Service
개요
Expose an application running in your cluster behind a single outward-facing endpoint, even when the workload is split across multiple backends.[1]
여러 개의 어플리케이션을 백엔드로 둔 채, 클러스터에서 단일 엔드포인트로 어플리케이션을 노출한다.
파드, 디플로이먼트과 더불어 쿠버네티스를 접할 때 처음으로 배우는 삼대장 오브젝트 되시겠다.
4.RESOURCE/KNOWLEDGE/Kubernetes/클러스터/클러스터 내부에서 고정된 ip와 로드밸런싱의 기능을 제공한다.
서비스라고 하니 프로젝트할 때 고객에게 무언가를 제공한다는 의미의 서비스 개념을 떠올리게 되는 측면이 없잖아 있다.
처음에는 헷갈리다보니 반감을 있었는데, 서비스 메시#용어 정리 - 어플리케이션과 서비스의 차이쪽을 참고하면 서비스란 표현이 조금 와닿는 측면도 있다.
요약하자면 어플리케이션에 네트워크적으로 접근할 수 있도록 하는 운영 상의 기능을 가리키는 표현으로 서비스를 칭하는 것이다.
백엔드라는 표현도, 웹 개발만 주구장창 해온 사람들에게 백엔드라 하면 WAS를 연상시키는 표현일 수도 있겠다.
그러나 사실 백엔드는 클라이언트의 트래픽이 도달하는(보이지 않는) 뒷단의 영역을 의미한다.
그래서 이 문서에서 백엔드는 트래픽이 연결될 뒷단의 파드를 의미한다고 보면 편할 것이다.
기능
서비스가 존재하는 핵심 이유는 복잡한 4.RESOURCE/KNOWLEDGE/Kubernetes/클러스터/클러스터 위에서 별도의 네트워크 경로를 찾는 과정(서비스 디스커버리)을 위해 줄이는 것이라고 할 수 있다.
이런 상황을 생각해보자.
웹 서비스를 프론트엔드와 백엔드를 나누어 구성했다.
각각 디플로이먼트를 통해 파드를 여러 개 둔 것이다.
근데 우리는 구체적으로 파드가 몇 개인지도, 몇 개가 현재 트래픽을 받을 상태인지도 잘 모르는 것이다.
이 파드들은 네트워크#파드에 나온대로 어떤 클러스터 ip를 할당받았을 텐데, 이걸 어떻게 찾아다닐 것인가?
각 파드의 ip를 명령어를 쳐가면서 추적할 수는 있겠지만... 매우 비효율적이다.
열심히 탐색해서 ip를 알았다고 쳐도, 만약 파드가 죽어서 재생성됐다면?
그럼 새로운 ip를 받았을 테니 또 ip를 탐색해야 한다..
그러면 이런 상황에서 도대체 어떻게 쉽게 프론트엔드 파드는 백엔드 파드와 통신할 수 있을까?
이때 서비스라는 객체를 만들어서 간편하게 복수의 파드에 접근할 수 있게 한다는 것이다.
그래서 구체적으로 서비스가 하는 기능을 두 가지 정도로 요약할 수 있는 것 같다.
- 클러스터 내외부적으로 활용할 수 있는 고정적인 ip 제공
- 느슨해진 클러스터 ip 세상에 긴장감을 부여해줍니다 ㄷㄷ
- 유동적일 수 있는 파드의 ip를 몰라도 되도록 한다는 것이 매우 중요하다.
- 여러 개의 파드로 가는 트래픽 로드 밸런싱
- 같은 기능을 하는 복수의 파드에 적절하게 부하 분산을 해준다.
서비스는 여러 그룹의 파드를 네트워크 상으로 노출시키는 하나의 추상화 계층이라고도 할 수 있다.
서비스는 단순화된, 네트워크 상에서 변하지 않는 경로를 제공해준다.
내부적으로는 여러 개의 논리적 엔드포인트를 정의하여 파드에 접근 가능한 정책을 만들어준다.
번외
네트워크 관련 오브젝트들이 몇 개 더 있는데, 이들을 활용해서 더 다양한 네트워크 기능을 사용할 수 있다.
가령 만약 HTTP 프로토콜을 사용하는 워크로드를 가지고 있다면, Ingress를 사용해 모든 웹 트래픽의 라우팅 규칙을 하나로 관리할 수 있다.
여기에 Gateway API를 통해 더 다양한 기능을 제공할 수 있다.
동작 원리
그래서 서비스라는 놈이 어떻게 움직인다는 것이냐?
사용법에 기반한 설명

기본적인 동작을 먼저 보자.[2]
서비스를 정의할 때는 라벨 셀렉터를 통해 백엔드로 두고 싶은 파드를 지정한다.
이렇게 서비스를 만들면 이 서비스는 클러스터 ip를 부여받는다.
서비스는 각 파드의 ip를 찾고, 자신의 ip로 들어오는 트래픽에 대해서 백엔드 파드로 보내준다.
이건 초심자가 이해하기에 걸맞는 아주 추상화된 설명이고, 조금 더 구체적으로 보겠다.
구조에 기반한 설명
클러스터 내부에서 일어나는 구조적인 설명으로는 아래처럼 이야기할 수 있다.
서비스가 만들어지면 EndpointSlice 컨트롤러가 작동하여 라벨 조건에 맞는 파드를 찾는다.
그리고 각 파드에 대한 각 엔드포인트를 만들고, 이것을 서비스와 연결되도록 만든다.
여기에서 실제 트래픽의 이동은 노드의 네트워크 프록싱을 통해 이뤄진다.
