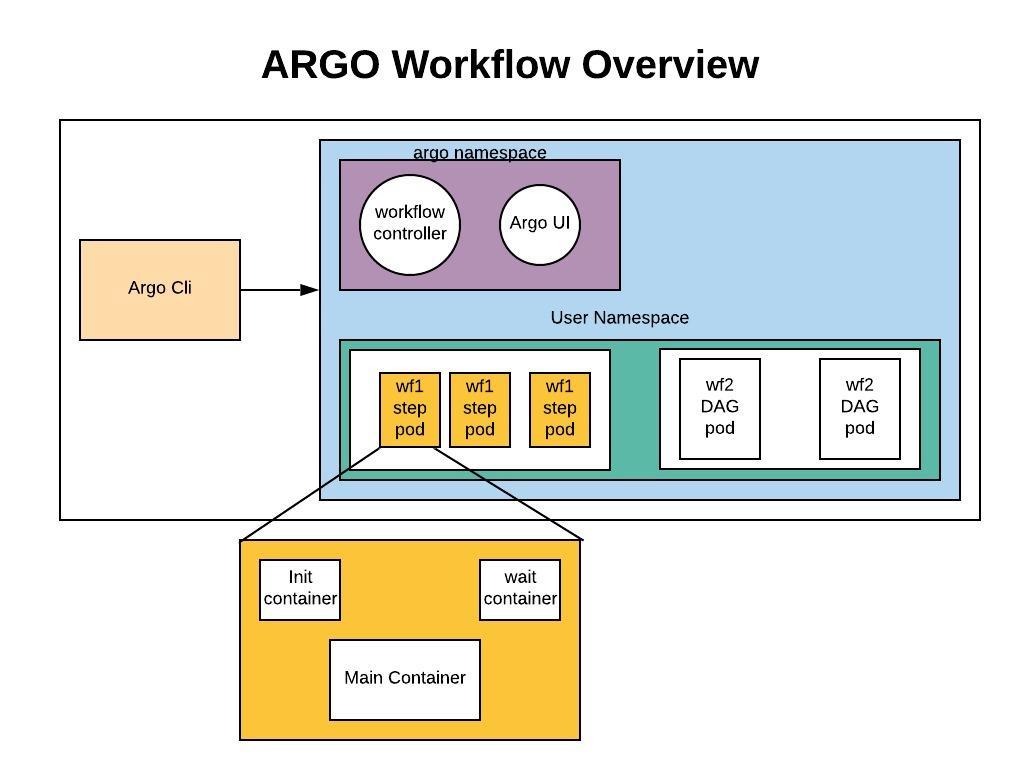
워크플로우는 초록 블록처럼, 여러 단계에 걸쳐서 특정 기능들을 수행하는 파드들을 실행하는 것이다.
젠킨스를 쓴다면 각 스테이지 별로 행동을 정의하고 관련한 코드를 작성한다.
마찬가지로 워크플로우도 그런 식으로 양식을 작성하면, 각 스텝이 파드로서 실행되는 것이다.
그래서 워크플로우에 대해서 기본적으로는 구조랄 것도 그다지 없다.[1]
워크플로우를 만들고 관리해주는 컨트롤러, 그리고 이 컨트롤러를 조금 편리하게 조작할 수 있게 해주는 아르고 서버가 있을 뿐이다.
그냥 말 그대로 워크플로우따라 파드가 만들어지는데, 사용자가 이걸 CRD로 클러스터에 상태를 등록하면 컨트롤러가 이 정보를 받아 워크플로우를 진행한다.
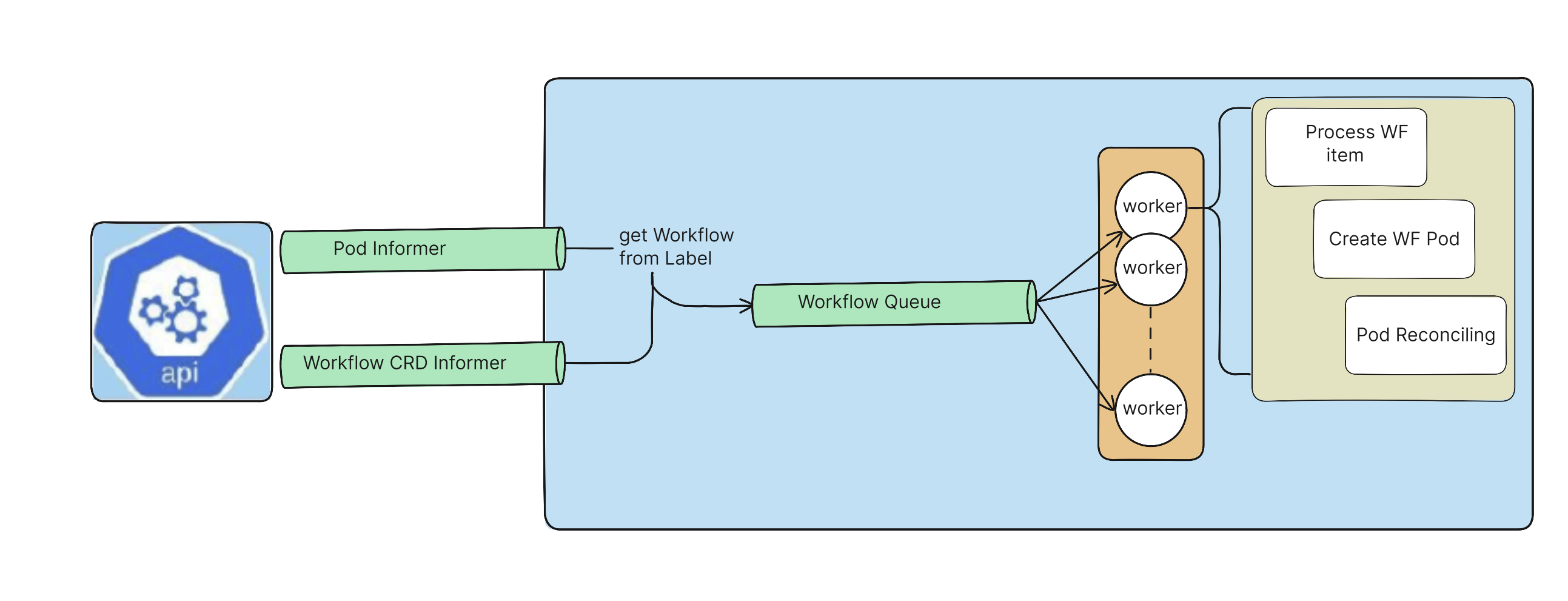
워크플로우 컨트롤러는 이런 식으로 동작한다.
