EndpointSlice
개요
The EndpointSlice API is the mechanism that Kubernetes uses to let your Service scale to handle large numbers of backends, and allows the cluster to update its list of healthy backends efficiently.[1]
엔드포인트슬라이스는 서비스를 확장해 대량의 백엔드를 다룰 수 있도록 해주며, 4.RESOURCE/KNOWLEDGE/Kubernetes/클러스터/클러스터가 효율적으로 건강한 백엔드 리스트를 업데이트할 수 있도록 돕는다.
서비스는 흔히 파드(파드에 한정된 건 아님)의 ip로 트래픽을 연결해주는데 이때 엔드포인트라는 것을 사용한다.
서비스의 입장에서 엔드포인트는 트래픽을 연결할 각 리스트인데, 이렇게 오브젝트를 분리하여 관리함으로써 위에서 말한 이점을 얻게 된다.
EndointSlice는 Endpoints의 후속자이다.
더 유연하고 확장성 있는 오브젝트로, [[#Endpoints]]에서 조금의 차이를 다루겠다.
엔드포인트란?
엔드포인트는 말 그대로 네트워크 엔드포인트, 즉 대상의 ip를 나타낸다.
서비스의 ip로 오는 트래픽은 이 엔드포인트들로 보내져서 결과적으로 통신이 이뤄진다.
한 서비스의 백엔드로 1000개의 파드가 있다고 생각해보자.
이들을 일일히 관리하는 것은 매우 어려운 일이기에, 이들을 한꺼번에 묶어 관리하는 오브젝트가 필요하며, 그것이 바로 엔포슬인 것이다.
기능
엔드포인트슬라이스는 그 이름답게 한 서비스의 소유되어 연결되는 백엔드 엔드포인트의 집합을 관리한다.
서비스에 대해 완벽히 하위 개념으로서 성립하다보니 소유권 역시 서비스가 가지고 있으므로, 서비스를 지우면 해당 엔포슬도 사라진다.
그래서 서비스의 라벨 셀렉터를 토대로 추가되거나, 없어져야할 엔드포인트를 관리하고, 각 엔드포인트의 상태를 관리하기도 한다.
그래서 다음의 기능을 추릴 수 있을 듯하다.
- 엔드포인트 집합 관리
- 서비스의 라벨 셀렉터 조건에 맞는 백엔드의 엔드포인트를 찾고, 이에 맞춰준다.
- 프로토콜, 포트 번호 및 서비스 이름의 고유한 조합을 통해 네트워크 엔드포인트를 그룹화해준다.
- 엔드포인트에 대한 정보들을 담는다.
- 상태를 업데이트하여 트래픽을 라우팅할 근거를 제공해준다.
특징
엔드포인트슬라이스에는 엔드포인트를 담을 수 있는 최대 제한이 있다.
기본적으로는 100개의 엔드포인트를 관리할 수 있으나, kube-controller-manager에 --max-endpoints-per-slice 플래그를 이용해 최대 1000개까지도 늘릴 수 있다.
그럼 서비스의 백엔드가 100개가 넘어간다면?
엔드포인트슬라이스가 여러 개로 늘어난다!
대충 이러한 특징으로 정리할 수 있겠다.
- 서비스에 소유되는 1:다 관계
- 하나의 서비스는 여러 개의 엔드포인트슬라이스를 가질 수 있다.
- 엔드포인트를 담을 수 있는 양은 정해져 있다.
- 이를 넘으면 엔드포인트가 여러 개 만들어진다.
kube-proxy는 이 엔드포인트슬라이스 오브젝트를 감시하고, 내부 트래픽을 라우팅하는 규칙을 작성한다.
참고로 이 엔포슬 덕분에 서비스는 듀얼스택과 토폴로지 기반 라우팅이 가능하다.
엔드포인트슬라이스 분산 방식
엔드포인트슬라이스는 여러 개로 분산될 수 있다는 것이 큰 특징인데, 구체적으로는 어떻게 분산될까?
분산되는 경우
먼저 새로운 엔드포인트슬라이스가 생성되는 경우, 즉 엔포슬이 여러 개가 되는 경우는 다음과 같다.
- 엔드포인트가 한도를 넘어 하나의 엔포슬에 담을 수 없음
- ipv4, ipv6 등서비스가 지원하는 주소 유형(addressType)이 여러 개
- zone과 같은 토폴로지가 여러 개
- 파드의 포트가 여러 개
마지막 경우에 대해 조금 보충을 하자면, 각 엔포슬은 자신이 관리하는 모든 엔드포인트에 적용되는 포트 그룹을 가지고 있다.
이 포트는 엔드포인트 측에 적용되는 포트로, 서비스에서는 .spec.ports[].targetPort에 해당하는 부분이다.