각 노드에 설치된 kube-proxy가 Etcd에 저장되는 각 오브젝트 정보를 감시하고 있다.
그리고는 서비스 - 가상 IP 매커니즘을 기반으로 노드의 iptables를 이용하여 트래픽 규칙을 만든다.
그래서 서비스 ip로 들어오는 트래픽을 엔드포인트 ip로 보내는 규칙이 만들어지고, 결과적으로 트래픽이 파드로 전달된다.
나는 네떡린이라서 이 정도의 설명으로도 충분치 않아 추가 공부를 진행했다.
프록시 원리와 가상 IP를 할당 받는 과정에 대해 더 자세하게 알고 싶다면 서비스 - 가상 IP 매커니즘을 참조하자.
또한 CNI에 따라서 kube-proxy를 사용하지 않는 경우도 있다!
대표적으로 Cilium은 eBPF를 기반으로 netfilter를 아예 사용하지 않고 저만의 프록시를 해낸다.
이후에 이어질 설명에서는 kube-proxy를 통해 이뤄진다고 가정하고 글을 쓰겠다.
어차피 어떤 방식으로 만들었든, kube-proxy가 하게 되는 작업과 동일한 기능을 수행하기 때문이다.
서비스 디스커버리(서비스 접근)
그래서 클러스터 내부의 클라이언트로서 이 서비스에 접근하고자 할 때 어떻게 하면 되는 건가?
여기에는 두 가지 방법이 있다.
환경변수
각 노드의 kubelet은 현재 활성화된 서비스에 대한 환경 변수를 모든 파드에 추가해준다.
가령 redis-primary라는 서비스가 10.0.0.11라는 클러스터 ip 주소를 받은 채 tcp 6379 포트를 열고 있다고 쳐보자.
REDIS_PRIMARY_SERVICE_HOST=10.0.0.11
REDIS_PRIMARY_SERVICE_PORT=6379
REDIS_PRIMARY_PORT=tcp://10.0.0.11:6379
REDIS_PRIMARY_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_PRIMARY_PORT_6379_TCP_PROTO=tcp
REDIS_PRIMARY_PORT_6379_TCP_PORT=6379
REDIS_PRIMARY_PORT_6379_TCP_ADDR=10.0.0.11
# 뭐 이리 많나
그럼 이렇게 {서비스_이름}_SERVICE_HOST라는 등의 이름으로 환경변수를 만들어주게 된다.
보듯이 모든 문자가 대문자가 되며, -는 _이 된다.
그러나 이렇게 어떤 서비스를 탐색하는 것은 그다지 추천하진 않는데, 지금 존재하는 모든 파드들이 이런 환경 변수를 받는 게 아니기 때문이다.
오직 서비스가 만들어진 이후, 앞으로 만들어지는 파드들에만 환경변수가 적용된다..
DNS
클러스터를 구축할 때 대체로(거의 무조건) Core DNS라는 내부 DNS 서버를 구축하게 된다.
이 친구는 새로운 서비스가 만들어질 때 이에 대한 레코드를 생성한다.
그래서 클라이언트, 파드는 이 놈을 거쳐서 dns 쿼리를 날리면 된다.
가령 ns라는 네임스페이스에 serv라는 서비스가 있다 쳐보자.
그렇다면 아래 레코드들이 생기며 이렇게 접근이 가능해진다.
- 같은 네임스페이스
serv
- 다른 네임스페이스
serv.ns
심지어 알려진 포트에 대해서는 SRV 레코드도 만들어준다.
tcp로 만들어진, http이라는 이름의 포트가 있다면?
_http._tcp.serv.ns라는 식으로 레코드가 만들어진다.
ExternalName 서비스는 오직 dns로만 접근이 가능하도록 만들어져 있으니, 결국 서비스를 쓸 때는 dns로만 쓰는 방향으로 생각하자.
dns 서버가 너무 부하를 받는 것 같다, 싶을 때나 환경변수 방식을 써볼까? 고려해보는 정도이다.
여기도 추가적으로 dns 방식 정보를 더 넣자.
유형(타입)
당연히 실제 서비스를 할 때 외부로 어떻게 트래픽을 노출할 것인가에 대한 고민도 있을 것이다.
이를 위해, 쿠버네티스에서는 다음의 4가지 서비스 타입을 제공한다.
이 타입들은 단계적이라고 봐야 한다.
즉, 다음 타입은 이전 타입의 특징과 기능을 포함한다.
ClusterIP
클러스터 내부에서 사용할 수 있는 ip를 가지는 타입.
말만 들어도 기본값인 걸 알겠는데, 이 타입을 기반으로 아래의 서비스 타입들이 성립한다.
다시 말해 아래의 타입들은 사실 전부 클러스터 ip를 가진다.
당연히 클러스터 외부에서는 이 ip를 사용할 수 없다.
그러나 여기에 Ingress, Gateway API를 활용해 바깥으로 트래픽을 노출할 방법이 있긴 하다.
spec.clusterIP 필드를 직접 지정하지 않으면 쿠버네티스를 설치할 당시 service-cluster-ip-range CIDR 범위 내의 무작위 IP가 할당된다.
직접 지정해서 할당해도 되긴 하는데, 충돌이 일어날 가능성이 있으니 굳이 그래야 할 상황이 아니라면 조심하는 것이 좋다.
가령 특정한 DNS 주소를 재사용해야 하는 경우를 고려해볼 수 있겠다.
기본적으로 ip는 변동이 되는 한이 있더라도 고유하게는 사용돼야 하기에, 쿠버네티스는 etcd에 맵을 저장해두는 방식으로 이를 관리한다.