파드 상태, 워크플로우 리소스 상태 살피면서 큐 관리하고, 큐에 맞춰서 워크플로우를 실행해주는 방식.
전체 구조와 기능
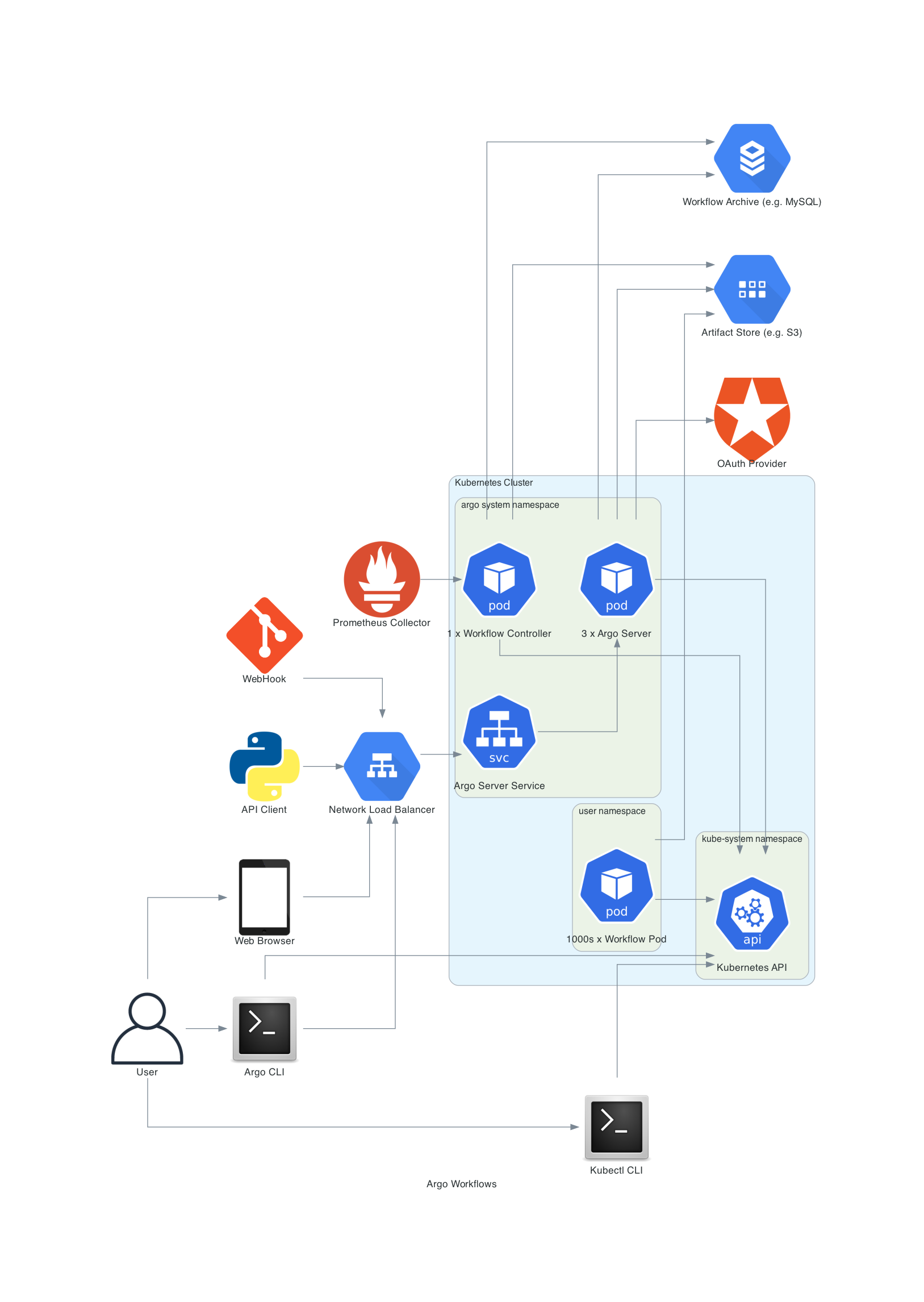
하는 일만 따지면 구조는 간단하지만, 이를 위해 들어가는 추가 기능들을 합치면 조금 더 복잡해진다.
