컨테이너 프로브
개요
프로브는 컨테이너에 대해 kubelet이 주기적으로 수행하는 진단이다.
kubelet은 정의된 스펙에 따라 컨테이너 내부에 특정 코드를 실행하거나, 네트워크 요청(컨테이너의 내부 네트워크 네임스페이스에서)을 날려준다.
다시 말해, 그냥 컨테이너의 헬스체크를 하는 기능이 바로 프로브이다.
배경
프로브가 있는 이유는 당연히 컨테이너의 상태를 판단하기 위해서이다.
아무런 설정이 없다면, 컨테이너의 상태는 사실 딱 두 가지일 뿐이다.
실행되고 있거나, 실행되지 않고 있거나(종료든, 시작하기 전이든).
하지만 운영 레벨에서 컨테이너가 실행되고 있다라는 사실은 극히 작은 정보에 불과하다.
운영 레벨에서 컨테이너는 사실 다음의 상태들도 가질 수 있다.
- 초기화 - 제대로 프로세스가 제 기능을 하기 전까지 초기화 세팅이 진행되는 중일 수 있다.
- 오동작 - 프로세스가 기대한 기능을 수행하고 있지 못한 상태일 수 있다.
- 웹 서버의 경우, 요청이 너무 많이 몰려서 추가적인 요청을 제대로 수행할 수 없는 상태일 수 있다.
프로세스가 돌아가고 있는 상태더라도 무조건 정상적인 상태가 아닐 수 있다는 것이 핵심이다.
그래서 프로세스가 정상적으로 동작을 수행할 수 있는 상태인지를 알기 위한 추가 정보를 얻기 위해 세팅하는 것이 프로브이다.
사용자가 직접 어떤 동작을 명시만 해두면 kubelet이 해당 동작을 수행하면서 관련한 정보를 파드의 상태에 표시해준다!
이것을 통해 컨테이너 상태를 체크하고, 파드가 준비되었는지, 시작되었는지의 여부를 결정지을 수 있다.
종류
쿠버네티스에는 3 가지 종류의 프로브가 존재한다.
라이브네스 프로브(livenessProbe)
컨테이너가 실행 중인지 진단한다.
이게 실패하면 kubelet은 컨테이너를 죽이고 파드 속 컨테이너의 장애#재시작 절차에 들어간다.
명시되어 있지 않다면 성공으로 간주된다.
용례
컨테이너가 돌아가는 중에 oom과 같은 이슈가 발생할 수 있다.
이때 이게 설정되어 있으면 컨테이너의 장애를 확인하고 재시작 정책을 적용할 수 있다.
가용성 확보에 유용한 것이다.
참고로 컨테이너가 알아서 죽거나 크래시가 나는 케이스에 대해서는 그다지 사용할 필요가 없다.
이것은 내가 실패라고 간주하길 바라는 케이스를 적어주는 것이다.
실습
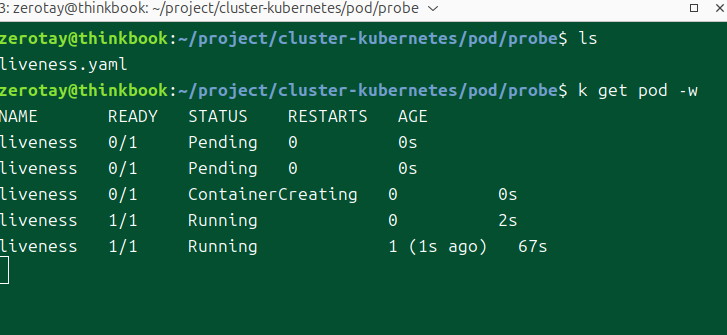
시작하고 20초 후에 실패하는 코드를 작성했다.
3번의 시도 끝에 파드는 컨테이너가 죽었다고 판단하고 재시작을 했다.
레디네스 프로브(readinessProbe)
준비 상태 프로브라고 부르면 적당할지도..
E-레디네스 프로브와 레디네스 게이트에서 나온 프로브.
요청을 수행할 준비가 되었는지 판단하는 프로브로, 실질적으로 가장 중요한 놈이라 할 수 있겠다.
이게 실패하면 EndpointSlice 컨트롤러에서 해당 파드의 ip를 제거된다.
간단하게 말하자면 앞단의 Service에서 현재 이 파드가 준비되었나 아닌가를 판단하는데 사용된다 말할 수 있겠다.
기본 지연 시간은 존재하지 않고, 명시되지 않는다면 성공으로 간주된다.
장애가 생긴 파드로 트래픽을 보내지 않도록 만든다는 점에서 서킷 브레이커 기능이라고 말할 수 있다.
용례
서비스 장애가 발생하지 않도록 안전이 확보된 상태에서 엔드포인트 설정이 완료되길 바란다면 이게 필수다.
레디네스는 컨테이너를 재시작하지 않는다.
그래서 그냥 한 파드를 죽이는 것은 아닌데 잠시 서비스에서 제외시키고 싶을 때 활용하는 것도 가능하다.
가령 대용량 데이터나 파일을 처리하게 되는 파드가 있을 수 있다.
그러면 이걸 잠시 실패하게 해서 그 작업만 처리하도록 만들어주는 것이다.
