Etcd
개요

쿠버네티스]에서 모든 설정을 담는 저장소로 활용되는 것으로 유명한 etcd.
분산 환경에서 신뢰성 있는 키값 저장소를 제공한다.
기본적으로 분산환경에서 가동될 것을 전제로 하기에, RAFT 알고리즘을 기반으로 동작한다.
물론 싱글 노드로 띄울 수도 있긴 하다.
문서보니까 엄청 깔끔해서 생각보다 읽기 편했다.
참고로 etcd는 distribution of etc라고 해서 이름이 붙었고, 엣시디라고 발음한다.
특징

일단 기능 위주로 보자면, 위의 특징이 있다.
간단한 인터페이스와 파일시스템과 같은 방식의 스토리지, 그리고 데이터 변경을 감지하게 해줄 수 있다.
3번째 기능은 쿠버에서 자주 보이는 watch 개념을 말한다.
여기에 데이터를 잠시만 보관하는 lease 기능도 존재한다.
etcd를 향한 통신은 기본적으로 전부 gRPC 프로토콜을 통해 이뤄진다.
멀티 버전(revision)
엣시디는 데이터를 여러 버전에 걸쳐 저장할 수 있도록 설계됐다.
그래서 같은 키의 데이터가 변경돼도 이전 버전은 revision이 값이 달라 이전 버전의 데이터를 읽어오는 것이 가능하다.
그래서 멀티 버전 키값 저장소라는 특징도 가지고 있다.
실질적으로 데이터를 업데이트 하는 행위는 새로운 저장공간을 할당하는 개념이며, 기본적으로 데이터를 변경 불가능(immutable)하다.
각 키는 버전을 가지며, 저장된 전체 키의 영역은 revision으로서 관리된다.
이렇게 버전을 쌓기만 하면 순식간에 용량을 잡아먹게 되기 때문에, 일정 임계치를 넘어갈 때 etcd는 이전 버전을 압축하는 과정을 거친다.
매우 강력한 일관성
etcd는 분산 환경에서 작동하도록 설계됐으며, 이중에서 일관성(Consistency)를 가장 중요시한다.[1]

이 그림은 분산 시스템의 CAP 이론에서 보완된 PACELC 이론이다.
참 알아보기 힘든 도식이라 생각하는데.. 아무튼 네트워크 파티션으로 인해 무언가를 포기해야 한다면 etcd는 가용성을 포기한다(CP).
그리고 일반적인 상황에서도 일관성을 위해 레이턴시를 하위로 둔다(EC).
etcd는 RAFT를 사용하여 하나의 리더만이 모든 요청 작업을 수행한다.
어떤 노드로 접근을 하더라도 결국 모든 작업은 리더로 전달될 것이다.
이를 통해 클라의 모든 요청이 순서대로 이뤄지는 선형성(linearability)을 만족하기에 데이터의 정합성을 보장받을 수 있게 된다.
조금 더 자세한 내용은 [[#심화 raft]]에서 다루겠다.
저장 방식
etcd는 내부적으로 Bbolt를 사용한다.
Bbolt는 bolt라는 데이터베이스를 Go 커뮤니티에서 집중 관리하기 위해 포크를 따서 만들어졌는데, bolt는 또 LMDB(Lightening Memory-mapped DataBase)라는 메모리 매핑 데이터베이스로부터 영감을 받아 만들어진 키값 쌍 경량 데이터베이스이다.[2]
스토리지 저장 영역은 이 bolt가 수행하며, etcd는 그 위에서 추상화 계층으로서 고급 기능에 대한 인터페이스를 제공한다.
