KEDA
개요

쿠버네티스의 이벤트 기반 오토스케일러.[1]
말 그대로 이벤트를 개수 등을 기반으로 오토스케일링을 할 수 있다.
설계 자체가 HPA처럼 클러스터 내부에서 같이 동작하며 간단하게 구성할 수 있는 방향으로 잡혀있다고 한다.
참고로 이 친구가 클러스터의 스케일링을 할 때는 HPA를 만들어서 진행한다.
그러니 케다는 기본 오토스케일러가 다양한 이벤트를 기반으로 스케일링을 진행할 수 있도록 기능을 확장하는 도구라고 보면 될 것 같다.

사이트 들어가보면 스케일러로 사용할 수 있는 게 엄청 많다.
cpu도 있고, cron도 있고, 그냥 모든 지표들과 이벤트들을 기반으로 스케일링할 수 있도록 하는 것을 목표로 잡은 듯하다.
hpa는 단순하게 메트릭만 보고 스케일링을 진행하나, 이 녀석은 이 다양한 구현체들에서 제공하는 이벤트들을 활용할 수 있게 되는 것이다.
가령 카프카 큐의 메시지 개수가 몇 개가 넘었다느니 하는 것들.
기능
말그대로 오토스케일링을 한다.
하지만 실질적인 초점은 이벤트를 받는다는 것으로, 이것을 통해 다양한 기능을 제공한다.

아래 기능들은 keda를 설치할 때 설치되는 파드들하고도 같다.
- 오토스케일링 에이전트
- 메트릭 제공
- hpa는 메트릭을 기반으로 움직이는데, 케다가 이를 위해 메트릭을 제공해주는 역할을 한다.
- 이런 기능을 해주는 이유는 [[#아키텍쳐]]에서 보겠다.
- Admission Webhook
- 자신과 관련된 오브젝트에 대해 잘못된 설정을 미리 체크하고 막아준다.
- validation 체크만 한다.
사용 흐름
- 설치
- 일단 keda를 설치해야 한다!
- 사용하고자 하는 스케일러를 지정한다.
- 여기에서 스케일러는 이벤트를 발동시키는 주체를 말한다.
- 각각에 해당하는 애드온이 존재하기에, 이걸 설치해줘야 한다.
ScaledObject생성 후 적용
아키텍쳐
