Job
개요
Jobs represent one-off tasks that run to completion and then stop.[1]
잡은 한번 실행하여 완료되면 멈추는 과제를 대표한다.
정의만 봐도 보이겠지만 여태까지의 워크로드들과는 조금 다른 용도로 사용되는 놈이다.

잡은 지정된 성공 횟수까지 지속적으로 파드를 만들어 실행을 시키는 작업을 한다.
파드 하나를 성공시켰고, 잡 자신 역시 성공 상태가 된 것이 보인다.
지정된 성공 횟수에 도달하면 작업은 완료됐다고 여겨진다.
기능
잡에 사용되는 컨테이너는 대체로 다음과 같은 특징을 가진다.
- 한번 실행되고 끝난다.
- 웹 서버처럼 지속적으로 돌아가는 프로세스를 돌리는 용도가 아니다.
- 프로레스 종료 코드가 다양하다.
- 필수는 아니나, 이를 통해 잡을 더 세부적으로 커스터마이징할 수 있다.
- 다음의 기능을 하는 프로세스들
- 표준 출력이나 외부 볼륨에 데이터를 남김
- 연산 작업, 다른 애플리케이션과 주기적인 통신
잡은 이러한 컨테이너를 돌리는 파드들에 대해서 여러 가지 기능을 제공해준다.
대표적으로는 이런 일들이 있다.
- 파드가 실패할 경우, 컨테이너가 실패할 경우 재시작
- 같은 작업이 몇 번 성공해야 하는지 지정
- 이때 작업에 번호를 매겨서 명시적으로 몇 번이 수행돼야 하는지도 정할 수 있는데, 아래에서 보겠다.
- 작업은 몇 번까지 실패할 수 있는지 지정
- 병렬적으로 작업 수행
문서에서는 잡을 통해 할 수 있는 작업을 크게 세 가지 정도로 분류한다.
그러나 내가 보기에는 이건 너무 대략적인 분류고, 그냥 이런 식으로 쓸 수 있다 정도만 생각하면 될 것 같다.
- 비-병렬 작업
- 순차적으로 파드를 실행하는 것이다.
- 하나의 파드가 종료되고(실패 or 성공) 다음 파드가 실행된다.
.spec.completions,.spec.parallelism을 건드리지 않고 기본값인 1로 둔다.
- 고정 완료 횟수를 지정한 병렬 작업
- 최소 몇 번을 성공시키는지만 중요한 작업
.spec.completions를 지정한다..spec.completionMode=Indexed일 때는 각 파드가 0부터 성공 횟수 - 1 까지 다른 인덱스를 가진다.
- 작업 큐를 활용하는 병렬 작업
- 파드끼리 협동하거나, 외부 서비스와 연동이 돼야 하는 케이스이다.
- 가령 잡과는 독립적으로 운영되는 메시징 큐가 있고 여기에서 N번만 메시지를 꺼내고 싶다던가..
- 파드는 같이 일하고 있는 파드들의 작업 상태를 판단할 수 있어야 한다.
- 이런 작업에서 잡이 성공하면
- 새로운 파드가 절대 생성되면 안 된다.
- 실행 중이던 다른 파드는 추가 작업 없이 전부 종료돼야 한다.
.spec.completions는 명시하지 않고.spec.parallelism만 쓰는 형태.
- 파드끼리 협동하거나, 외부 서비스와 연동이 돼야 하는 케이스이다.
문서에서는 다양한 예시를 두며 설명하고 있어서 E-잡 패턴 실습을 따로 진행해본다.
동작 방식
기본적으로 잡 컨트롤러가 파드들을 관리한다.
컨트롤러는 파드를 생성할 때 .metadata.ownerRefernecs를 잡으로 지정하여, 잡을 삭제하면 파드도 같이 삭제되도록 만든다.
이를 통해 본격적으로 파드를 생성하고 종료하고 하는 작업들을 한다.
잡의 진행
파드들이 동작을 수행하고나면 성공, 혹은 실패 어떤 식으로든 결과가 날 것이다.
.status.phase=Succeeded면 성공, .status.phase=Failed면 실패로 간주될 것이다.
([[#podFailurePolicy]]를 보면 알 수 있듯이 실패로 간주되는 사례가 하나 더 있긴 하다)
파드의 실패에 대해 컨트롤러는 지수적으로(10, 20, 40.. 최대 6분) 재시작 딜레이를 둔다.
