kube-proxy
개요
쿠버네티스의 코어 컴포넌트 중 하나로, 쿠버네티스 네트워크를 담당하는 한 요소이다.
구체적으로는 서비스에 대해 엔드포인트슬라이스를 추적 및 관리해주는 역할을 한다.
모든 노드에 설치가 되어 네트워킹이 원활하게 이뤄질 수 있도록 만들어준다.
이를 위해 흔히 데몬셋으로 배포가 된다.
기능
위에서 말한 그대로, 서비스에 백엔드를 연결하는 역할을 해준다.
클러스터에서 서비스를 통한 통신이 가능한 것은 바로 이 녀석 덕분이다.
근데 참고로 코어 컴포넌트라지만 딱 이 역할만 하기 때문에, 이 역할을 대체할 수 있는 모듈을 설치한다면 이 kube proxy는 쓸모가 없다.
가령 Cilium이라는 CNI는 cni 주제에 서비스 프록시 기능도 구현이 돼있어서 그 기능을 사용한다면 kube proxy를 지워도 된다!
동작 방식
자세한 내용은 서비스 - 가상 IP 매커니즘#kube-proxy를 통한 가상 IP 프록싱에 정리해두었다.
대충만 말하자면, kube-apiserver와 통신하면서 클러스터의 서비스와 엔드포인트 오브젝트를 감시하고, 이 정보를 바탕으로 노드에 iptables 규칙을 써준다.
추후에 문서 정리를 하며 이 문서와 통합할 수도 있다.
프록시 모드
동작 방식을 iptables로 설명했으나, 어떤 툴을 활용해 프록시 규칙을 설정할 것인가에 따라 몇 가지 타입을 세분화시킬 수 있다.[1]
각각의 차이를 깊게 보기에는 내 수준이 조금 얕고, 이해를 증진시키기 위한 차원에서만 설명한다.
iptables

리눅스에서만 가능한 모드로, 커널의 넷필터 subsystem에 있는 iptables API를 이용한다.
기본적으로 각 엔드포인트는 무작위 파드와 매칭된다.
iptables 최적화
kube-proxy에 대해서 몇 가지 설정들을 해주는 방식으로 부하 최소화를 통한 최적화를 꾀할 수 있다.
iptables:
minSyncPeriod: 1s
syncPeriod: 30s
iptables에서는 모든 서비스와 모든 엔드포인트에 룰이 추가된다.
1000개의 서비스와 엔드포인트가 있다면? 룰을 변경하고 적용하는데 시간도 오래 걸릴 것이다.
이때 위의 설정들을 하는 것이 도움이 될 수 있다.
minSyncPeriod는 재동기화를 하는 최소 기간을 지정한다.
이 값이 0이면 서비스가 생기거나 바뀔 때마다 프록시는 값을 반영한다.
짧게 많이 서비스를 수정하는 경우 부하가 걸리게 될 것이다.
또 100개의 파드를 관리하는 디플을 없앤다고 한다면, 이 기간이 조금 여유가 있으면 룰을 수정할 때 한꺼번에 수정하게 돼서 부하가 줄어든다.
그래서 오히려 부하가 줄어들어 결과가 빠르게 반영되게 될 수도 있다.
물론 이 값이 크면 동기화에 걸리는 텀이 길어지니 안 좋을 수 있다.
기본 값은 1초이며, 규모가 큰 클러스터에서는 조금 더 큰 값이 필요할 수도 있다.
프록시 메트릭 중 sync_proxy_rules_duration_seconds라는 값의 평균이 1초보다 크다면 이 값을 늘리는 방향으로 효율화해보자.
syncPeriod 파라미터는 개별 서비스와 엔드포인트의 변경과 직접적으로는 관련 없는 동기화 작업을 제어한다.
구체적으로는 프록시와 관련 없는 외부 컴포넌트의 개입이 일어난 것을 얼마나 빠르게 감지하는가에 대한 것이다.
큰 클러스터에서는 한번씩 불필요한 작업을 정리하는 시간이 필요하긴 하다.
대체로는 이게 큰 영향을 끼치지는 않는데, 과거에는 아예 1시간으로 설정하는 케이스가 있었다고 한다.
지금은 추천되지 않는데 이게 오히려 기능성에 영향을 주기 때문이다.
ipvs

사진으로는.. 뭐가 다른지는 잘 모르겠다.

리눅스에서 iptables에 ipvs를 얹어서 사용하는 방식.[2]
iptables 모드와 비슷하나, 커널 스페이스에서 동작하는 해시 테이블을 사용한다.
구체적으로는 iptables로 쓰여질 몇 가지 규칙들에 대해 테이블을 구성하여 바로 트래픽이 제대로 꽂힐 수 있도록 도와주는 것이다.