한편, 헤드리스 서비스라고 클러스터ip를 지정하지 않고 사용하는 방법이 있는데..
아래 [[#양식 작성법]]에서 참고.
NodePort
설치할 때 --service-node-port-range에 지정했던 범위 내에서(기본값 30000-32767), 노드 ip의 특정 포트를 노출시킨다.
그래서 노드 ip 주소에다가 지정받은 포트로 연결을 시도하면 연결된다.
이 타입은 직접 로드밸런싱을 만들거나, 쿠버네티스에 제어되고 있지 않는 환경에 몇 주소를 직접적으로 노출하는 자유도를 준다.
참고로 여기에서 노드라 하면 클러스터 내의 모든 노드를 말하는 것이다.
.spec.ports[*].nodePort 필드에 해당 포트가 명시된다.
이것 역시 직접 명시하는 방법도 존재하며, 처음에 지정됐던 범위 내에서 직접 할당해주면 된다.
이걸 세팅하면 각 노드의 프록시는 노드의 ip에 지정된 포트로 들어오는 트래픽을 엔드포인트로 연결하는 룰을 추가적으로 쓰게 된다.
이 놈도 포트를 두가지 밴드로 나눈다.
그래서 충돌을 가급적 피하고 싶다면 가능한 하위 밴드를 사용해주면 된다.
특정 IP 주소까지 지정하고 싶다면
한 호스트는 당연히 여러 네트워크 주소를 가질 수 있다.
이때 클러스터 구축될 당시 사용됐던 주소가 아닌, 다른 네트워크 주소를 이용하고 싶다면, kube-proxy 설정을 해줘야 한다.

--nodeport-addresses 플래그를 지정하여주면 되는데, 이 플래그는 기본적으로 항상 있으며 기본은 빈 값이다.
이 값이 primary라는 문자열이라면 클러스터가 구축될 당시 세팅된 주소만을 노드의 로컬로 인식한다.
--nodeport-addresses=127.0.0.0/8 이런 식으로 cidr 값을 지정하면 해당 주소 범위도 포함해서 로컬로 인식하게 된다.
아무 값도 없다면 모든 로컬로 통하는 ip 주소는 다 로컬로 인식하게 된다!
LoadBalancer
https://kubernetes.io/docs/tasks/access-application-cluster/create-external-load-balancer
클러스터 외부의 로드밸런서에 서비스를 노출한다.
보통 이건 클라우드를 사용할 때 사용할 수 있는 타입으로, 그것도 클러스터 내부에 조금의 컨트롤러 세팅을 해줘야 하는 경우가 대부분이다.
해당 로드밸런서를 제공하는 측에서 엔드포인트에 어떻게 연결할지 알아서 방법을 마련하게 돼있어서, 클라우드마다 조금씩 방식이 다를 수는 있다.
아무튼 로드밸런서에서 오는 트래픽이 직접적으로 엔드포인트의 파드에 도달하게 돼있다.
이 타입을 만드는 것은 비동기적으로 이뤄진다.
즉 실제로 로드밸런서 타입의 서비스가 클러스터 내부에 존재해도 클러스터 외부의 로드밸런서가 만들어지는데 시간이 걸릴 수 있다.
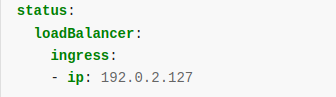
제대로 만들어지고 난 이후에는, .status.loadBalancer필드로 확인할 수 있다.
1.24 버전 이전에는 .spec.loadBalancerIP를 세팅하면 로드밸런서의 ip를 클러스터 단에서 커스텀할 수 있도록 지원하는 로드밸런서 구현체들도 있었다.
그러나 이 필드를 구현하는 의미나 방식이 저마다 너무 달랐고, 듀얼 스택(ipv4, ipv6)을 지원하지도 않았기에 결국 버려지는 기능이 되었다.
차후 버전에서는 완전히 사용도 못하게 제거될 예정이다.
이제 이런 것을 세팅하고 싶다면, Gateway API에서 하도록 하자.
클러스터 세부 동작 과정
각종 작업이 클러스터 외부에서 일어난다고 쳐도, 클러스터 자체는 어떻게 이런 서비스를 마련해주는가?
쿠버네티스는 실제로는 일단 NodePort 서비스를 만든다.
그럼 외부의 로드밸런서가 이 포트를 이용해서 트래픽이 흘러들어가도록 하는 방식이다.
노드포트를 사용하지 않고 트래픽이 연결되도록 하는 세팅 기능을 제공하는 로드밸런서도 종종 존재한다.
그런 기능을 지원한다면 .spec.allocateLoadBalancerNodePorts=False를 명시적으로 해주면 된다.
이걸 이후에 설정한다고 해서 알아서 노드포트가 제거되는 것이 아니기에, 이미 만든 서비스는 이걸 세팅하고 명시적으로 포트도 제거해줘야 한다.
이밖에 로드밸런서 관련한 설정이나 고려 사항들이 많이 있는데, 이것들은 아래 콜아웃으로 확인해보자.
로드밸런서의 헬스체크
대체로 모든 클라우드들의 로드밸런서 입장에서는 백엔드의 파드들이 잘 살아있는지 확인하는 헬스체크를 중시한다.
쿠버네티스에서는 이러한 방식을 정해진 api로 제공하지는 않으며, 다만 .spec.externalTrafficPolicy 필드를 로드밸런서마다 알아서 써먹을 수 있도록 지원하고 있다.