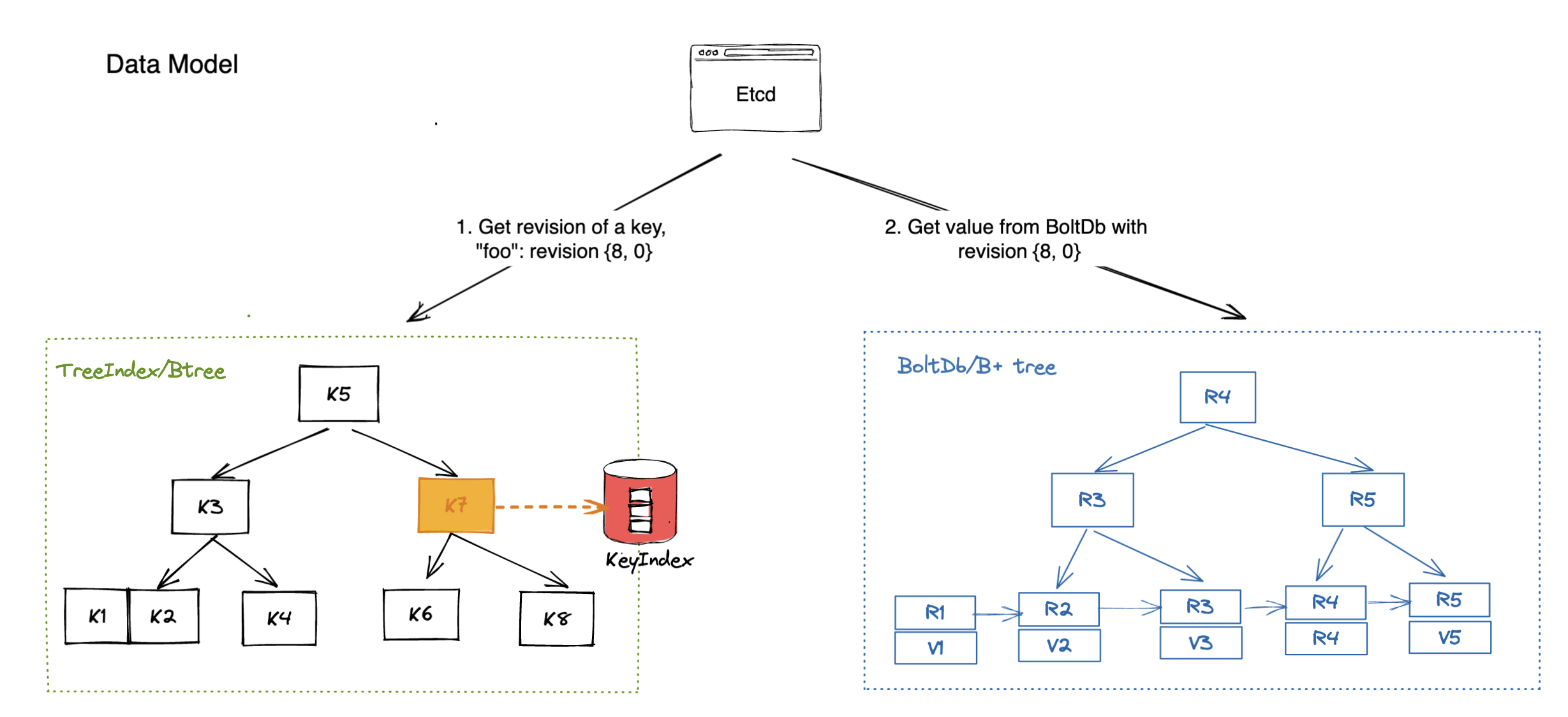
etcd의 데이터 모델은 기본적으로 이런 식으로 생겼다.
일단 물리적인 스토리지에 b+tree 형태(오른쪽 그림)로 데이터를 저장하며, 이 영역은 하나의 리비전으로 관리된다.
그 단에 각 키들이 비플트리 형태를 지니고 있으면서 이전 버전에 대한 정보도 각각 가진다.
이렇게 여러 버전을 동시에 가지고 있는 방식을 MVCC(Multi-Version Concurrency Control) 매커니즘이라고 부른다.