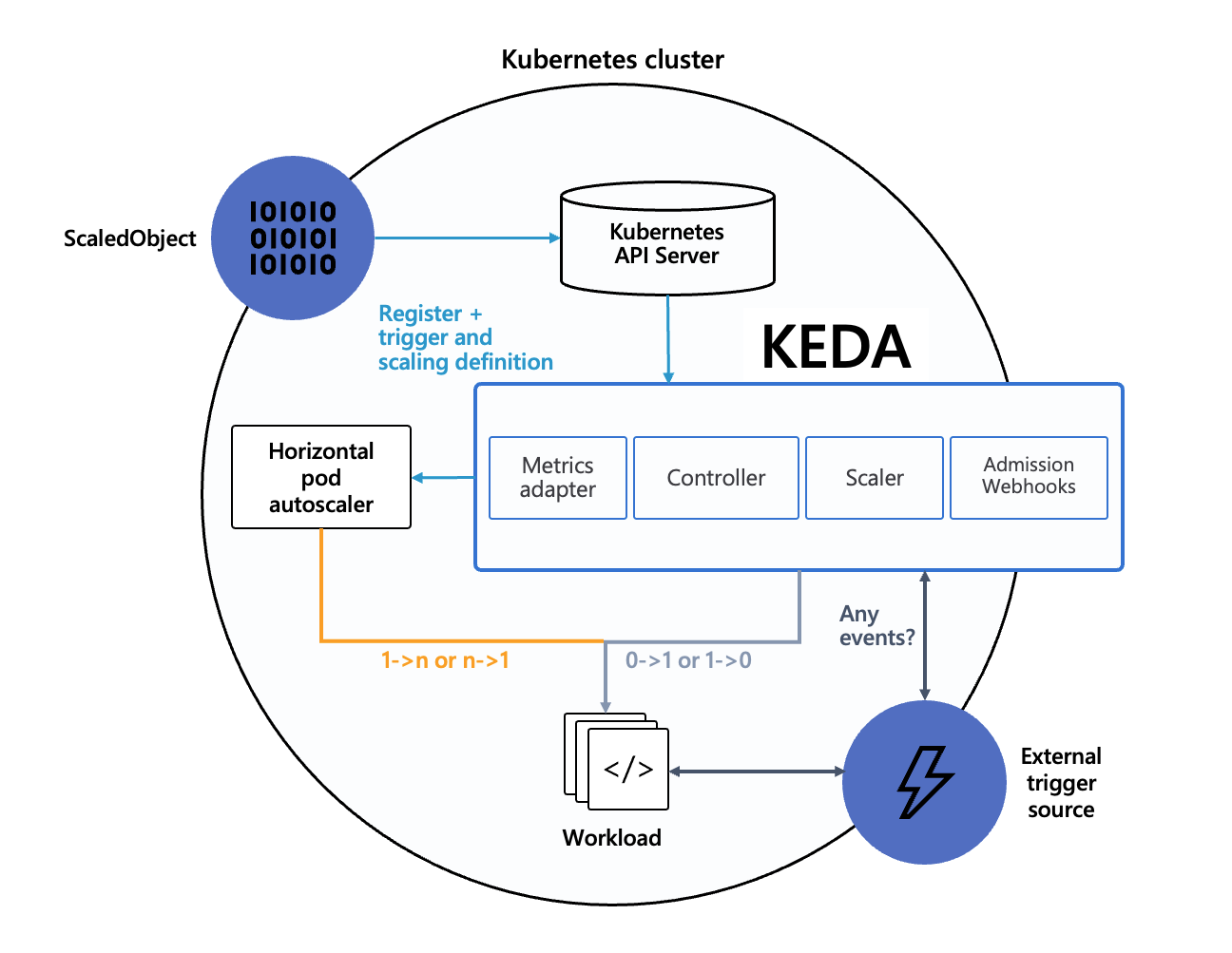
간단하게 보자면.. 케다 오퍼레이터가 있다.
이 놈이 외부 이벤트를 주기적으로 가져오고, 또한 관리자가 요구한 스케일링 양식도 확인한다.
그리고 요건이 충족되면 HPA를 작동시켜서 스케일링을 시키는 것이다.
이때 HPA는 external 메트릭을 기준으로 작동되며, 이 메트릭을 전달하는 책임자가 바로 케다이다.
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1"
이렇게 조회하면 keda가 HPA를 위해 노출해주는 메트릭들을 볼 수 있다.
그러나 keda는 이벤트 기반이다보니 항상 메트릭을 노출해주는 다른 메트릭 api와는 달라서, 실질적으로 메트릭을 조회한다고 해도 사실은 캐시된 값을 보게 될 확률이 높다.
아래 [[#pollingInterval]] 참고.
어차피 이벤트마다 메트릭이 새로 튀어나오는 거니 어쩌면 당연할지도 모르겠다.
k get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/{네임스페이스}/{메트릭이름}?labelSelector=scaledobject.keda.sh%2Fname%3D{ScaledObjectName}"
구제적으로 메트릭을 관찰하고 싶을 땐 이런 식으로 보면 된다.
레플리카 0과 1의 차이
HPA에서는 최소 레플리카 개수가 0이 될 수 없다.
그러나 케다는 레플리카를 0으로 만들어 원하는 이벤트에 따라 워크로드를 비활성화시킬 수 있는데, 대신 hpa와의 간극을 명확히 하기 위해 스케일링 프로세스를 두 가지로 구분한다.
- Activation - 0에서 늘리거나, 0으로 줄이는 스케일링 단계를 말한다.
- Scaling - 양수 범위에서 스케일링되는 단계로, HPA가 정상적으로 동작할 수 있는 단계이다.
활성화 단계가 따로 존재하는 이유는 HPA가 레플리카 0에서 동작하지 않기 때문이다.