멀티 포트
로드 밸런서에서 여러 개의 포트가 지정되어 있을 때, 기본적으로는 모든 포트가 같은 프로토콜을 쓰도록 되어 있다.
1.24버전부터 기본으로 활성화된 MixedProtocolLBService 피처 게이트를 사용하면 여러 프로토콜을 사용할 수 있게 된다.
참고로 이때의 포트는 해당 로드밸런서에서 지원해주는 것만 쓸 수 있는데, 이게 쿠버에서 가능하게 명시한 것보다 더 제한적일 수도 있다.
클래스 지정
쿠버네티스에서 클래스라는 것은 기본값 정도의 의미를 가진다.
클러스터 내에 여러 로드밸런서를 지정하는 경우, 한 공급자가 여러 로드밸런서 구현체를 두는 경우, 어떤 로드밸런서를 쓸 지 제대로 명시하는 방법이 유효할 수 있다.
이때 .spec.loadBalancerClass를 써주면 되고, 그렇지 않으면 기본 로드밸런서 클래스가 지정될 것이다.
이 값은 라벨 셀렉터처럼 명시하면 된다.
이때 internal-vip와 같은 선택적인 접두사를 붙이는 게 가능하다고한다.
참고로 기본 로드밸런서 클래스는 --cloud-provider 플래그에 지정된 것으로 설정된다.
IP 주소 모드
로드밸런서 타입에 대해 .status.loadbalancer.ingress.ip가 지정된 경우가 있다.
이때 컨트롤러는 .status.loadbalancer.ingress.ipMode를 추가 세팅할 수 있다.
이 모드에는 두 가지가 존재한다.
- VIP
- 가상 ip라는 뜻으로, 트래픽은 로드밸런서의 ip와 포트를 목적지로 둔 채 노드로 전달된다.
- Proxy
- 이건 또 로드밸런서가 어떻게 구현됐냐에 따라 두 가지 방향성이 있다.
- 만약 트래픽이 노드로 전달된 후 파드로 DNAT되도록(목적지 ip가 교체된다면) 구현됐다면, 트래픽의 목적지는 노드의 ip와 포트일 것이다.
- 만약 트래픽이 바로 파드로 가도록 구현됐다면, 목적지는 파드의 ip와 포트일 것이다.
이 필드를 통해 라우팅을 조정하는 데 도움을 얻을 수 있을 것이다.
내부 로드 밸런서
다양한 혼합 환경에서는 가상 네트워크 주소 블록의 서비스에서 트래픽을 라우팅해야 할 수도 있다.
가령 수평적으로 분리된 DNS 환경에서는 엔드포인트로 외부와 내부의 트래픽을 라우팅하기 위해서는 두 개의 서비스가 필요하게 된다.
그래서 내부 로드 밸런서를 세팅하고 싶다면, 각 구현자가 세팅한 어노테이션을 이용한다.
annotations:
service.beta.kubernetes.io/aws-load-balancer-internal: "true"
이건 4.RESOURCE/KNOWLEDGE/AWS/AWS의 로드밸런서에서 세팅하는 예시이다.
ExternalName
apiVersion: v1
kind: Service
metadata:
name: naver
spec:
type: ExternalName
externalName: naver.com
이 놈은 위의 타입들과는 다른 조금 특별한 서비스라고 하겠다.
externalName 필드에 적힌 DNS 주소로 서비스를 연결해준다.
해당 서비스는 CNAME 레코드 역할로서 해당 주소의 dns 주소를 알려주는 dns로만 쓰인다는 것이다.
즉, 프록시나 이런 거 없이 클러스터 내부의 dns 서버에 대해서만 조작을 가하는 서비스인 것이다.
설정도 셀렉터가 아니라, .spec.externalName 필드를 통해 특정 dns 주소를 기입하는 방식이다.

이런 식으로 이제 클러스터에서 NAVER라고 치면 CNAME이 반환된다.
이게 유용한 경우는.. 많이 없지만 대체로 클러스터 외부에 DNS 주소를 사용하고 있는 케이스 정도.
클러스터 내에서 여러 부분에 클러스터 외부의 어떤 주소(가령 데이터베이스 주소)를 사용하고 있다면 이를 한번에 관리하는 역할로 이런 서비스를 두면 최소한 클러스터 내부적으로 해당 주소를 관리할 수 있게 되는 격이다.
그러면 클러스터 내부에서는 그냥 클러스터 내부 주소를 사용하면 되는 거라 관리 측면에서 살짝 편해지는 효과 정도는 있다.
만약 외부에 있던 어플리케이션을 클러스터 내부로 옮기게 된다고 생각하면, 옮긴 이후에 이 서비스를 cluster ip 같은 타입으로 바꾸고 설정만 하면 되니 적당히 유연하게 관리할 수 있게 된다.
주의사항
ip 주소를 기입하지 마라!
ip 주소를 입력해도 해당 주소를 그저 문자열로 파악해버리고 dns 질의를 날려버린다.
만약 특정 ip 주소를 입력하고 싶다면, 이 타입이 아니라 아래 [[#헤드리스 서비스]]를 사용하는 게 좋다.
그리고 이건 결국 요청을 하는 host 주소가 바뀌는 꼴이다.
그래서 요청을 처리하는 서버 측에서 해당 주소를 적절하게 처리하지 못한다면 결국 에러가 나게 될 것이다.
가령 외부 주소가 example.org인데, 해당 서버는 해당 도메인에 대한 TLS 인증서만 가지고 있다면, HTTPS 연결을 했을 때 tls 에러가 나게 될 것이다.