이제부터는 완료라는 표현을 성공이나 실패를 나타내는 표현으로 엄격하게 지정하여 사용하겠다.
파드의 완료가 잡의 입장에서 중요하기 때문이다.
참고로 파드의 완료와, 파드의 종료는 또 완전히 다른 개념이다.
파드의 생애주기#파드 단계(phase)를 참고하자.
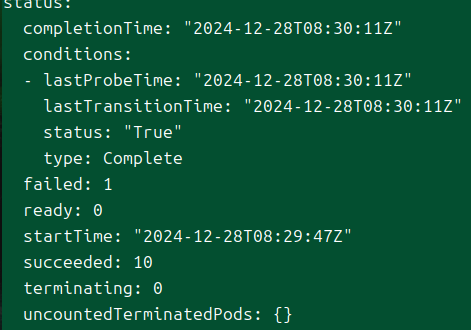
그러면 잡은 그 결과를 자신의 상태에 반영하며, 관리자가 지정한 양식에 따라 자신의 성공과 실패를 판가름할 것이다.
뭐는 성공했고, 실패했고, 준비됐고, 종료 중인지 등등..
그러니까 파드의 성공이나 실패가 잡의 성공과 실패로 직결되는 것이 아니라는 것을 명심할 필요가 있다.
잡은 정의된 요구사항에 맞게 추가적으로 파드를 만들거나, 재생성하거나, 실행 중이던 파드를 종료시키기도 할 것이다.
잡의 완료
성공과 실패
[[#양식 작성법]]에서 전부 나오는 사항들이라 간단하게만 다룬다.
- 성공
- 성공 횟수 넘김
- 성공 조건 만남
- 실패
- 백오프 제한 걸림
- 유효 시간 지남
- 인덱싱 잡
- 인덱스 별 백오프 제한 걸림
- 실패한 인덱스 개수 제한 걸림
- 파드 실패 정책에 걸림
완료 이후
잡은 자신의 파드들의 상태를 통해 최종적으로 자신의 성공과 실패를 결정짓는다.
커스텀이 가능하지만, 기본적으로 잡은 완료됐을 때 다음의 동작을 한다.
- 실행 중(Running)인 파드에 대해선 종료 시그널을 날려버린다.
- 말 그대로 해당 파드들은 궁극적으로 보이지도 않게 사라져버린다..
- 완료한 파드들은 완료된 채로 남아있다.
실행 중인 놈들은 종료시키고, 완료된 놈들은 자신과 함께 그냥 남겨둔다.
그래서 관리자는 파드 로그를 뜯어보면서 에러나 성공 과정을 체크할 수 있다.
Kubernetes v1.31 - Elli 이후부터 잡 컨트롤러는 모든 파드가 종료되기 전까지는 잡의 상태를 업데이트 하지 않는다.
과거에는 안 그랬다고 하는데, 이 당시에는 잡 종료 프로세스가 파드의 상태를 제대로 체킹하지 않는 경우가 있었다고 한다.
잡은 스스로 FailureTarget, SuccessCriteriaMet 컨디션을 추가한다.
이것이 달린 잡은 실행 중인 파드에 종료 시그널을 날린다.
이때 .spec.terminationGracePeriodSeconds를 걸어서 위 컨디션을 늦게 걸게 할 수 있다고 한다.
이 컨디션으로 잡이 완전히 상태 표시 되기 전에 성공과 실패 여부를 미리 알 수 있다.
이 간극이 발생하는 건 잡이 모든 파드가 종료돼야 상태 업데이트가 되기 때문이다.
이걸 통해서 잡이 실패했을 때 빠르게 이 잡을 대체하고 싶다면 FailureTarget을 확인하면 된다.
그게 아니라면 Failed 컨디션이 뜨고, 모든 파드가 종료된 이후에 대체하자.
그 상태 그대로, 잡 자체도 완료된 채로 그냥 사라지지 않고 남아있는데, 이를 커스텀하는 것은 아래에서 보겠다.
유의사항 - 파드 재시작 절차
T-파드가 failed 뜨는 상황이란을 실험하면서, 파드가 restartPolicy=Never일 때 파드가 Failed가 되는 것을 본 적이 있다.
잡에서는 파드의 재시작 정책을 Always로 두는 것이 허용되지 않으며, 가급적 Never로 두는 것을 권장한다.
OnFailure를 사용하면 잡에서 지정한 파드 실패 한도가 파드의 실패가 아니라 컨테이너의 실패로 카운팅되는데, 다음의 안 좋은 점이 있다.