그래서 이벤트를 이용해 메트릭을 뿌리기만 하고 HPA에게 스케일링을 위임하던 평소와 다르게, 레플리카 0에서 스케일링을 할 때는 케다가 명확하게 레플리카 수를 늘리는 작업을 진행한다.
몇 가지 스케일러의 경우 이것에 대한 커스텀 설정들을 제공한다.
유의사항
어디까지나 keda는 이벤트를 기반으로 하는 것이 주된 목적이다.
그래서 메트릭을 확장해주기도 하지만 한편으로는 동작이 다르다는 것도 감안해야 한다.
그래서 놀랍게도.. http 요청량을 기반으로 스케일링 하는 것이 기본적으로 지원되지 않는다.
(사실 프로메테우스 스케일러를 쓰면 어느 정도 아쉬움을 해소할 수 있다.)
아무튼 이를 위해 추가 애드온을 개발하고 있는데, 아직 베타 단계.[2]
ScaledObject 양식 작성법
이건 스케일링을 설정할 때 쓰는 오브젝트이다.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
annotations:
scaledobject.keda.sh/transfer-hpa-ownership: "true" # 이 스케일러로 소유권을 이전할 때
validations.keda.sh/hpa-ownership: "true" # 소유권 검증 비활성화
autoscaling.keda.sh/paused: "true" # 오토스케일링 멈출 때
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # 기본-apps/v1
kind: {kind-of-target-resource} # 기본-Deployment
name: {name-of-target-resource} # 무조건 같은 네임스페이스
envSourceContainerName: {container-name} # 대상이 될 컨테이너 지정. 기본은 첫번째
pollingInterval: 30 # 이벤트 수집 주기 기본-30초
cooldownPeriod: 300 # 0으로의 스케일다운 텀. 기본-300초
initialCooldownPeriod: 0 # 위 필드의 처음적용 시점 기본-0초
idleReplicaCount: 0 # 유휴 레플리카 수
minReplicaCount: 1 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
fallback: # Optional. Section to specify fallback options
failureThreshold: 3 # Mandatory if fallback section is included
replicas: 6 # Mandatory if fallback section is included
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
name: {name-of-hpa-resource} # Optional. Default: keda-hpa-{scaled-object-name}
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
여기에 너무 잘 나와있는 것 같다.[3]
진짜 쿠버네티스 sig docs는 보고 배워라 우우
보통은 필드 작성법만 여기에 작성하지만, 어노테이션을 사용하는 방법에 대해서도 작성하겠다.
annotations
pause
autoscaling.keda.sh/paused-replicas: "0"
autoscaling.keda.sh/paused: "true"
오토스케일링을 명시적으로 그만두고 싶을 때는 이렇게 paused를 사용하면 된다.
여기에 어떤 지점에서 멈추게 하고 싶은 경우 위의 필드를 작성해주면 된다.
아래 필드를 작성하지 않고 위만 작성한다면 위의 레플리카에 도달했을 때 알아서 스케일링이 중단된다.
소유권 이전
metadata:
annotations:
scaledobject.keda.sh/transfer-hpa-ownership: "true"
spec:
advanced:
horizontalPodAutoscalerConfig:
name: {name-of-hpa-resource}
이미 HPA가 존재하는 상황에서 keda가 스케일링을 담당하도록 이전할 때는 이렇게 세팅해준다.
pollingInterval
트리거 대상에게서 이벤트를 긁어오는 주기를 지정한다.
그러나 HPA는 또 자체적으로 메트릭을 긁어오는 주기가 정해져있어서 여기에서 간극이 발생할 수 있고, 이에 따라 HPA의 이벤트에 경고가 발생할 수 있다.
대부분의 스케일러들은 이에 대해서 useCachedMetrics라는 필드를 따로 제공해 와들와들 경고하는 HPA를 잠재울 수 있다.
다만 cpu, memory, cron 스케일러에는 이게 없다.
cooldownPeriod
레플리카가 0으로 돌아가기 이전에 걸리는 쿨다운 기간으로 기본은 5분.