아니 이런 에러를 해결하려면 어떡함?;;
헤드리스 서비스
나름 특별한 방식이라 따로 정리한다.
서비스를 통해 가지는 이점은 위에서 봤듯 클러스터 내에서 파드의 상태와 독립적으로 고유한 ip를 획득하고, 로드밸런싱을 할 수 있다는 것이다.
그러나 굳이 고유한 ip가 필요하지는 않은 경우가 있을 수 있다.
.spec.type=ClusterIP, .spec.clusterIP="None"으로 설정하면 헤드리스 서비스를 만들 수 있다.
이때 "None"이란 건 헤드리스 서비스를 위해 처리되는 특수한 문자열로, 이 필드를 설정하지 않는 것과는 완전히 다른 의미를 가진다.
이렇게 하면 클러스터 ip는 따로 부여되지 않는다!
또한 프록시에서 이 서비스를 처리하지 않기에 로드 밸런싱, 프록싱이 일어나지 않는다.
그렇다면 백엔드로 어떻게 연결되는가?
이 서비스는 프록시 룰 없이 dns 서버에 바로 엔드포인트 ip를 등록하는 방식으로 동작한다.
만약 이 서비스로 nslookup을 날리면 뒷단에 연결된 파드의 클러스터 ip 주소를 바로 반환한다.
스테이트풀셋의 파드에 클러스터 내에 고유한 네트워크 식별자를 제공하기 위해 주로 쓰인다.
참고로 헤드리스 서비스는 반드시 port와 targetPort가 일치해야 한다.
기껏 해봐야 dns 서버 설정이기 때문에 포트 포워딩 같은 것이 불가능하기 때문이다.
dns 설정은 셀렉터를 어떻게 지정하냐에 달렸다.
셀렉터가 있다면, 엔드포인트 컨트롤러가 엔드포인트 슬라이스를 만든다.
그러면 dns 서버는 이 서비스에 대해 각 엔드포인트 주소를 담는 A 레코드(ipv6면 AAAA레코드)를 부여해줄 것이다.
셀렉터가 없다면 컨트롤러가 엔드포인트를 만들어주지 않는다.
이러면 dns 서버는 이런 설정을 한다.
- externalname에 대해서는 cname 레코드
- externalname 서비스를 제외한 모든 서비스의 준비된 모든 ip 주소에 대한 a레코드.
양식 작성법
apiVersion: v1
kind: Service
metadata:
labels:
app: my-svc
name: my-svc
spec:
selector:
app: my-svc
ports:
- name: 5678-80
port: 5678
protocol: TCP
targetPort: 80
type: ClusterIP
---
apiVersion: v1
kind: Pod
metadata:
labels:
app: my-svc
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
간단한 예시이다.
일단 대상이 될 파드는 라벨을 가지고 있어야 하며, 서비스는 라벨 셀렉터를 이용해 해당 파드를 탐지한다.
type 필드를 통해 유형을 지정했다.
ports
서비스의 포트를 목적지의 어떤 포트로 어떻게 흘려보낼지를 나타내는 필드이다.
기본적으로 서비스는 자신의 포트에서 어떤 tagetPort로든 연결이 가능한데, 흔히 같은 포트로 지정하긴 한다.
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app.kubernetes.io/name: proxy
spec:
containers:
- name: nginx
image: nginx:stable
ports:
- containerPort: 80
name: http-web-svc
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app.kubernetes.io/name: proxy
ports:
- name: name-of-service-port
protocol: TCP
port: 80
targetPort: http-web-svc
- name: https
protocol: TCP
port: 443
targetPort: 9377
다음 소개할 두 가지 특징들을 보여주는 예시
- targetPort를 지정할 때 파드에서 사용한 포트 이름을 활용하는 게 가능하다!
- 보다시피 서비스의 targetPort에
http-web-svc라 하여, 파드에 있던 포트의 이름을 사용했다. - 이러한 방식으로 어플리케이션의 포트를 변경할 때 유연하게 대처할 수 있다.
- 보다시피 서비스의 targetPort에
- 포트를 여러 개 열어서 활용할 수도 있다.
- 반드시 각 포트 이름을 고유하게 설정해주어야만 한다.
protocol
프로토콜은 기본값이 TCP이며, 지정할 수 있는 프로토콜은 다음과 같다.
SCTP- Stream Control Transmission Protocol
- 메시지 기반 제어 프로토콜이라는데, 나중에 조금 더 자세히 다루겠다.
UDPTCP- 내부에 더 세부적인 프로토콜을 지정하는 것도 가능하다.
HTTP,HTTPSPROXYTLS
참고로 로드밸런서 타입을 사용한다면, 클라우드 회사의 로드밸런서가 이러한 프로토콜을 지원하는지 확인해야 한다.
그리고 웬만해서 그냥 TCP를 사용하고 어노테이션으로 프로토콜을 명시하는 경우도 많다고 한다.
selector
기본적으로 라벨 셀렉터를 사용하여 자신이 추적할 파드를 확인한다.
근데 재밌는 짓거리를 할 수 있다.
셀렉터 없는 서비스
서비스는 엔드포인트슬라이스를 통해 파드와 연결되며, 해당 컨트롤러가 작동하여 연결을 해준다고 했다.
그러나 이 엔드포인트를 직접 서비스에 연결하는 방법이 존재한다.
그래서 셀렉터 없이 서비스를 만들고, 관리자가 직접 엔드포인트를 연결해줄 수도 있다.
이런 상황을 생각해볼 수 있다.
- 운영 환경에서 외부 데이터베이스를 사용하나, 테스트 환경에서는 로컬 데이터베이스를 사용한다.