한 값에 실제로 접근할 때는 사용되는 정보는 크게 세가지이다.
- major - 현재 리비전 정보
- sub - 해당 리비전 내의 키의 버전 정보
- type - 특별 접두사
이렇게 접근한 한 키의 값에는 이전 리비전으로부터의 변경사항만이 저장되어있어 공간 소모를 줄인다.
그래서 실제 데이터를 불러오는 과정은 현재 버전의 변경사항과 이전 버전을 불러와 합쳐서 보여주는 방식이다.
하지만.. 이런 방식은 딱 봐도 데이터를 조회하는 과정이 매우 느릴 것으로 생각된다.
그래서 추가적으로 데이터를 빠르게 조회할 수 있도록 etcd는 인메모리로 Btree 인덱스를 가지고 있다.
실제로 데이터를 조회할 때, 필요한 데이터를 인덱스를 기반으로 빠르게 가져와 볼 수 있도록 돕는다.
참고로 etcd의 물리 저장 공간은 8기가 미만으로 사용될 것이 강력하게 추천된다.[3]
물리 공간에서 데이터를 효율적으로 불러오기 위한 구조로 인해 발생하는 제한이다.
그래서 실제 스토리지 사용량이 8기가를 넘으면 경고를 띄우면서 읽기 전용으로 전환된다..
이런 구조를 가지고 있으니 쿠버네티스에서 활용할 때, 사용되지 않는 리소스는 가급적 빠르게 지워주는 것이 좋다.
쓰지도 않고 있는 컨피그맵이 계속 남아있다던가 하는 것은 결코 좋은 방식이 아니다.
최소한 컨피그맵은 변경이 덜 하니 용량을 많이 잡아먹진 않겠지만, 메타데이터에 변경이 많이 발생하는 서비스나 파드의 경우에는 치명적일 수도 있다.
심화 raft
etcd는 단순한 raft 방식은 아니다.
일단 첫번째로, 리더 노드는 커밋 과정에서 정족수의 동의를 얻지 못하면 리더직을 빠르게 내려놓는다!
보통이라면 리더직을 내려놓지 않고 계속 하트비트를 보내면서 동의를 얻을 때까지 점차 데이터를 쌓아나가게 되는데 etcd에서는 커밋이 되지 못하는 행위가 생기면 빠르게 리더를 다시 선출할 수 있도록 만든다.
이 방식은 리더가 단절됐을 때 리더 스스로 데이터를 쌓아나가지 않도록 하는 이점도 있고, 클러스터의 장애 상황을 기민하게 대처하는 데에도 도움이 된다.
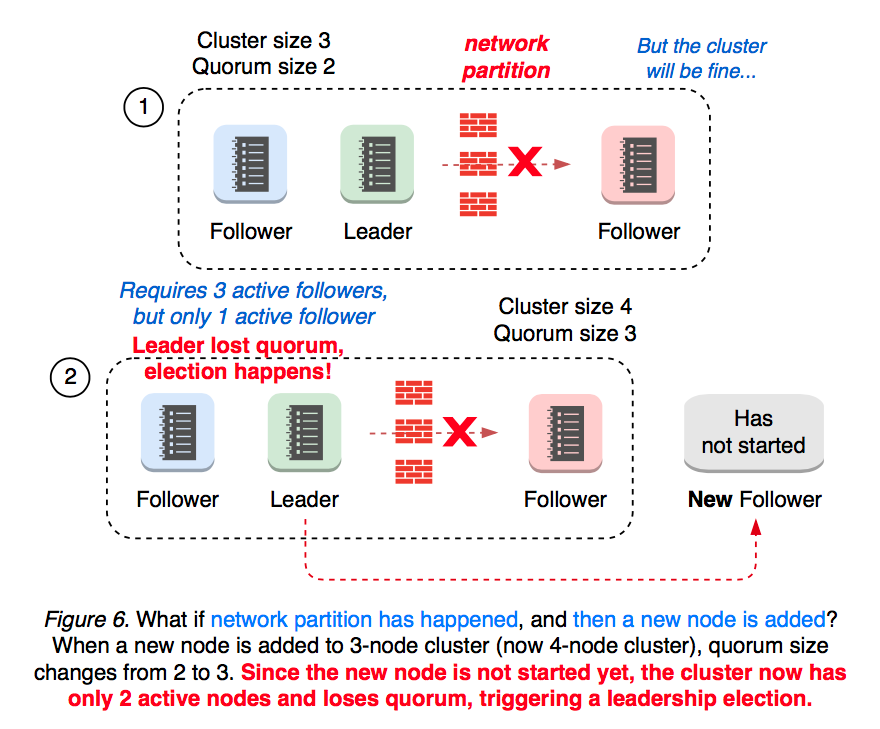
근데 이 방식이 가지는 문제가 무엇이냐, 노드를 추가하는 상황에서 큰 이슈가 발생할 수 있다.