실습을 하고 새삼 다시 보니 위 그림이 참 요약이 잘 된 그림이라는 생각이 드는데, 일단 워크플로우가 돌아가는 방식은 위에서 설명했으니 이 워크플로우를 만들거나 트리거하는 방법을 기준으로 흐름을 설명해보겠다.
위에서 워크플로우는 클러스터 리소스로서, 워크플로우 컨트롤러가 이 정보를 확인하고 실제 워크플로우를 진행한다는 것은 변함이 없다.
이때 워크플로우 리소스를 만드는 방식은 다음과 같이 다양하다.
- 사용자가 kubectl로 직접 kube-apiserver에 리소스 등록
- 아르고 서버를 거치는 방식
- argo cli(아르고 워크플로우 전용 툴)로 리소스 등록
- api로 요청 날리기
- 웹훅으로 트리거하기
- 웹 ui로 설정 만지작만지작
기본적으로 사용자의 요청을 처리하는 아르고 서버가 존재하기 때문에, 이 서버를 이용해주는 것이 흔한 이용 방식이다.
특히 이 서버를 거치면 시각화도 이쁘게 되는 것을 넘어 직접적으로 리소스를 등록하는 것보다 상태 업데이트도 깔끔하게 이뤄지기 때문에, 웬만해서는 그냥 이렇게 사용하는 것을 추천한다.
워크플로우는 CRD이기 때문에 많은 워크플로우가 진행되다 보면 정보가 많이 쌓여 Etcd에 부하가 쌓인다.
그래서 이것을 막기 위해 워크플로우의 정보들을 아카이빙 하는 것이 가능한데, 현재는 RDBMS를 활용할수 있다.
또한 워크플로우의 각 단계는 파드로 만들어지기 때문에 기본적으로 서로 데이터를 공유하는 것이 제한된다.
양식 작성법을 보면 간단한 데이터는 전달할 수 있다는 걸 보게 될 것이다.
그러나 머신러닝을 하거나 이미지 빌드 등의 작업을 수행한다고 생각해보자.
이러면 전달할 데이터의 크기가 어마무시하게 클 수도 있다.
이럴 때를 위해, 아르고 워크플로우는 아티팩트(artifact)라는 개념으로 외부 저장소를 두어 데이터 공유나 통합, 처리를 용이하게 할 수 있도록 돕는다.
아티팩트의 종류에는 S3와 같은 오브젝트 스토리지, 깃 등이 가능하다.
나중에 더 깊게 다룰 기회가 있다면 다룰 텐데, 아티팩트를 설정하는 게 킥이다 진짜.
워크플로우(Workflow) 양식 작성법
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world-
spec:
entrypoint: hello-world # 템플릿 진입점
arguments:
parameters:
- name: message
value: hello world
templates:
- name: print-message
inputs:
parameters:
- name: message
container:
image: busybox
command: [echo]
args: ["{{inputs.parameters.message}}"]
아르고 워크 플로우의 핵심은 말 그대로 워크플로우 리소스니, 이 놈을 먼저 보고 이후 다양한 설정들을 다루겠다.
기본적으로 위 모습처럼 구성을 하는데, 일단 generateName을 이용해 여러 워크플로우가 생성될 때 접두사가 붙도록 설정한다.
스펙에서는 템플릿을 여러 개 작성한 후, 최종적으로 이 워크플로우의 진입점이 되는 템플릿을 entrypoint로 명시해주면 끝이다!

너무 간단하게 핵심을 문서에서 잘 정리해서 가져왔다.[2]
결국 워크플로우 양식의 핵심은 템플릿을 여러 개 원하는 대로 작성하고, 진입점만 잘 박아주는 것이다.
일단 워크플로우 오브젝트는 크게 두 가지 기능을 한다는 것을 알아두자.
- 워크플로우가 어떻게 실행될지를 정의한다.
- 워크플로우가 진행된, 혹은 진행되고 있는 상태를 저장한다.
템플릿 유형
워크플로우에서 템플릿은 곧 각 기능 단위, 즉 함수를 의미한다.
템플릿은 총 9개의 유형으로 분화된다.
container
- name: hello-world
container:
image: busybox
command: [echo]
args: ["hello world"]
그냥 일반 컨테이너를 의미하며, 흔히 파드 스펙에 작성하는 컨테이너 스펙을 그대로 작성하면 된다.
이렇게 실행하면 기본적으로 하나의 컨테이너가 담긴 하나의 파드가 만들어진다.
script
- name: gen-random-int
script:
image: python:alpine3.6
command: [python]
source: |
import random
i = random.randint(1, 100)
print(i)
컨테이너 중 그냥 인자를 넣어서 실행하는 역할을 하는 템플릿은 아예 이렇게 스크립트 유형으로 만들어주면 된다.
source필드를 통해 편하게 스크립트를 작성할 수 있게 해두었다.
resource
- name: k8s-owner-reference
resource:
action: create
manifest: |
apiVersion: v1
kind: ConfigMap
metadata:
generateName: owned-eg-
data:
some: value
쿠버네티스의 리소스를 조작하는 템플릿이다!
get, create, list, delete 등의 다양한 작업을 할 수 있다.
워크플로우가 지워지면 해당 리소스도 같이 지워지도록 돼있다.
소유자 참조 필드를 지워주면 독립적으로 성립하게 할 수도 있다.
당연히 이게 제대로 이뤄지려면 이 워크플로우를 실행하는 컨트롤러가 관련한 권한을 가지고 있어야만 한다.
suspend
- name: delay
suspend:
duration: "20s"
그냥 잠시 대기하는 템플릿 유형이다.
duration 필드 없이 그냥 쓰면 관리자가 직접 resume을 시켜줘야 한다.
plugin
- name: main
plugin:
slack:
text: "{{workflow.name}} finished!"