우리는 서비스에 같은 라벨로 엮인 모든 파드가 같은 포트를 가지고 있을 것이라 생각하지만..
서비스 포트 작성법을 보면, 파드에 있는 포트 이름으로 엮을 수도 있다.
즉 잘 생각해보면, 파드마다 같은 이름의 포트를 쓰는데 막상 연결되는 포트는 다를 수도 있다!
이런 경우에도 엔포슬은 여러 개로 분산된다는 것이다.
분산 로직
엔드포인트슬라이스 컨트롤러가 엔포슬에 엔드포인트를 채우는 역할을 하는데, 이 친구가 추가 엔포슬을 만들던가, 없애던가를 담당한다.
그런데 이때 슬라이스간 균형을 잡아주지 않아서 엔포슬 간 엔드포인트 보유량에 격차가 생길 수 있다.
구체적으로는 다음과 같은 로직을 거친다.
- 현재 존재하는 엔포슬들을 순회하며, 더 이상 필요없는 엔포를 제거하고, 엔포의 상태나 매칭된 것을 업데이트한다.
- 위 단계에서 자리가 생긴 엔포슬들을 순회하며 새로운 엔드포인트를 넣는다.
- 그럼에도 추가할 엔드포인트가 남았다면, 변화가 생기지 않은 엔포슬에 추가하거나, 새로운 엔포슬을 만든다.
중요한 건 세번째 단계에서 엔드포인트슬라이스가 업데이트되는 개수를 최대한 적게 하려고 한다는 것이다.
가령 두 개의 엔드포인트슬라이스에 각각 5개 정도의 여유 공간이 남아있다고 쳐보자.
이때 10개의 엔드포인트가 추가돼야 하는 상황이 오면 컨트롤러는 그냥 하나의 슬라이스를 새로 만들어버린다..
모든 노드의 kube-proxy가 Etcd에 저장된 엔포슬의 변경, 추가를 추적하고 있으며 변경되는 엔포슬이 많을수록 부하가 커진다.
그래서 엔포슬이 꽉꽉 차지는 않더라도 변경사항을 가급적 늘리지 않는 방향으로 설계된 것이다.
문서를 보며 해석의 여지가 조금 있는 설명이라 생각했다.
첫 순회에서 변화가 생긴 엔포슬을 찾는다고 하는데, 그럼 순회를 돌리고 있는 와중에 엔드포인트를 쑤셔박나?
아니면 첫 순회에서 엔포슬을 리스트업하고나서 이를 다시 순회 돌리며 엔드포인트를 삽입할까?
굳이 이러고 싶지는 않았는데.. 궁금한 건 참을 수가 없다.
I-EndpointSlice 분산 로직 분석에 내용을 담았는데, 정답은 후자다.
전체 로직을 보면 최대한 엔드포인트슬라이스를 많이 수정하지 않도록, 어차피 업데이트될 놈들 최대한 재활용하고자 노력한다.
실질적으로 불균형이 많이 일어나진 않을 것이다.
어차피 엔포슬 컨트롤러가 일으키는 대부분의 변경사항은 기존 슬라이스을 활용할 수 있을 만큼 작은 편이기 때문이다.
E-디플로이먼트 조작#디플로이먼트 업데이트를 할 때도 가급적 교체되는 파드의 엔드포인트를 원래 쓰이던 엔포슬에 그대로 두는 식으로 동작한다.
중복 엔드포인트
엔드포인트슬라이스의 변경 원리 덕에 한 엔드포인트가 한 개 이상의 엔드포인트슬라이스에 담기는 일이 발생할 수 있다.
서로 다른 엔포슬 오브젝트에 대한 변경사항이 이를 감시하려는 클라이언트에 각각 다른 시간대에 도착할 수도 있기 때문이다.
이런 이슈를 방지하기 위해 엔포슬을 감시하는 클라이언트(kube-proxy)는 존재하는 모든 엔포슬을 반복적으로 계속 추적한다.
이 부분이 궁금하다면 kube-proxy 코드에서 EndpointSliceCache 코드를 보라는데, 이것까지 보지는 않겠다..!
양식 작성법
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-abc # 접두사로 담당 서비스의 이름을 관례적으로 붙인다.
labels:
kubernetes.io/service-name: example # 이걸 꼭 명시해서 서비스와 매칭되게 한다.
addressType: IPv4
ports:
- name: http # 이 이름도 서비스에 있는 포트 이름과 일치해야 한다.
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
nodeName: node-1
zone: us-west2-a
이것은 example이라는 서비스의 엔포슬의 예시이다.