3개의 노드가 있는 상황에서 팔로워 하나가 단절됐다.
정족수는 2이므로 일단 리더는 잘 동작하는데, 이때 이걸 대응하겠답시고 새로운 팔로워를 추가하는 상황을 생각해보자.
그럼 정족수는 3이 되어버리고, 팔로워가 리더의 로그를 받아 현재 버전의 로그까지 복제받는 동안 팔로워는 리더의 커밋 요청을 거절한다.
그럼 리더는 정족수를 충족하지 못해 스스로 리더직을 사퇴하고, 클러스터는 리더 없이 붕괴..
그래서 etcd에서는 노드를 추가할 때 반드시 문제가 있는 노드를 먼저 제거한 후에 팔로워를 추가하도록 당부한다.
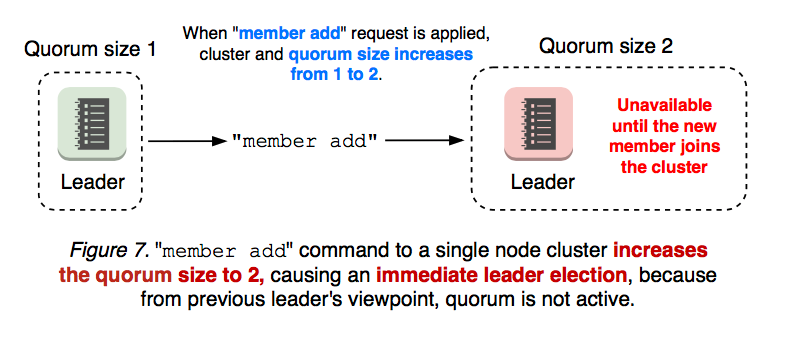
근데 그래도 해결 못하는 이슈가 있다.
하나짜리 클러스터인데 여기에 한 노드를 추가하는 과정에서는 어떤 노드를 빼고 자시고 위 케이스처럼 그냥 리더가 없는 상태가 지속되어버린다.
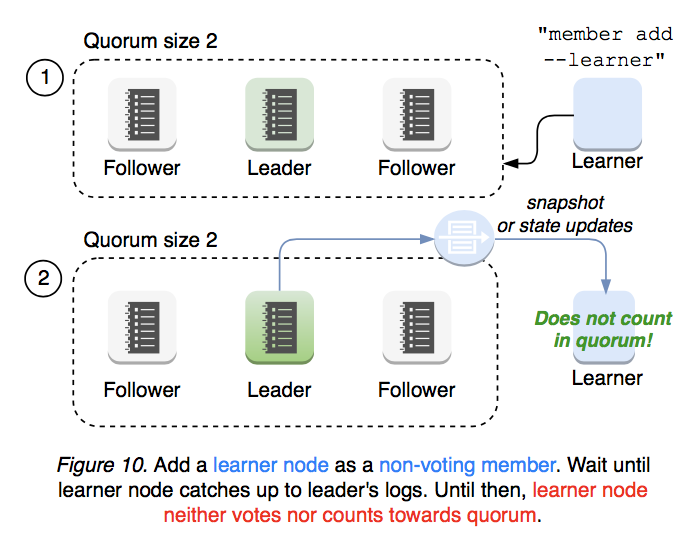
이를 해결하기 위해 등장하는 것이 바로 learner 노드이다.[4]
러너 노드는 일단 클러스터에 합류를 할 수 있지만, 투표도 할 수 없고 정족수에 영향을 주지도 않는 노드이다.