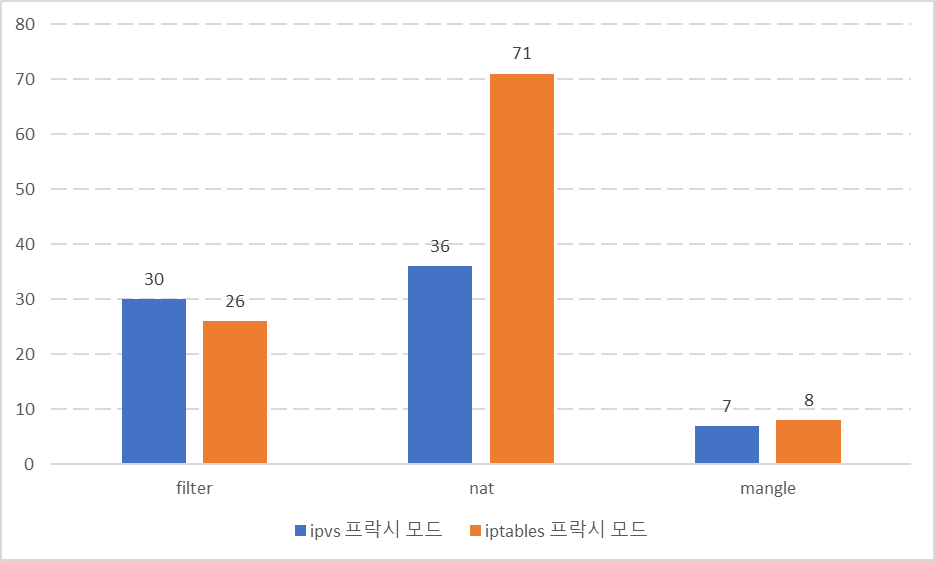
각 테이블의 규칙의 개수가 이렇게나 줄어들게 된다.[3]
규칙이 줄어드니 규칙 적용 속도도 올라가서 트래픽의 목적지로 패킷을 변환하거나 필터링이 빨라지는 것이다.
레이턴시는 줄어들고, 처리량은 늘어나고.
또 여기에 프록시 규칙 동기화의 성능이 올라간다.
구체적으로 다음의 이점이 있다고 정리할 수 있겠다.
- 규칙을 쓰는 속도 증가
- iptables는 규칙을 하나씩 계속 추가하다가, 변경이 필요하면 모든 리스트를 순차 조회하며 업데이트한다.
- ipvs는 해시 테이블 구조이기에 업데이트가 필요한 규칙들만 바로 접근하는 게 가능하다.
- 규칙에 따른 트래픽 처리 속도 증가
- 애초에 규칙의 개수가 적어지니 처리량이 많아진다.
- 다양한 라우트 밸런싱 옵션
- 이건 아래에 간단하게 나열해두었다.
이리 좋은! ipvs를 쓰려면 노드에서 먼저 ipvs가 가능하게 해야 한다.
이게 안 된 채로 프록시를 가동시키면 에러가 난다.
아직 많이 안 써봐서 확실치 않지만, ipvsadm, ipset를 쓰면 되는 것 같다.
기회되면 정리하겠다.
iptables를 사용하는 환경이라면 마이그레이션 부담도 적은 ipvs를 활용하는 것이 무조건 좋은 것 같다.
다만 iptables를 이용하지 않는 환경이(가령 eBPF) 늘어나는 추세라 크게 각광을 못 받을 수도 있을 것 같다.

ipvs를 따로 문서 정리하지 않을 것 같아 여기에 남겨둔다.[4]
트래픽 밸런싱
ipvs는 라우팅 옵션을 다양하게 설정할 수가 있다.
이런 상세한 커스텀이 가능하다는 것도 큰 장점이라 할 수 있겠다.
내용이 많아서 닫아둔다.
트래픽을 밸런싱하는 다양한 옵션을 제공한다.
- rr - Round Robin
- 뒷단 서버에 공평하게 트래픽이 분배된다.
- wrr - Weighted Round Robin
- 가중치를 두고 트래픽을 분배한다.
- lc - Least Connection
- 적은 연결을 가진 서버에 트래픽이 간다.
- wlc - Weighted Least Connection
- 적은 연결을 가진 서버가 가중치를 더 가며, 이를 기준으로 분배된다.
- lblc - Locality based Least Connection
- 같은 ip 주소로부터 온 트래픽은 가능한 같은 서버로 연결한다.
- 그게 안 되면 적은 연결을 가지는 쪽으로 연결한다.