구조를 보면 알겠지만, 특정 주소 유형을 가진 포트 그룹에 대한 엔드포인트들을 관리하는 방식이다.
labels

.metadata 하위의 필드로 흔히 아는 라벨 셀렉터이긴 하다.
kubernetes.io/service-name={서비스이름}를 통해 서비스와 매칭이 된다.
이밖에도 조금은 알아야 할 사항들이 있다.
보통은 컨트롤 플레인, 구체적으로 엔드포인트슬라이스 컨트롤러가 엔포슬 오브젝트를 만든다.
근데 이 엔포슬이란 것이 서비스 메시 구현 등으로 다른 컨트롤러에 의해 만들어지는 등의 용례가 있다.
그래서 다른 컨트롤러 간 관리하는 엔포슬이 충돌하지 않도록 endpointslice.kubernetes.io/managed-by 필드가 추가적으로 있는 것이다.
기본 컨트롤러는 endpointslice-controller.k8s.io로 설정돼있다.
addressType
엔포슬은 IPv4, IPv6, FQDN(Fully Qualified Domain Name) 중 하나의 주소 유형만을 가질 수 있다.
달리 말하자면, 어떤 서비스가 ipv4, ipv6 듀얼스택을 처리할 수 있다면 해당 서비스는 두 개의 엔포슬을 가지고 있다는 것이다.
ports
연결되는 서비스에 있는 포트들의 정보가 들어가야 한다.
쿠버네티스에서 자동으로 만들어주는 엔포슬은 서비스에 명시된 모든 포트 정보가 거의 그대로 들어가게 된다.
endpoints
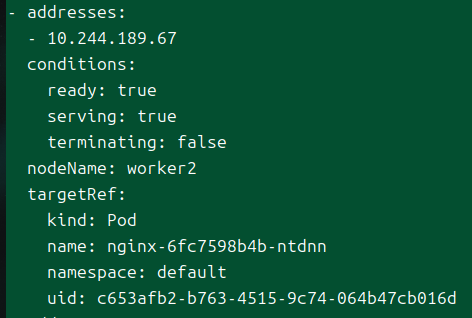
엔드포인트들은 이 필드 아래 리스트로 관리된다.
여기에 담길 수 있는 정보들을 가볍게 정리했다.
conditions
엔포슬은 자신이 관리하는 엔드포인트들의 상태를 추적하고 관리한다.
그렇게 엔드포인트의 건강 상태를 체크하고 트래픽을 보낼 수 있을지 결정할 수 있는 것이다.
구체적으로는 아래의 3가지 상태를 담는다.
ready
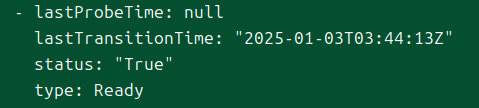
파드의 .status.conditions에 Ready 타입과 매핑되는 값이다.
서비스에 .spec.publishNotReadyAddresses=True라면 파드 상태에 관련 없이 항상 true로 설정된다.
기본적으로는 파드가 종료 중일 때 true가 되지 않는다.
종료 중인 파드에 대한 준비 상태는 아래 serving을 이용하자.
serving
거의 위의 ready와 다를 게 없지만, 종료 중인 파드에 대해서도 true라고 설정된다는 것이 다르다.
다른 문서에서도 다뤘는데 이 값은 기존의 ready라는 의미를 해치지 않기 위해 1.20 버전부터 새롭게 도입된 개념이다.
가령 종료 중이라고 표시된 파드라고 해도 Finalizer 등을 통해 아직 정상 기능을 하고 있을 수 있는데, 이럴 때 활용할 수 있다.
terminating
파드에 .metadata.deletionTimestamp가 설정됐으면 이 값이 true가 된다.
가비지 컬렉션이 해당 필드를 참조하는 방식이라 실질적으로 그냥 파드가 종료 중인 상태라고 보면 되시겠다.
토폴로지 정보
각 엔드포인트는 관련된 토폴로지 정보를 담을 수 있다.
즉 존재하는 노드라던가, 리전, 존 등의 정보가 담긴다는 것이다.
- nodeName
- zone
과거에는 topology 필드가 아예 따로 있어서 관리자가 임의의 값을 넣을 수 있었던 모양인데, 이제는 두 개의 고정된 필드만이 가능하도록 바뀌었다.
그래도 과거와 어느 정도 호환성이 있어서 가령 topology.kubernetes.io/zone이라는 키 값은 알아서 zone 필드로 바뀌어서 저장된다고 한다.
Endpoints - 과거의 잔재..
엔포슬이 있기 전까지는 Endpoints라는 오브젝트로 서비스의 엔드포인트들을 관리했다.
거의 원시형으로, 엔드포인트의 집합체라는 기본 기능만을 가지고 있었다.