달리 말해 minReplica가 0이 아니라면 상관없는 값이다.
initialCooldownPeriod
위의 값이 적용되기 이전에 대기하는 기간이다.
0에서 바로 늘어난 레플리카의 상태에 대해 위 쿨다운 기간을 짧게 주면 금새 레플리카가 다시 0으로 돌아가버리는 경우가 생길 수 있다.
이런 게 싫을 때 설정하는 값이다.
idleReplicaCount
유휴 레플리카 개수.
HPA에 의해 조절될 값은 min과 max로 조절하는데, 만약 정말 아무런 활동이 일어나고 있지 않다면?
평소 서비스가 이뤄지는 와중에는(이벤트가 발생하는) 10~20개 사이에서 스케일링 되기 바라지만 아무런 활동도 일어나지 않는다면 그렇게까지 유지될 필요도 없을 것이다.
그럴 때 유휴 레플리카 개수를 지정해주면 된다.
그래서 이 값은 무조건 min 값보다는 작아야 한다.
fallback
fallback:
failureThreshold: 3
replicas: 6
스케일러가 에러 상태일 때 지정할 레플리카의 개수.
스케일러에 문제가 있다면 기본으로 유지할 레플리카의 개수를 지정한다.
advanced
여기는 더 세부적인 설정을 할 때 사용하는 필드이다.
horizontalPodAutoscalerConfig
advanced:
horizontalPodAutoscalerConfig:
name: {name-of-hpa-resource} # Optional. Default: keda-hpa-{scaled-object-name}
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
직접 HPA의 세부 스펙을 지정하고 싶을 때 사용한다.
양식 작성법은 HPA#양식 작성법 참고.
scalingModifiers
advanced:
scalingModifiers:
formula: "(trig_one + trig_two)/2"
target: "2"
activationTarget: "2"
metricType: "AverageValue"
...
triggers:
- type: kubernetes-workload
name: trig_one
metadata:
podSelector: 'pod=workload-test'
- type: metrics-api
name: trig_two
metadata:
url: "https://mockbin.org/bin/336a8d99-9e09-4f1f-979d-851a6d1b1423"
valueLocation: "tasks"
여러 스케일러를 걸었을 때 스케일링 동작을 세부적으로 지정할 수 있다.
triggers
여기는 그 무수한 스케일러들을 지정하는 필드이다.
상세한 건 각 스케일러 페이지를 들어가서 참고하는 편이 좋다.
기본적인 몇 가지만 적어두겠다.
- type
- metadata
- name
- useCachedMetrics - [[#pollingInterval]]에서 말한 캐싱
- authenticationRef - 인증 관련
- metricType - AverageValue, Value, Utilization 등 HPA에서의 메트릭 유형인데, Util은 사실 cpu와 메모리밖에 안 된다.
ScaledJob 양식 작성법
이건 통일성을 위해 이렇게 이름 지은 것 같은데.. 그냥 잡을 트리거할 때 쓰는 오브젝트이다.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
labels:
my-label: {my-label-value} # Optional. ScaledJob labels are applied to child Jobs
annotations:
autoscaling.keda.sh/paused: true # Optional. Use to pause autoscaling of Jobs
my-annotation: {my-annotation-value} # Optional. ScaledJob annotations are applied to child Jobs
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/job/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/job/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/job)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
minReplicaCount: 10 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
rolloutStrategy: gradual # Deprecated: Use rollout.strategy instead (see below).
rollout:
strategy: gradual # Optional. Default: default. Which Rollout Strategy KEDA will use.
propagationPolicy: foreground # Optional. Default: background. Kubernetes propagation policy for cleaning up existing jobs during rollout.
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
pendingPodConditions: # Optional. A parameter to calculate pending job count per the specified pod conditions
- "Ready"
- "PodScheduled"
- "AnyOtherCustomPodCondition"
multipleScalersCalculation : "max" # Optional. Default: max. Specifies how to calculate the target metrics when multiple scalers are defined.
triggers:
# {list of triggers to create jobs}