이 노드가 추가되면 리더는 여태 클러스터의 로그 사항을 전달해주기만 한다.
러너는 그냥 열심히 로그를 받으면서 현재 클러스터 상태를 따라가기만 해야 한다.
이게 위에서 말한 상황을 해결할 수 있는가?
러너는 완전히 클러스터의 상태를 따라가게 된 경우에만 팔로워가 될 수 있다.
노드가 하나인 클러스터에서, 러너는 이제 클러스터의 모든 상태를 받은 상태이므로 팔로워가 될 때 리더의 하트비트에 응답을 할 수 있게 된다!
그렇기 때문에 러너는 팔로워가 되어 갑자기 클러스터의 정족수가 올라가는 상황에서 자신의 투표권을 온전히 행사할 수 있어서 그대로 클러스터가 안전하게 유지될 수 있는 것이다.
재해 복구 - 스냅샷
etcd는 다양한 문제로부터 가급적 자동적인 복구를 할 수 있도록 설계됐다. 링크
그러나 한번 정족수를 상실하는 시점부터는 RAFT 상으로 리더를 선출할 수가 없기에 etcd 클러스터는 자체적인 복구가 불가능해진다.
복구된 것처럼 보여도 하나의 머리만이 유지될 것이라 보장도 할 수 없다.
이런 경우에는 정상적이었던 시점으로 etcd를 되돌리는 선택이 최선이다.
이때 기존에 스냅샷을 떠두었다면 이를 활용해 해당 리비전 시점으로 되돌아갈 수 있기에 주기적으로 etcd를 백업(스냅샷)해두는 것이 중요하다.
etcd를 아예 새로 구축해야 하는 케이스라면?
최적화
event api - 쿠버네티스 관련
쿠버네티스와 관련하여 최적화하는 기법을 소개한다.
Event api는 별도의 etcd 클러스터를 두고 운영하면 메인 etcd의 부하가 줄어들어 유용하다.
--etcd-servers-overrides=/events#https://0.example.com:2381;https://1.example.com:2381;https://2.example.com:2381
이런 식으로 옵션을 넣어주면 자주 발생하는 event 정보를 따로 관리할 수 있다.
이 방식은 etcd의 전체 용량을 개선하는 데에도 도움이 된다.
etcd의 스토리지는 기본 2기가를 사용하고, --quota-backend-bytes를 통해 최대 8기가까지 늘릴 수 있다.[5]
이 이상으로 넘어가면 성능이 급격하게 떨어지기에[6], 용량 초과 시 etcd는 쓰기가 불가능한 상태가 된다.[7]
데이터가 많이 발생하면서 로그성인 event를 별도로 관리하는 것은 etcd 관리에 매우 큰 도움이 된다.