- 서비스가 다른 네임스페이스의 서비스, 혹은 다른 클러스터의 서비스를 가리키게 하고 싶다.
- 쿠버네티스로 마이그레이션을 진행하나 아직 일부분만 제한적으로 사용 중이다.
뭐.. 이런 이유 등으로 서비스를 조금 커스텀하고 싶을 때, 셀렉터를 지정하지 않고 사용하는 방법이 유용하다.
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: my-service-1 # 관례적으로 연결할 서비스의 이름을 접두사로 사용한다.
labels:
# "kubernetes.io/service-name" 라벨에 서비스 이름을 명시해야 한다.
kubernetes.io/service-name: my-service
addressType: IPv4
ports:
- name: http # 서비스에서 명시한 포트 이름과 일치해야 한다.
appProtocol: http
protocol: TCP
port: 9376
endpoints:
- addresses:
- "10.4.5.6"
- addresses:
- "10.1.2.3"
직접 만들 때는 이런 식으로 하면 된다.
엔드포인트슬라이스 오브젝트를 서비스 이름을 접두사로 하여 이름을 만들고, 라벨에 kubernetes.io/serviec-name을 달아준다.
그리고 서비스에 명시된 ports들을 써준다.
이후에는 원하는 ip 주소들을 endpoints 필드에 입력하면 된다.
참고로 ExternalName 서비스는 셀렉터 없이 DNS만 있는 서비스 타입이다.
몇 가지 알아야 할 것들이 있다.
주의 사항
라벨에 endpointslice.kubernetes.io/managed-by를 달아서 사용하는 컨트롤러를 명시해야 한다.
"my-domain.example/name-of-controller" 이런 식으로 작성하면 되는데, 없으면 그냥 아무 이름을 넣으면 된다.
다만 "controller"는 원래 클러스터에서 사용하는 컨트롤러니까 이것만 피해주자.
ip 주소는 루프백이나, 노드 주소가 아닌 클러스터 ip주소를 넣어야 한다.
또한 파드에 매칭되지 않는 주소를 엔드포인트로 넣는 것은 허용되지 않는다.
kubectl을 써보면 쉽게 port-forward를 할 수 있는데, 이때 임의의 주소로 접근하는 식으로 악용하는 것을 막아야 하기 때문이다.
이걸 사용함녀 어떻게 되는데?
appProtocol
서비스 포트에 어떤 어플리케이션 프로토콜인지 명시하고 싶을 때 이 필드를 쓴다.
실제 구현체에 대한 더 유익한 힌트를 제공해주고 싶을 때 쓰는 것이다.
이 값은 이후에 엔드포인트슬라이스 오브젝트에도 미러링된다.
여기에 쓸 수 있는 값의 예시는 다음과 같다.
- IANA 표준 서비스 이름[3]
kubernetes.io/h2c- HTTP/2kubernetes.io/ws- WebSocketkubernetes.io/wss- WebSocket Secure- 기타 사용자가 만든 정의된 이름..
sessionAffinity
프록시는 기본적으로 트래픽은 클라 입장에서 쿠버네티스의 서비스나 파드를 모르게 프록싱한다.
그러니 한 클라이언트가 같은 파드로 트래픽을 보내는 것을 보장할 수 없다.
이걸 보완하고 싶다면 .spec.sessionAffinity=ClientIP를 추가하자.
또한 세션 고정시간을 지정하고 싶다면 .spec.sessionAffinityConfig.clientIP.timeoutSeconds를 설정하면 된다.
기본은 10800, 즉 3시간으로 잡혀있다.
이건 구체적으로 어떻게 이렇게 될 수 있는 걸까?
externalIPs
해당 서비스로 접근하는 특정한 외부 ip를 명시할 수 있는 상황이라면, .spec.externalIPs 필드로 명시할 수 있다.
이 경우 제대로 포트가 들어오고 해당 ip 주소로 온 경우에만 트래픽을 라우팅해줄 것이다.
이건 쿠버네티스 측에서 자동으로 해주는 건 없고, 오직 관리자가 직접 지정해야 하는 필드이다.
트래픽 정책
클러스터 내부에서 트래픽이 오고 간다고 생각해보자.
그런데 한 노드에서 오갈 수 있는 트래픽이 굳이 다른 노드를 가는 것은 매우 불필요한 일이 될 것이다.
이런 상황을 위해 트래픽 라우팅에 대한 상세 정책을 만드는 것이 가능하다.
아래 [[#trafficDistribution]]와 더불어서 사용할 수 있는데 이 과정이 꽤나 복잡해서 조금 정리를 해야 한다.
internalTrafficPolicy
.spec.internalTrafficPolicy를 통해 내부의 트래픽에 대해 설정을 진행한다.
- Cluster - 모든 노드의 엔드포인트로 트래픽 보냄
- Local - 노드의 엔드포인트로 트래픽 보냄
보낸다고 해도 준비 상태(status: ready)라고 체크돼있는 엔드포인트에만 보낸다(이것도 세부 커스텀이 가능해서 굳이 언급한다..).
Local로 설정하면 다른 노드에 엔드포인트가 있어도 로컬에 없으면 트래픽을 버린다.
이 설정은 프록시가 로컬 노드에 대해서만 흘러가도록 룰을 추가하기 때문이다.
이런 게 걱정이면 아래 나올 분배를 사용하면 조금 더 좋을 수도 있다!
externalTrafficPolicy
.spec.externalTrafficPolicy을 통해 외부에서 오는 트래픽에 대한 설정을 진행한다.