만약 앱이 다른 백엔드 서비스에 의존하고 있다면, 뒷단의 서비스가 사라졌다고 이 앱까지 재시작될 필요는 없을 것이다.
이럴 때도 레디네스로 처리하는 것이 좋다.
스타트업 프로브(startupProbe)
시작 프로브
컨테이너가 시작됐는지 진단한다.
다른 모든 프로브는 이 프로브가 성공이 뜰 때까지 작동하지 않는다.

이게 실패하면 kubelet은 컨테이너를 죽이고 파드 속 컨테이너의 장애#재시작 절차에 들어간다.
즉, 잘못하면 그냥 다른 시작을 할 새도 없이 컨테이너가 재시작만 하는 상태가 되어버린다.
E-initialDelaySeconds가 아니라 스타트업 프로브가 필요한 이유에 대한 고민이 들 수 있으니 참고.
failureThreshold를 잘 걸어주자.
명시되어 있지 않다면 성공으로 간주된다.
용례
이름따라 시작 상태에 대해 유용하다.
다른 프로브들이 정상 작동하길 바라는데 어플리케이션 실행이 오래 걸리거나 불규칙하다면 이것을 적용해서 컨테이너 시작이 보장된 상태에서 다른 프로브들이 작동하도록 만들어준다.
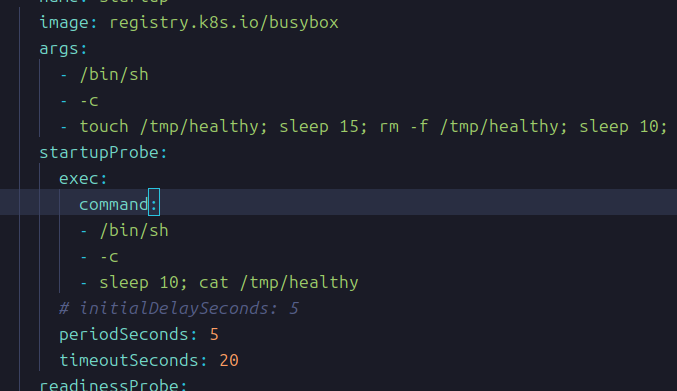
이건 그냥 10초를 기다려서 바로 ready가 됐어야 하는 상태를 늦춘 예시.
용례
각각은 그렇게 사용하는데, 그럼 이들을 조화롭게 쓰려면 어떻게 해야 할까?
보통 레디네스 프로브에는 낮은 비용의 조건을 걸고 자주 사용한다.
그러는 한편 리브네스 프로브에는 높은 비용, 높은 임계치를 가진 조건을 건다.
이렇게 하면 잠시 서비스를 받을 수 없고 금방 복구될 예정인 앱이 무작정 재시작되어버리는 사태를 막을 수 있다.
그러면서 데드락 같은 돌이킬 수 없는 컨테이너는 재시작을 해버리는 것이다.
그리고 스타트업 프로브는 다른 프로브들이 시작되기 이전 적용되므로 언제 컨테이너가 시작됐는지 판단하는 근거로 사용된다.
내부의 자바 앱이 1초만에 켜질 때도 있고 5초만에 켜질 때도 있는데 이걸 잘 모르겠다면 일찌감치 스타트업 프로브를 걸어두면 된다.
리브네스는 가급적 최후의 보루로, 돌이킬 수 없는 상태가 되어버린 컨테이너에 대해서만 작동하도록 만드는 게 좋다.
자칫하면 컨테이너가 너무 많이 재시작되는 이슈가 생겨버릴 수도 있다.
이로 인해 앞단 서비스의 요청을 받을 파드가 줄어들어버릴 수도 있는 한편 실패 상태인 파드가 많아짐에 따라 워크로드에서 파드를 지나치게 많이 생성할지도 모른다.
매커니즘
다음의 4 가지 방법이 있으며, 프로브를 걸고 싶다면 이중에 하나로 명확하게 정의가 되어야 한다.
- exec
- 컨테이너 내부에 명령 실행.
- 종료 코드가 0이며 성공으로 간주된다.
- grpc
- gRPC 호출
- 당연히 해당 컨테이너에는 관련 코드가 구현되어 있어야만 할 것이다.
- 응답이
SERVING이 돌아오면 성공으로 간주된다.
- httpGet
- 특정한 포트와 경로로
GET요청 - 200~300의 응답이 돌아올 때 성공으로 간주된다.
- 특정한 포트와 경로로
- tcpSocket
- 특정 포트에 TCP 체킹
- 포트가 열려있다면 성공으로 간주된다.
- 커넥션이 열리고 바로 닫히더라도 성공이라고 간주된다.
- 그게 핑이니까..
다른 매커니즘과 다르게 exec은 새로운 프로세스를 만드는 행위가 수반된다.
그래서 클러스터 내부에 리소스 여유가 충분하지 않고, 프로브 주기를 짧게 두어버린다면 노드의 cpu 사용량이 크게 증가할 수 있다.
다른 매커니즘을 사용하는 것이 가급적 권장된다.
결과
- Success - 성공
- Failure - 실패
- Unknown - 진단 실패이기에 kubelet은 바로 추후 체크를 시도한다.
- 근데 이런 경우가 언제 발생하는지 아직 잘 모르겠다.