3.6 버전
3.6.0 버전에서 메모리 소모에 50퍼 절감이라는 비약적인 개선이 이뤄졌다.[8]
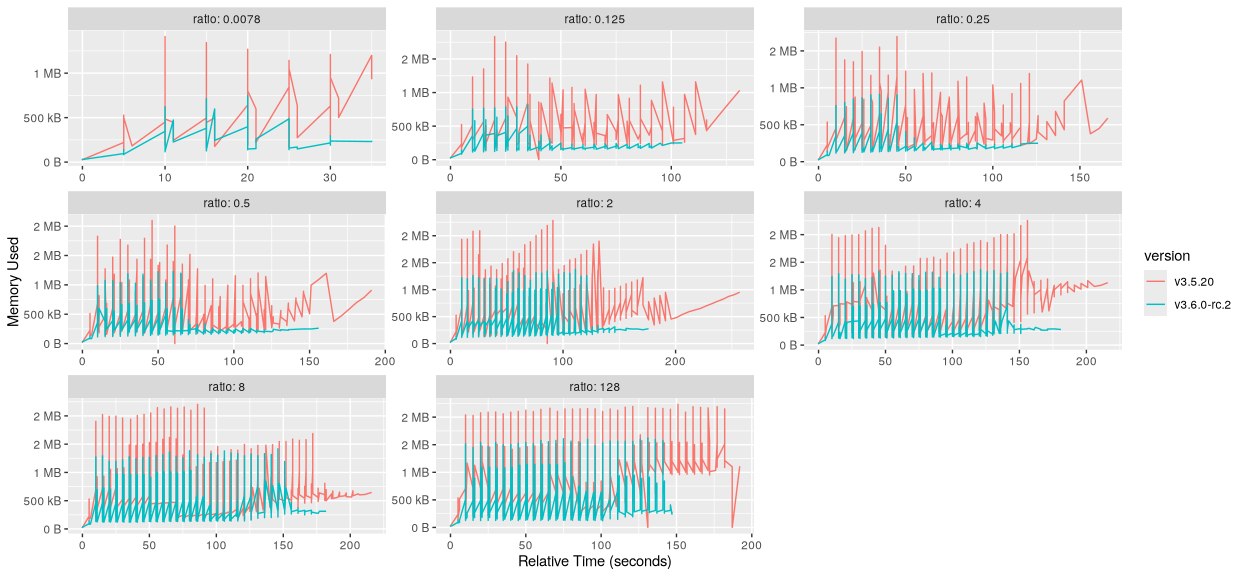
이는 스냅샷 히스토리 유지량을 10만개에서 만개로 줄이고, raft 히스토리를 더 자주 압축하여 이뤄진 성과이다.
여기에 처리량 역시 여러 업그레이드를 거치며 10퍼센트 가량 개선됐다.
관련 툴
etcdctl, etcdutl
etcd를 관리하는 커맨드 도구는 현재 두 가지이다.
기본적으로는 etcdctl로, 네트워크 통신을 통해 etcd에 접근해 관리를 수행한다.
v3가 나오며 생긴 etcdutl은 로컬 환경에서 etcd 파일에 바로 접근해 etcd 조작을 수행할 수 있다.
원래 두 명령어는 공유하는 기능들이 몇 가지 있었으나, 3.6.0 버전으로 올라오면서 완전히 분리됐다.[9]
과거에는 etcdctl snapshot을 통해 스냅샷을 뜰 수 있었으나, 이제는 불가능하다는 점에 유의하자.
etcd-operator
쿠버네티스 api를 기반으로 etcd를 관리하는 오퍼레이터.
25년 8월 기준으로 최근에 나온 모양인데, 조사가 조금 필요해보인다.[10]
관련 문서
| 이름 | noteType | created |
|---|---|---|
| ConfigMap | knowledge | 2025-01-12 |
| Etcd | knowledge | 2025-04-14 |
| 클러스터 성능 최적화 | knowledge | 2025-08-30 |
참고
https://aws.amazon.com/ko/blogs/containers/managing-etcd-database-size-on-amazon-eks-clusters/ ↩︎
https://github.com/ongardie/dissertation/blob/master/stanford.pdf ↩︎
https://aws.amazon.com/ko/blogs/containers/managing-etcd-database-size-on-amazon-eks-clusters/ ↩︎
https://kubernetes.io/blog/2025/05/15/announcing-etcd-3.6/ ↩︎