그러나 클러스터 규모가 커짐에 따라 엔드포인트 개수도 늘어났고, 이에 따라 운영의 어려움들이 생겨나서 현재의 엔포슬로 대체됐다.
엔포슬이 나옴으로써 듀얼스택과 토폴로지 기반 라우팅까지도 가능하게 됐으니, 이제는 엔포슬만 알면 되긴 한다.
참고로 Endpoints 오브젝트는 쿠버네티스 오브젝트 중 몇 안 되는 복수형이다!
그래서 한글로 표현하면.. 엔드포인츠라고 해야겠지만, 보통 한국어로 음차할 때는 복수형을 생략하므로 그대로 간다.
그럼에도 이 절 한정으로 명시적으로 endpoint와 Endpoints를 구분하기 위해 엔드포인츠라고 적겠다.
비교
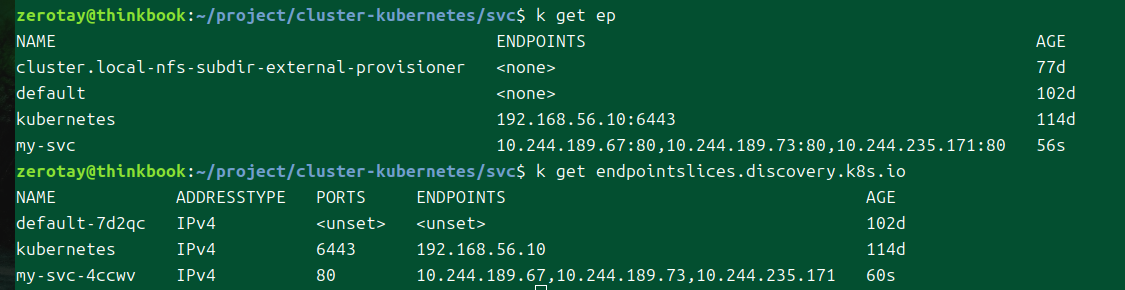
엔드포인츠와 엔드포인트슬라이스에 대해 get을 날리면 나오는 결과.
비교점을 정리해보자.
- 최대 허용량
- 엔드포인츠
- 엔드포인트를 1000개까지 담을 수 있다.
- 이 이상 넘으면
endpoints.kubernetes.io/over-capacity: truncated어노테이션이 붙는다. - 이는 가능한 허용치를 넘었다는 의미로 건강한 백엔드 1000개로만 라우팅이 동작하고 나머지 백엔드는 건강하더라도 무시된다..
- 엔포슬
- 기본값으로 100개를 담을 수 있으나 1000개로 늘릴 수도 있다.
- 개수가 더 많아지면 엔포슬 개수가 늘어난다.
- 엔드포인츠
- 엔드포인트 타입
- 엔드포인츠
- 서비스랑 1:1 관계라서 그냥 서비스에 엮이는 모든 엔드포인트를 담고 본다.
- 엔포슬
- 주소 유형, 토폴로지마다 각각의 엔포슬이 만들어져서 엔드포인트를 나눠 담는다.
- 엔드포인츠
하나의 오브젝트가 많은 엔드포인트를 가지고 있으면 생기는 문제는 역시 성능이다.
스케일링이 자주 일어나는 백엔드를 가진 서비스는 엔드포인트 변동이 많다.
이때 주소가 많은 오브젝트에 대해서 업데이트가 일어날 때 대량의 트래픽이 발생하게 된다.
심지어 이 주소 간에 통일성도 없어서 cpu 연산은 많아진다.
미러링
엔드포인츠는 한물갔다고는 하나 아직까지도 api가 남아있기는 하다.
그래서 쿠버네티스에서는 엔드포인츠를 미러링하여 같은 스펙의 엔드포인트슬라이스를 만들어준다.
이에 대한 몇 가지 예외 사항이 있다.
- 엔드포인츠 오브젝트에 라벨
endpointslice.kubernetes.io/skip-mirror=True - 엔드포인츠 오브젝트에 어노테이션
control-plane.alpha.kubernetes.io/leader - 대응되는 서비스 오브젝트가 존재하지 않음
- 대응되는 서비스가 있으나, 셀렉터가 없음
당연히 하나의 엔드포인츠에 대해 여러 엔드포인트슬라이스가 생길 수 있다.
일단 다양한 주소 유형(듀얼 스택 같은)을 품은 엔드포인츠이거나, 1000개가 넘어가는 엔드포인트를 가진 엔드포인츠라면 여러 집합이 생길 것이다.
관련 문서
| 이름 | noteType | created |
|---|---|---|
| EndpointSlice | knowledge | 2025-02-16 |
| I-EndpointSlice 분산 로직 분석 | topic/idea | 2025-01-03 |