- lblcr - Locality Based Least Connection with Replication
- 같은 ip 주소로부터 온 트래픽은 가능한 같은 서버로 연결한다.
- 모든 서버가 과부하가 걸리면, 그나마 적은 곳을 타겟 집합으로 지정한다.
- 일정 시간 동안 집합에 변경사항이 없다면 높은 수준의 복제를 피하기 위해 부하가 큰 서버가 세트에서 제거된다.
- 이게 무슨 말인지 잘 모르겠다.
- sh - Source Hashing
- 들어온 ip 주소 기반으로 해시 테이블 기반으로 분배된다.
- dh - Destination Hashing
- 목적지 ip 주소 기반으로 해시 테이블 기반으로 분배된다.
- sed - Shortest Expected Delay
- 가장 적게 지연될 것 같은 곳으로 분배한다.
(서버에 연결된 커넥션 수 + 1) / 고정된 서버 가중치로 예상 지연 시간을 구한다.
- nq - Never Queue
- 빠른 서버를 기다리는 대신, 유휴 서버로 일단 트래픽을 보낸다.
- 모든 서버가 바쁘다면 sed랑 똑같이 작동한다.
- mh - Maglev Hashing
- 마글레브 해시 알고리즘을 사용한다.
- 이게 뭔지는 좀 알아봐야 할 듯..
nftables
5.13 커널을 가진 리눅스 노드에서만 가능하며, nftables api를 사용한다.
iptables의 후속자로, 조금 더 좋은 성능과 유연성을 가지고 있다.
엔드포인트를 바꾸는 등 작업에 더 효율적이고, 커널 단의 패킷 처리도 더 빠르다고 한다.
그러나 수만 개의 서비스가 있는 클러스터 정도는 돼야 눈에 띈다고 한다.
Kubernetes v1.32 - Penelope에서도 아직 새로운 모드에 속하는 정도라, 클러스터에서 사용하는 CNI 플러그인이 이를 지원하는지는 확인이 꼭 필요하다.
iptables로부터 마이그레이션
마이그레이션을 할 때 조금 알아야 할 사항들이 있다.
- 노드포트 인터페이스
- 원래 노드포트 서비스는 모든 로컬 ip에서 접근이 가능하나, 여기에서는
--nodeport-addresses primary이다. - 즉, 기본 ip 주소일 때만 접근이 가능하다.
--nodeport-addresses 0.0.0.0/0으로 설정하면 똑같이 작동한다.
- 원래 노드포트 서비스는 모든 로컬 ip에서 접근이 가능하나, 여기에서는
127.0.0.1인 노드포트 서비스- 원래는
--nodeport-addresses의 범위가127.0.0.1를 포함하면, localhost를 통해 접근이 가능하지만 여기에선 그렇지 않다. - 만약 문제가 발생하면
iptables_localhost_nodeports_accepted_packets_total메트릭을 확인해 이런 접근이 있는지 확인하라.
- 원래는
- 노드포트의 방화벽 상호작용
- 원래 프록시는 방화벽을 잘 통과한다.
- 원하는 포트에 인바운드 트래픽 규칙을 추가해 방화벽에 안 걸리게 만드는 것이다.
- nftables를 쓸 때는 노드포트 범위의 값을 잘 허용하는지, 직접 확인하여 설정해야 한다.
- Conntrack 버그 해결책
- 6.1 버전 이전 커널은 오래 이어지는 tcp 연결에 대해 "Connection reset by Peer" 에러를 띄운다.
- iptables는 이 에러를 해결하는 조치를 취하나 이것의 문제점이 추후 발견됐다.
- 그래서 nftables는 이러한 조치를 취하지 않는다.
- 만약 프록시에
iptables_ct_state_invalid_dropped_packets_total메트릭이 발견된다면,--conntrack-tcp-be-liberal옵션을 추가하라.
kernelspace
윈도우에서 사용되는 모드인데, 윈도우 네트워크를 잘 몰라 매우 간략하게..
kube-proxy는 윈도우 vSwitch의 확장인 VFP(Virtual Filtering Platform)를 사용하게 된다.
노드 레벨의 가상 네트워크에 대해서 작업을 진행하고, DNAT를 해준다.
프록시에서 다른 노드의 파드로 가는 규칙을 쓰게 된다면, 윈도우의 HNS(Host Networking Service)가 응답패킷들이 잘 돌아올 수 있도록 보장해준다고 한다.
관련 문서
| 이름 | noteType | created |
|---|---|---|
| Service | knowledge | 2024-12-29 |
| 서비스 - 가상 IP 매커니즘 | knowledge | 2025-01-02 |
| kube-proxy | knowledge | 2025-02-12 |
| 1W - 실리움 기본 소개 | published | 2025-07-19 |