허용되는 값은 위와 같아서 크게 고민할 게 없을 것 같은데...
LoadBalancer 타입과 엮여서 생각보다 간단하지 않다..
세부적으로 보자.
Cluster
Cluster라면 클러스터 내의 모든 건강한 노드로 트래픽을 보내준다.
이 방식은 균등한 부하분산을 기대할 수 있지만 소스 ip를 가린다.
여기에서 건강하다는 것은 프록시의 레디네스 포트를 통해 이뤄지는데, 보통 {노드ip}:10256/healthz일 것이다.
이때 두 가지의 반환 코드가 있을 수 있다.
- 200
- 프록시가 건강하다 - 프록시 규칙을 지정된 (
.spec.iptables.syncPeriod에 정의된) 시간 내에 잘 쓸 수 있는 상태라는 말이다. - 노드가 제거되지 않았다.
- 프록시가 건강하다 - 프록시 규칙을 지정된 (
- 503
- 프록시가 이 코드를 내뱉는 것은 노드가 제거되는 중이라는 것을 의미한다.
- 노드가 종료될 때 이에 대한 운영 대책을 마련할 수 있도록 제공되는 코드이다.
- 구체적으로 노드가 제거되는 중과 제거됨에는 차이가 있다.
- 제거되는 중
- 프록시의 준비 상태가 실패한다.
- 그리고 로드밸런서 트래픽을 처리못한다고 마킹한다.
- 로드밸런서는 헬스체크를 실패했으니 이 노드로 연결하는 트래픽을 제거하고 연결을 막을 수 있게 된다!
- 제거됨
- cloud controller manager에 있는 서비스 컨트롤러가 해당 노드를 적합한 타겟 집합에서 아예 제거한다.
- 이에 따라 로드 밸런스의 백엔드가 있었다면 모든 연결이 종료된다.
- 프록시 헬스체크도 실패하는데, 그것은 이 연결 종료 덕에 이뤄진다.
- 제거되는 중
kube-proxy에 대한 레디네스 프로브를 라이브네스 프로브마냥 설정하는 로드밸런서 구현체가 있다.
이러면 종료되는 노드에서 프록시가 라이브네스 설정으로 계속 재시작하게 된다!
프록시의 /livez 경로는 healthz와 달리 노드의 종료 상태를 체크하지 않으며, 될 때까지는 계속 네트워크 규칙을 만들 수 있는 상태만 보인다.
그래서 프록시에 대해서 라이브네스를 지정할 거면 이 경로를 쓰는 게 맞다.
Local
이 경우에는 외부 로드밸런서가 알아서 로드밸런싱을 잘 했을 것이라 감안하고 각 노드로 들어온 트래픽은 무조건 자신 노드로 보낸다.
추가적인 홉을 피하면서 소스 ip를 감추지 않고 트래픽을 보낼 수 있다는 장점도 있다.
이 방식에서는 노드의 삭제가 노드의 준비 상태에 영향을 주지 않는다!
왜냐하면 노드가 제거되는 중이라는 것이 영향을 주게 되면 다른 노드로 트래픽을 넘겨줄 일이 없기 때문에 그 즉시 관련한 모든 트래픽이 중단돼버리기 때문이다.
그래서 이번에는 healthz를 통해 상태 검사를 하는 게 권장된다.
종료되는 엔드포인트를 향한 트래픽
ProxyTerminatingEndpoints 피처 게이트가 활성화됐고, 트래픽 정책이 로컬이라면?
프록시는 서비스의 엔드포인트를 위해 조금 더 복잡한 알고리즘을 쓸 수 있다.
프록시는 로컬 엔드포인트가 종료 중이건 말건 노드에 일단 엔드포인트가 있는지를 체크한다.
근데 이때 종료 중이지 않은 엔드포인트가 있다면 이 엔포를 종료 중인 놈보다는 선호하게 하는 기능이다.
이 방식은 externalTrafficPolicy=Local인 NodePort, LoadBalancer 서비스에 대해 연결을 안전하게 종료하도록 해준다.
가령 디플 롤링 업뎃으로 구현됐다면 이대 레플리카를 0으로 줄이는 식으로 설정할 것이다.
헬스체크 간격에 따라 0개가 돼버린 노드로 트래픽을 보내는 경우가 생길 수는 있다.
이럴 때 이 방식은 위험성을 없앨 시간을 준다는 것이다.
파드가 완전 종료되면, 외부 로드밸런서는 노드 헬스체크가 실패한 것을 파악하고 완전히 백엔드 풀을 제거해야 한다.
솔직히 이쪽 부분에서 뭐라는 건지 잘 모르겠다.
뭘 말하고 싶은 거지..?
그러니까 로밸 구현체들은 트래픽 정책이 cluster일 때는 livez로, local일 때는 healthz로 헬쳌하라는 건가?
그리고 종료 중인 것에 대한 비선호가 어떻게 안전한 종료를 보장하는 걸까..?
trafficDistribution
위에서 트래픽 정책을 봤는데, 트래픽 분배 전략을 조금 더 유하게 가져갈 수도 있다.
ServiceTrafficDistribution 피처 게이트를 사용하면 사용할 수 있는데, .spec.trafficDistribution로 설정한다.
1.32에서 Preferclose라는 값을 쓸 수 있는데, 클라이언트 입장에서 같은 노드, 위상적으로 가까운 곳을 선호하게 하는 옵션이다.
위상적이란 표현은 구현에 따라 달라지는데, 가령 동일한 노드나, 랙, 영역, 리전 등을 담을 수 있다.