2개 이상의 파드가 실패하면 잡이 실패한다고 체크한다고 쳐보자.
4개의 파드가 동시에 돌아갈 수 있도록 세팅되었다.
1개의 파드는 성공했고, 2개의 파드가 실패해버렸다.
이때, 생각하기로는 아직 실행 중인 파드 하나만 종료돼야 실패 원인을 분석할 수 있다.
그러나 재시작 절차가 OnFailure면 실패한 파드도 싸그리 없어진다.
디버깅 헬 지옥이 열린다..
굳이 하겠다면 최소한 출력물을 보존할 수단을 강구해두는 게 좋다.
그리고 아래에서 소개할 필드 중에 못 쓰는 것들도 생기는데, 아래에서 보자.
인덱싱 잡
양식을 보면서 설명해도 되지만 관련한 기능들이 많아 우선적으로 설명한다.
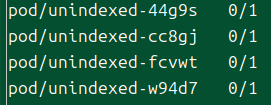
이렇게 잡은 기본적으로 파드들에 대해 순서를 부여하지 않으며, 모든 파드는 동종(homologous)로 간주된다.
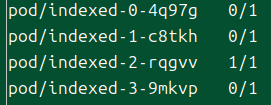
그러나 .spec.compltionMode=Indexed를 두면 파드들은 성공 횟수와 관련하여 번호를 부여받는다.
그리고 각 번호가 성공해야 한다는 조건이 생긴다.
그래서 가령 2번이 성공하고 1번이 실패했다 하면, 1번에 대해 파드가 재생성된다.
다음의 방식으로 해당 번호를 확인할 수 있게 된다.
- 어노테이션
batch.kubernetes.io/job-completion-index - 라벨
batch.kubernetes.io/job-completion-indexPodIndexLaelfeature gate가 활성화돼 있어야 하는데 기본으로 걸려 있다.
- 파드의 호스트네임
{잡 이름}-{번호}- 이걸로 headless Service를 만들어 네트워크 통신도 할 수 있다.
- 컨테이너 내부 환경변수
JOB_COMPLETION_INDEX- Downward API처럼 이걸로 컨테이너는 자신의 번호를 알 수 있다.
잡을 어떻게 쓰냐에 따라 다르겠지만.. 나는 솔직히 어디에 활용될지 크게 감은 잡히지 않는다.
웬만해서 잡에 사용되는 파드들이 서로 달라야 할 필요가 있는가에 대한 의문이 드는 것이다.
이런 건 활용법이 있을 것 같다.
실행해야 하는 작업이 동작 자체는 같지만, 여러 개의 파일이나 리스트에 대해서 진행해야 하는 것이다.
각 원소에 대해 작업이 성공하는 게 관건인 상태에서 하나의 잡으로 관리하고자 한다면, 유효한 방법일 것 같다.
양식 작성법
apiVersion: batch/v1
kind: Job
metadata:
name: indexed
spec:
template:
spec:
containers:
- name: test
image: python
command:
- python3
- -c
- |
import os, sys, time, random
print(os.environ.get("JOB_COMPLETION_INDEX"))
time.sleep(random.random())
if int(os.environ.get("JOB_COMPLETION_INDEX")) % 2:
sys.exit(1)
time.sleep(5)
restartPolicy: Never
completions: 10
completionMode: Indexed
backoffLimitPerIndex: 1
maxFailedIndexes: 2
backoffLimit: 5
parallelism: 4
잡을 만들 때 고려할 만한 요소들을 위주로 예시를 작성했다.
가장 중요한 건 completions(성공 횟수), parallelism(병행 개수), backoffLimit(실패 한도)이 아닐까 한다.
간단하게 설명하자면, 일단 파드는 자신이 어떤 인덱스르르 받았는지를 기준으로 성공과 실패를 가름한다.
이러한 파드가 총 10번 성공해야 하며, 그것도 각 인덱스에 대해서 성공해야 한다.
각 인덱스는 최대 1번까지 실패할 수 있고, 2개의 인덱스가 실패하는 순간 잡은 실패한다.
총합 실패는 5번까지만 허용된다.
동시에 4개가 병렬적으로 생성될 수 있다.
completions
이 필드를 통해 내가 원하는 파드 성공 횟수를 지정한다.
솔직히 그냥 success라 하지 왜 completions이라 했을까.. 싶은..
하위 필드는 아니지만 관련 있는 다른 필드들도 소개한다.
completionMode
기본은 NonIndexed이지만, 여기에서 Indexed를 걸면 [[#인덱싱 잡]]이 된다.