외부의 플러그인 조작을 하는 템플릿이다.
containerSet
- name: main
volumes:
- name: workspace
emptyDir: { }
containerSet:
volumeMounts:
- mountPath: /workspace
name: workspace
containers:
- name: a
image: argoproj/argosay:v2
command: [sh, -c]
args: ["echo 'a: hello world' >> /workspace/message"]
- name: b
image: argoproj/argosay:v2
command: [sh, -c]
args: ["echo 'b: hello world' >> /workspace/message"]
- name: main
image: argoproj/argosay:v2
command: [sh, -c]
args: ["echo 'main: hello world' >> /workspace/message"]
dependencies:
- a
- b
한 파드에 여러 컨테이너를 실행할 때는 containerSet을 사용한다.
아무래도 pause 컨테이너가 더 만들어지지 않으니 리소스 낭비는 적다.
그리고 emptyDir 볼륨을 이용해 데이터를 공유할 수 있다는 것도 장점.
재밌는 것은 여기에 dependencies를 설정해서 이 컨테이너 간 의존성도 정할 수 있다는 것이다.

주의할 점은 이것이다.
자원 요청 시에 모든 컨테이너의 합산으로 요청이 되기 때문에, 최대 2기가가 필요한 필요하다면 컨테이너의 요청량 합이 2기가가 되도록 세팅해야 낭비가 없다.
http
- name: http
inputs:
parameters:
- name: url
http:
timeoutSeconds: 20 # Default 30
url: "{{inputs.parameters.url}}"
method: "GET" # Default GET
headers:
- name: "x-header-name"
value: "test-value"
body: "test body" # 보낼 요청 바디
# 성공 조건 명시
# 사용가능한 변수는 다음과 같다.
# request.body: string, the request body
# request.headers: map[string][]string, the request headers
# response.url: string, the request url
# response.method: string, the request method
# response.statusCode: int, the response status code
# response.body: string, the response body
# response.headers: map[string][]string, the response headers
successCondition: "response.body contains \"google\"" # available since v3.3
말그대로 http 요청을 날리는 유형이다.
성공 조건을 명시하는 것도 가능하다.
경험 상 이 템플릿은 생각보다 실행이 조금 불안정해서, 차라리 container 템플릿으로 직접 요청을 날리는 식으로 쓰는 게 더 좋은 것 같다.
템플릿 주입기
아래 두 템플릿 유형은 조금 특별한데, 다른 템플릿들을 명시하여 순서나 그래프를 지정하는 역할을 하는 템플릿이다.
이 아래 템플릿들을 통해, 위 템플릿들의 순서나 구조를 짜맞춰가며 진정한 워크플로우를 만들 수 있는 것이다!
steps
spec:
entrypoint: hello-hello-hello
templates:
- name: hello-hello-hello
단계 지정
steps:
# 첫 단계
- - name: hello1
template: print-message
arguments:
parameters:
- name: message
value: "hello1"
# 두번째 단계
- - name: hello2a
template: print-message
arguments:
parameters:
- name: message
value: "hello2a"
# 두번째 단계가 병렬적으로 실행!
- name: hello2b
template: print-message
arguments:
parameters:
- name: message
value: "hello2b"
- name: print-message
inputs:
parameters:
- name: message
container:
image: busybox
command: [echo]
args: ["{{inputs.parameters.message}}"]
steps는 단계 별로 템플릿 실행 단계를 정의하는 방식이다.
보다시피 steps는 이중 리스트 구조로 되어 있으며, 상위 리스트는 템플릿 간 순서를 구분짓고, 하위 리스트는 병렬적으로 실행할 템플릿을 넣는 공간이 된다.

위 워크플로우가 실행되면 이런 식의 모양이 될 것이다.
트리 구조처럼 자식 노드의 부모가 하나로만 구성되는 워크플로우를 짤 때 직관적으로 짤 수 있어서 좋다.
dag
- name: diamond
dag:
tasks:
- name: A
template: echo
arguments:
parameters: [{name: message, value: A}]
- name: B
dependencies: [A]
template: echo
arguments:
parameters: [{name: message, value: B}]
- name: C
dependencies: [A]
template: echo
arguments:
parameters: [{name: message, value: C}]
- name: D
dependencies: [B, C]
template: echo
arguments:
parameters: [{name: message, value: D}]
스텝이 아니라 DAG(Directed Acyclic Graph, 방향이 있는 비순환 그래프)를 이용하는 방법도 있다.
이것은 직접저으로 dependencies로 의존성을 표현해주기에, 자식 노드가 여러 부모를 가지는 것도 가능하다.
또한 더 복잡한 구조를 만들기에 용이하나, 막상 해보면 이 녀석으로 양식 작성할 때 조금 귀찮은 측면도 없잖아 있기는 하다.
아무튼 각각을 dag.tasks에 리스트로 이름을 작성한다.
위 워크플로우는 A -> B,C -> D와 같은 식으로 실행될 것이다.
이런 주입 유형의 템플릿들에 대해서는 [[#반복문, 조건문]]을 걸어서 더 다양하게 워크플로우를 짤 수 있다.
데이터 입출력, 인자(arguements)
템플릿 각각이 하나의 함수라고 했는데, 실제 함수가 그러하듯 템플릿은 입력과 출력을 하는 것이 가능하다.