프록시는 이를 가이드라인 삼아 트래픽을 보내는 규칙을 쓸 것이다.
구체적으로 프록시는 클라이언트와 같은 존에 있는 엔드포인트에 우선순위를 부여한다.
엔포슬 컨트롤러는 엔포슬에 hints라는 것을 주는데, 이걸 프록시가 라우팅 결정에 활용하게 된다.
만약 클라의 존에 가능한 엔드포인트가 없다면 클러스터 전역으로 라우팅될 것이다.
물론 이런 세팅은 균등한 로드밸런싱보다 그저 근접성을 추구하게 하는 트레이드오프를 야기할 수 있다는 것을 주의하자.
어노테이션 방식과의 비교
어노테이션 service.kubernetes.io/topology-mode: Auto을 달아서 최대한 같은 존이란 토폴로지로 트래픽을 보내는 설정을 할 수도 있다.[4]
조금 과거 방식이기는 하나, 아직 유효하다.
문서를 보면 어노테이션 방식은 cpu 자원을 할당할 수 있는 비율에 따라 비례적으로 분산하는 로직을 가지고 있다.
또한 대체 동작 같은 안전 장치를 포함하고 있고, 로드밸런싱 이슈 때문에 비활성화될 수도 있다.
그래서 구체적인 동작을 예측하기 힘들어지게 된다.
즉, 로드밸런싱을 위해 예측 가능성을 살짝 희생하는 것이다.
PreferClose를 사용하는 방식은 조금 더 단순하고 예측 가능하다.
그냥 엔드포인트가 로컬에 있으면 로컬에서 전부 트래픽을 처리하고, 없으면 다른 곳으로 보낼 뿐이다.
간단하지만 잠재적 과부하는 있을 수 있겠다.
참고로 어노테이션 service.kubernetes.io/topology-mode=Auto가 이 정책보다 우선한다..
이후에 이 필드 때문에 제거될 수도 있다고 한다.
트래픽 정책과의 비교
트래픽 정책은 엄격한 의미 보장에 초점을 맞추기에, 로컬로 설정됐으면 절대 클러스터 전역으로 트래픽을 보내지 않는다.
그러나 트래픽 분배(traffic distribution) 전략은 같은 노드의 엔드포인트를 선호한다, 정도의 선호도 개념을 담을 수 있다.
그래서 성능, 비용, 안정성을 최적화하는데 조금 더 도움을 줄 것이다ㅏ.
만약 트래픽 정책이 로컬이라면 무조건 정책이 우선적용돼서 세팅할 필요도 없다.
그러나 정책이 cluster라면 분배 전략이 가이드 역할이 되어주게 된다.
트래픽 분배 전략 고려사항
최대한 같은 지역, 노드로 보내려고 하니, 당연히 과부하가 걸리기 마련일 것이다.
아무리 엔드포인트가 클러스터에 고르게 퍼져있어도 가까운 곳으로만 보내기 때문이다.
그래서 같은 존에 충분한 엔드포인트가 없다면 과부하가 걸릴 것이다.
그리고 들어오는 트래픽이 영역에 골고루 퍼지지 않으면 문제가 일어날 가능성이 크다.
이에 대해서 몇 가지 전략을 쓸 수 있다.
- 파드 토폴로지 분산 제약 조건 걸기
- 특정 토폴로지의 더 트래픽을 잘 받을 수 있게 배치한다.
- 토폴로지마다 따로 디플로이먼트 만들기
- 이러면 특정 토폴로지에 트래픽이 몰릴 때 유연하게 스케일링 될 것이다.
- 아예 이를 지원해주는 애드온들도 있으니 이런 걸 사용하는 것도 방법이다.
관련 문서
| 이름 | noteType | created |
|---|---|---|
| Service | knowledge | 2024-12-29 |
| 서비스 - 가상 IP 매커니즘 | knowledge | 2025-01-02 |
| 가상 IP 매커니즘 | knowledge | 2025-05-04 |
| EndpointSlice | knowledge | 2025-02-16 |
| LoxiLB | knowledge | 2025-01-07 |
| AWS Load Balancer Controller | knowledge | 2025-02-12 |
| 2W - ALB Controller, External DNS | published | 2025-02-15 |
| 4W - 실리움 로드밸런서 기능 - 서비스 IP, L2 | published | 2025-08-09 |
| 5W - BGP 실습 | published | 2025-08-16 |
| E-레디네스 프로브와 레디네스 게이트 | topic/explain | 2024-08-15 |
| I-EndpointSlice 분산 로직 분석 | topic/idea | 2025-01-03 |
| S-flannel dns 질의 실패 | topic/shooting | 2024-09-11 |
| T-스테이트풀셋과 연결되는 헤드리스 서비스에 관한 실험 | topic/temp | 2024-12-27 |
| T-LoxiLB vs MetalLB | topic/temp | 2025-01-06 |
참고
이 놈도 문서가 아주 극혐입니다.
내부 트래픽 정책은 왜 따로 문서가 분리돼있는 건지..
가상 ip 매커니즘 관련 문서에서 양식 필드들이 대거 있는 건 꼭 중간 문서를 똑 떼서 분리한 듯 보인다.
https://kubernetes.io/docs/concepts/services-networking/service/ ↩︎
https://blog.nashtechglobal.com/understanding-kubernetes-service-discovery/ 라벨 달린 그림이 맘에 들어서 채택 ↩︎
https://www.iana.org/assignments/service-names-port-numbers/service-names-port-numbers.xhtml ↩︎
https://kubernetes.io/docs/concepts/services-networking/topology-aware-routing/ ↩︎