어떤 식으로 설정을 하는지를 알기 이전에, 인자에는 두 가지 유형이 있다는 것을 먼저 짚고 가야 한다.
arguement의 유형에는 parameters, artifacts 두 가지가 있다.
파라미터는 말 그대로 워크플로우 내에서 사용할 인수들을 넣을 때 사용한다.
작은 데이터를 간단하게 주고 받을 때, 함수 입출력처럼 흔히 사용되는 방식이다.
아티팩트는 외부 저장 공간에서 데이터를 가져올 때 사용한다.
크거나 영속성을 가져야하는 데이터가 있을 때 주로 사용된다.
artifacts:
# 깃 메인브랜치 가져와서 /src에 위치시킴
# 리비전은 브랜치 이름이던 커밋이름이던, 태그던 다 가능
- name: argo-source
path: /src
git:
repo: https://github.com/argoproj/argo-workflows.git
revision: "main"
- name: kubectl
path: /bin/kubectl
mode: 0755
http:
url: https://storage.googleapis.com/kubernetes-release/release/v1.8.0/bin/linux/amd64/kubectl
# s3의 데이터를 받아와서 저장
- name: objects
path: /s3
s3:
endpoint: storage.googleapis.com
bucket: my-bucket-name
key: path/in/bucket
accessKeySecret:
name: my-s3-credentials
key: accessKey
secretKeySecret:
name: my-s3-credentials
key: secretKey
이런 식으로 깃이나 S3 등 다양한 곳에서 데이터를 가져와서 템플릿 실행 환경에 넣어줄 수 있다.
참고로 아티팩트라고 해서 무조건 외부 저장소를 사용해야 한다는 뜻은 아니다!
파라미터 쓰듯이 아티팩트를 쓰는 것도 가능하긴 한데, 가급적이면 목적에 맞게 구분해서 쓰는 것이 당연히 좋겠지?
apiVersion: v1
kind: ConfigMap
metadata:
name: artifact-repositories # 이 이름을 지으면 모든 워크플로우가 이 컨맵의 데이터를 아티팩트로 활용할 수 있다.
annotations:
# 이 어노테이션의 값으로 지정된 데이터는 아무론 설정없이 모든 워크플로우가 쓸 수 있다.
# 다른 데이터들은 각 워크플로우에서 추가 설정을 하긴 해야 한다.
workflows.argoproj.io/default-artifact-repository: default-v1-s3-artifact-repository
data:
default-v1-s3-artifact-repository: |
s3:
bucket: my-bucket
endpoint: minio:9000
insecure: true
accessKeySecret:
name: my-minio-cred
key: accesskey
secretKeySecret:
name: my-minio-cred
key: secretkey
v2-s3-artifact-repository: |
s3:
...
아티팩트를 여러 개 쓰게 되면 일일히 워크플로우에 쓰기 힘든데, 이런 식으로 컨피그맵으로 관리하는 것도 가능하다.
위처럼 여러 데이터를 넣는 것도 가능한데, 이때 기본으로 쓰일 데이터를 지정하고 싶다면 어노테이션을 저리 달자.
spec:
artifactRepositoryRef:
configMap: my-artifact-repository
key: v2-s3-artifact-repository
기본이 아닌 데이터들은 이런 식으로 워크플로우에서 이런 식으로 필드를 주면 된다.
해당 컨피그맵에서 한 키를 지정할 때 이렇게 필드를 명시한다.
이제 인자의 유형과 설정 방법을 간단하게 봤으니, 실제로 인자를 템플릿의 입출력에 어떻게 이용하는지 보자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: example-
spec:
entrypoint: main
arguments:
parameters:
- name: workflow-param-1
templates:
- name: main
dag:
tasks:
- name: step-A
template: step-template-a
arguments:
parameters:
- name: template-param-1
value: "{{workflow.parameters.workflow-param-1}}"
- name: step-template-a
inputs:
parameters:
- name: template-param-1
script:
image: alpine
command: [/bin/sh]
source: |
echo "{{inputs.parameters.template-param-1}}"
outputs:
parameters:
- name: output-param-1
valueFrom:
path: /p1.txt
artifacts:
- name: output-artifact-1
path: /some-directory
각 템플릿의 입력과 출력은 기본적으로 inputs, outputs 필드이다.
템플릿 내에서 어떤 입력을 활용할 때는 inputs 필드를 정의하고 여기에 들어오는 데이터를 사용하면 된다.
출력하고 싶은 값은 outputs 필드에 작성해서 넣어주면 된다.
그렇다면 각 템플릿은 inputs 필드를 이용해 데이터를 받는데 실제로 해당 필드로 데이터를 넣어주는 통로가 무엇이냐?
그것이 바로 arguements 필드이다.
위 예시에서 dag 템플릿은 하위 템플릿에 대해 arguements를 지정하고 있는 것이 보인다.
이것이 바로 하위 템플릿에 어떠한 데이터를 넣겠다, 하는 뜻이다.
위 예시에는 워크플로우 단위에서 arguements로 사용할 인자를 정의하는 것도 담겨있다.
arguments:
parameters:
- name: template-param-2
value: "{{tasks.step-A.outputs.parameters.output-param-1}}"
artifacts:
- name: input-artifact-1
from: "{{tasks.step-A.outputs.artifacts.output-artifact-1}}"
outputs 필드의 데이터를 arguements로 넣을 때는 이런 식으로 지정한다.
그럼 다음 템플릿에서는 이런 식으로 출력 데이터를 받아서 사용할 수 있을 것이다.
주의할 게 있는데, 파라미터로 들어왔을 때는 value라는 필드를 쓰지만 아티팩트로 들어올 때는 from을 써야한다는 것이다.
(헷갈리게시리)
위의 예시에서 arguements.parameters라고 하여 파라미터라는 필드를 추가 사용하는 것이 보일 것이다.
- - name: generate
template: gen-random-int-bash
- - name: print
template: print-message
arguments:
parameters:
- name: message
value: "{{steps.generate.outputs.result}}" # The result of the here-script
참고로 http, container, script 유형의 템플릿은 우리가 명시해주지 않아도 자체적으로 result라는 유형의 출력값을 가진다.
gen-random-int-bash 템플릿은 script 유형인데, 덕분에 다음 템플릿에서 ouputs.result라고 해서 데이터를 받아올 수 있다.
반복문, 조건문
- name: loop-sequence-example
steps:
- - name: hello-world-x5
template: hello-world
withSequence:
count: "5"
- - name: test-linux
template: cat-os-release
arguments:
parameters:
- name: image
value: "{{item.image}}"
- name: tag
value: "{{item.tag}}"
withItems:
- { image: 'debian', tag: '9.1' }
- { image: 'debian', tag: '8.9' }
- { image: 'alpine', tag: '3.6' }
- { image: 'ubuntu', tag: '17.10'}
- - name: test-linux
template: cat-os-release
arguments:
parameters:
- name: image
value: "{{item.image}}"
- name: tag
value: "{{item.tag}}"
withParam: "{{inputs.parameters.os-list}}"
with로 시작하는 필드를 넣어 반복적으로 템플릿을 실행할 수 있다.
반복문은 총 3가지 방식으로 사용할 수 있다.
- withSequence
- 일정 숫자만큼 반복
- withItems
- 일정 리스트만큼 반복인데, 위처럼 json 형식의 데이터를 전달할 수도 있다.
- withParams
- 파라미터로 들어온 값으로 withItems처럼 사용.
withParams를 이용하면 동적으로 워크플로우의 횟수를 지정할 수 있게 되기 때문에 매우 유용하다!
이렇게 반복되는 템플릿으로부터 출력물을 받아올 때는 데이터가 리스트 형식으로 들어온다.
일종의 aggregate된 결과를 볼 수 있게 되는 것이다.
- name: coinflip
steps:
# 첫번째 코인
- - name: flip-coin
template: flip-coin
# 이 둘중 하나만 실행된다.
- - name: heads
template: heads
when: "{{steps.flip-coin.outputs.result}} == heads"
- name: tails
template: tails
when: "{{steps.flip-coin.outputs.result}} == tails"
# 두번째 코인
- - name: flip-again
template: flip-coin
# 굳이 조건문 복잡하게 다는 것도 지원!
- - name: complex-condition
template: heads-tails-or-twice-tails
when: >-
( {{steps.flip-coin.outputs.result}} == heads &&
{{steps.flip-again.outputs.result}} == tails
) ||
( {{steps.flip-coin.outputs.result}} == tails &&
{{steps.flip-again.outputs.result}} == tails )
- name: heads-regex
template: heads
when: "{{steps.flip-again.outputs.result}} =~ hea"
- name: tails-regex
template: tails
when: "{{steps.flip-again.outputs.result}} =~ tai"
이런 식으로 when 필드를 써주면 조건문이 된다.
이로써 워크플로우를 분기시켜서 실행하는 것도 가능해진다.
spec:
entrypoint: coinflip
templates:
- name: coinflip
steps:
- - name: flip-coin
template: flip-coin
- - name: heads
template: heads
when: "{{steps.flip-coin.outputs.result}} == heads"
- name: tails
template: coinflip # 이 step 템플릿의 이름이다!
when: "{{steps.flip-coin.outputs.result}} == tails"
조건문이 있다면.. 종료 조건처럼 쓸 수도 있다는 뜻이고.. 그렇다면 재귀 템플릿도 가능하다..!
위의 워크플로우는 동전이 앞면이 나올 때까지 계속 재귀를 돌 것이다.

이런 식으로 말이다.
volumes, volumeClaimTemplates
spec:
entrypoint: print-secrets
volumes:
- name: my-secret-vol
secret:
secretName: my-secret
templates:
- name: print-secrets
container:
image: alpine:3.7
command: [sh, -c]
args: ['
']
env:
- name: MYSECRETPASSWORD
valueFrom:
secretKeyRef:
name: my-secret
key: mypassword
volumeMounts:
- name: my-secret-vol
mountPath: "/secret/mountpath"
---
spec:
entrypoint: volumes-pvc-example
volumeClaimTemplates: # define volume, same syntax as k8s Pod spec
- metadata:
name: workdir # name of volume claim
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
템플릿 간 파일 공유, 혹은 영구 스토리지 참조 등이 필요하다면 이렇게 쿠버네티스 볼륨을 그대로 사용해줄 수 있다!
얼마나 편리한가!
스테이트풀셋이 그러듯이 PVC 템플릿 넣는 것도 쌉가능이당
근데 주의할 점이 있는데, 이건 위에서 말한 아티팩트와는 다르다.
이 볼륨은 그저 워크플로우를 실행하는데 있어 공통적으로 사용하기 위한 공간에 불과하다.
워크플로우의 각 단계는 파드이기에 기본적으로 서로 데이터를 공유하는 것이 어렵기 때문에 arguement에 parameter를 사용하는 건데, 이걸로도 부족하다면 이런 식으로 공용 공간을 두어 사용하는 게 효과적일 것이다.
아티팩트로도 대체가 가능하긴 한데, 역시나 어떻게 이용할지는 사용자의 몫이라 할 수 있겠다.
실행 주체
한 워크플로우는 하나의 서비스 어카운트를 가지고 실행된다.
이건 .spec.serviceAccountName 필드를 작성해주면 되는데, 명시 안 하면 해당 네임스페이스의 default 서아로 실행된다.
다른 리소스 참조라던가 하는 행위를 하기 위해서는 서아의 RBAC 세팅이 필수인데 default 사용하는 건.. 당연히 안 좋겠지..?
훅
워크플로우가 실행되는 동안 몇 가지 훅을 거는 게 가능하다.
spec:
entrypoint: main
hooks:
exit:
template: http
running:
expression: workflow.status == "Running"
template: http
위의 예시는 워크플로우가 종료됐을 때 http라는 템플릿을 실행한다.
그리고 실행 중일 때는 워크플로우의 status가 Running인 경우에도 http 템플릿을 실행한다.
workflow.status == "Succeeded"일 때 요청을 보내게 한다던가 하는 것도 가능할 것이다.
spec:
entrypoint: main
onExit: http
참고로 종료에 대한 훅은 이렇게도 가능하다.
재시작
retryStrategy:
limit: 10
retryPolicy: "Always"
backoff:
duration: "1s"
factor: 2
maxDuration: "1m"
affinity:
nodeAntiAffinity: {}
템플릿이나 워크플로우 단위로 재시작 전략을 설정할 수 있다.
backoff 필드는 실패해서 재시작해야 할 때 어느 정도의 시간을 두고 재시작할지를 나타낸다.
affnity 필드는 실패한 노드에서 다시 실행되지 않도록 하기 위한 필드인데, 현재 버전에서는 여기 추가 커스텀은 안 되고 딱 저렇게만 사용가능하다고 한다.
기타 리소스 양식 작성법
WorkFlowTemplate, ClusterWorkFlowTemplate
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: hello-world-template-global-arg
spec:
templates:
- name: hello-world
container:
image: busybox
command: [echo]
args: ["{{workflow.parameters.global-parameter}}"]
---
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world-wf-global-arg-
spec:
entrypoint: print-message
arguments:
parameters:
- name: global-parameter
value: hello
templates:
- name: print-message
steps:
- - name: hello-world
templateRef:
name: hello-world-template-global-arg
template: hello-world
기본적으로 워크플로우는 만들어지면 바로 동작을 시작한다.
근데 보통은 워크플로우 템플릿을 짜두고 필요할 때마다 이에 맞춰서 이용하지 않는가?
그럴 때 사용하는 것이 바로 이 템플릿 리소스다.
아래 워크플로우는 스텝 템플릿 안에 templateRef로 만들어둔 템플릿을 가져오는 것이 보인다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: workflow-template-hello-world-
spec:
workflowTemplateRef:
name: workflow-template-submittable
워크플로우템플릿 리소스에 진입점 같은 세팅을 해뒀다면, 아예 이렇게 workflowTemplateRef를 이용해 통째로 이용하는 것도 가능하다.
workflowTemplateRef:
name: cluster-workflow-template-submittable
clusterScope: true
ClusterWorkflowTemplate이라고 kind를 지정해 클러스터 전역으로 만들 수도 있는데, 그걸 사용할 때는 위처럼 clusterScope: true를 명시해야 한다.
CronWorkflow
apiVersion: argoproj.io/v1alpha1
kind: CronWorkflow
metadata:
name: test-cron-wf
spec:
schedules:
- "* * * * *"
concurrencyPolicy: "Replace"
startingDeadlineSeconds: 0
workflowSpec:
entrypoint: date
templates:
- name: date
container:
image: alpine:3.6
command: [sh, -c]
args: ["date; sleep 90"]
말 그대로 크론으로 하는 방식!
크론잡이란 비슷한 느낌이다.
트리거
실질적으로 워크플로우를 사용할 때, 직접 워크플로우 가동해야겠다 하고 하는 사용 케이스는 많이 없을 것이다.
주기적으로 데이터를 학습시켜야 한다는 특정 조건, 아니면 개발을 마쳐서 깃에 머지가 된 시점에 워크플로우가 실행되길 바라는 게 대부분일 것이다.
이럴 때 웹훅 트리거, 혹은 api 요청을 보내서 워크플로우를 실행하는 것이 가능하다.[3]
이벤트라는 api 엔드포인트를 노출하고 있으며, 이쪽으로 트리거링을 할 수 있다.
참고로 문서에서도 언급하는데 이건 Argo Events와는 무관하게 존재하는 워크플로우의 리소스이다.
물론 아르고 이벤트와도 연동하여 이용할 수도 있긴 하다.
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: my-wf-tmple
namespace: argo
spec:
templates:
- name: main
inputs:
parameters:
- name: message
value: "{{workflow.parameters.message}}"
container:
image: busybox
command: [echo]
args: ["{{inputs.parameters.message}}"]
entrypoint: main
---
apiVersion: argoproj.io/v1alpha1
kind: WorkflowEventBinding
metadata:
name: event-consumer
spec:
event:
# 들어온 요청 중 어떤 것이 이벤트인지 정하는 필드.
# discriminator는 아래 참조.
selector: payload.message != "" && metadata["x-argo-e2e"] == ["true"] && discriminator == "my-discriminator"
submit:
workflowTemplateRef:
name: my-wf-tmple
arguments:
parameters:
- name: message
valueFrom:
event: payload.message
이런 식으로 워크플로우템플릿, 그리고 이벤트바인딩 리소스를 만들어야 한다.
이 워크플로우 이벤트 바인딩 리소스가 api를 노출하는 핵심으로, 이 리소스를 만들면 다음의 경로로 api가 노출된다.
아르고서버/api/v1/events/네임스페이스/식별자(discriminator)
뒤 식별자는 단순히 검증용이라 필수적으로 넣어야 한다 이런 건 아니다.
curl $ARGO_SERVER/api/v1/events/argo/my-discriminator \
-H "Authorization: $ARGO_TOKEN" \
-H "X-Argo-E2E: true" \
-d '{"message": "hello events"}'
위의 리소스라면 요청을 이렇게 보내면 트리거될 것이다.
근데 보통 웹훅을 보내는 서비스들은 저마다 각자의 웹훅 쏘는 방식이 정해져있다..
그래서 api로 보내는 웹훅에 대해서 추가적인 설정을 할 수 있다.[4]
이런 추가 설정이 필요한 이유는 궁극적으로는 인증 인가 때문인데, 흐름을 정리하자면 다음과 같다.
- 웹훅에서는 보통 자신을 식별시킬 문자열 데이터를 보낸다.

- 깃헙에서 여기 Secret이 바로 그 문자열에 해당한다.
- 이 문자열 데이터를 지정하는 ConfigMap을 만들고, 이로부터 해당 웹훅의 클러스터 신원으로 사용될 서비스 어카운트를 특정한다.
- 이 서비스 어카운트의 토큰을 통해 어떤 권한이 있는지를 체크한다.
위 문서 링크의 세팅 내용들은 이 흐름을 위한 각종 리소스들을 설정하는 과정이다.
좀 자세하게 좀 설명 좀 해주지 좀
보안

아르고 워크플로우가 자체적으로 api 서버를 가지고 있는 만큼, 이 api를 사용할 수 있는 유저에 대한 신원을 확인하는 절차가 마련되어 있다.
다만 자체적으로 유저의 신원을 관리하는 것은 아니고, 전적으로 외부(아르고 입장에서)에 인증을 위임한다.
크게는 세 가지 방식이 존재한다.
- 서버 모드
- 이건 아르고 서버를 포트포워딩하는 식으로 이용할 때 이뤄지는 방식으로, 아르고 서버 자체의 클러스터 신원으로 이용이 가능하다.
- 당연히 보안적으로 좋은 방법은 아니다.
- 클라이언트 모드
- 시큐리티#API 서버 보안을 활용하는 방식으로, 편리하고 직관적인 편이다.
- 사진으로는 중간의 방식으로, JWT 토큰을 받아서
Bearer {jwt}와 같은 식으로 넣어주면 된다. - cli로 쓴다면 그냥 kubeconfig 설정으로 따라간다.
- SSO
- 외부 인증 제공자에게 인증을 위임한다.
- 이 경우 당연히 추가적으로 설정을 해줘야 한다.
설치
resource "helm_release" "argo_workflows" {
count = var.create ? 1 : 0
repository = "https://argoproj.github.io/argo-helm"
chart = "argo-workflows"
version = "0.45.11"
name = "argo-workflows"
namespace = "argo"
create_namespace = true
values = [
]
}
헬름으로 간단하게 설치가 가능하다.(위 예시는 테라폼까지 활용)
워크플로우를 사용할 때 유용한 cli 툴도 제공해주는데, 이건 직접 설치를 해야 한다.[5]
ARGO_OS="darwin"
if [[ uname -s != "Darwin" ]]; then
ARGO_OS="linux"
fi
curl -sLO "https://github.com/argoproj/argo-workflows/releases/download/v3.6.5/argo-$ARGO_OS-amd64.gz"
gunzip "argo-$ARGO_OS-amd64.gz"
chmod +x "argo-$ARGO_OS-amd64"
mv "./argo-$ARGO_OS-amd64" /usr/local/bin/argo
argo version
그냥 kubectl로 해도 되는데, 그래도 전문 커맨드인만큼 편의성과 시각화가 더 잘 돼서 막상 써보면 안 쓸 수가 없다.[6]
동생 아르고 롤아웃은 kubectl 플러그인으로도 제공해주는데.. 이 친구들 같이 좀 일해라![7]
관련 문서
| 이름 | noteType | created |
|---|---|---|
| Argo CD | knowledge | 2025-03-24 |
| Argo Workflows | knowledge | 2025-03-24 |
| 아르고 롤아웃과 이스티오 연계 | knowledge | 2025-04-22 |
| 8W - 아르고 워크플로우 | published | 2025-03-30 |
| 8W - 아르고 CD | published | 2025-03-30 |
| 8W - CICD | published | 2025-03-30 |
| 10W - Vault를 활용한 CICD 보안 | published | 2025-04-16 |
| 3W - 트래픽 가중치 - flagger와 argo rollout을 이용한 점진적 배포 | published | 2025-04-22 |
| E-buildKit을 활용한 멀티 플랫폼, 캐싱 빌드 실습 | topic/explain | 2025-03-30 |
참고
https://argo-workflows.readthedocs.io/en/latest/architecture/ ↩︎
https://argo-workflows.readthedocs.io/en/latest/walk-through/the-structure-of-workflow-specs/ ↩︎
https://argo-workflows.readthedocs.io/en/stable/webhooks/ ↩︎
https://argo-workflows.readthedocs.io/en/latest/cli/argo/ ↩︎
https://argo-rollouts.readthedocs.io/en/stable/features/kubectl-plugin/ ↩︎