흔한 케이스는 아니지만 같은 번호를 받은 복수 개의 파드가 존재하게 될 수 있는데, 먼저 성공한 파드만 잡의 상태에 반영된다.
노드 실패, kubelet 재시작, 파드 축출 등 원인이야 다양할 거다.
동일한 번호를 받은 파드가 감지되면 잡 컨트롤러가 그 파드를 지운다.
successPolicy
인덱싱 잡을 쓸 때 여러 상황이 있을 수 있다.
각 파드가 다른 인자를 가지고 실행되기에 인덱싱을 하나, 사실 한 파드만 성공하면 될 때.
혹은 파드 간 리더-워커 패턴가 있어서 리더의 성공 실패 여부만 중요한 케이스도 있을 것이다.
completions: 10
completionMode: Indexed # Required for the success policy
successPolicy:
rules:
- succeededIndexes: 0,2-3
succeededCount: 1
이를 위해 성공 정책을 작성하여, 성공해야할 인덱스가 무엇인지 지정할 수 있다.
succeededCount를 지정하면 succeededIndexes의 인덱스 중에 카운트 개수만큼만 성공하면 성공으로 간주한다.
인덱스 지정을 안하면 모든 인덱스를 기준으로 하는데, 사실 그러면 그냥 completions랑 다를 건 없어진다.
잡이 성공하면 컨디션에 SuccessCriteriaMet이 기입된다.
보다시피 룰을 리스트로 나열할 수 있는데, 이 룰은 순서대로 적용되어서 가장 위에 쓰인 조건을 먼저 따진다.
참고로 아래에서 볼 실패 정책과 성공 정책이 같이 일어나면 실패 정책이 더 우선된다.
parallelism
기본적으로 잡은 한 번에 하나의 파드만 실행시킨다.
그러나 멀티 프로세싱, 멀티 쓰레딩하듯이, 병렬적으로 작업을 실행시킬 수 있게 해주는 게 바로 parallelism.
.spec.parallelism을 통해 동시에 실행되는 파드의 개수를 조절할 수 있다.
기본은 1이며 0으로 설정되면 어떤 파드도 실행될 수 없는 상태가 될 것이다.
참고로 여러 이유로 실제 동시 실행되는 파드의 개수는 다를 수 있다!
- 고정된 완료 횟수가 지정되어 있으면 병행 개수는 남은 완료 횟수를 무조건 넘기지 않는다.
- 작업 큐 방식일때는 어떤 파드가 성공한 이후에 새로운 파드는 실행되지 않는다.
- 이미 존재하는 파드가 동시에 성공할 수는 있긴 하다.
- 잡 컨트롤러가 동작할 시간이 주어지지 않은 시점
- 리소스나 권한 부족으로 파드를 생성하지 못하는 상황이라면 파드는 적게 생성될 수 있다.
- 동일한 작업이 계속 실패해 잡 컨트롤러가 새로운 파드 생성을 제한할 수 있다.
backoffLimit

파드는 몇 개까지 실패해도 되는가?에 대한 지정하는 필드.
기본값은 6으로 지정되어 있다.
이때 6이란 것은 실패가 6번까지 허용된다는 말이기에, 결과적으로 7번 파드가 실패하면 잡이 실패한다.
파드 자체가 실패하는 경우도 있을 수 있는데, 이러면 잡 컨트롤러가 알아서 파드를 재시작시켜준다.
[[#유의사항 - 파드 재시작 절차]]에서 말한 실패 한도가 바로 이것이다.
컨테이너는 많은 이유로 실패할 수 있는데, 이때 재시작 정책이 OnFailure라면 파드가 컨테이너를 재시작시킨다.
이때 잡의 backoffLimit은 놀랍게도 이 재시작 횟수를 카운팅한다!
사실 파드가 실패할 일이 거의 없어지기 때문에 그런 것 같기도 한데..
아무튼 OnFailure는 가급적이면 사용하지 맙시다..
이번에도 하위 필드는 아니지만 관련되는 필드들을 소개한다.
backoffLimitPerIndex
completionMode: Indexed # required for the feature
backoffLimitPerIndex: 2 # maximal number of failures per index
maxFailedIndexes: 5 # maximal number of failed indexes before terminating the Job execution
template:
spec:
restartPolicy: Never # required for the feature
containers:
- name: example
image: python
command: # The jobs fails as there is at least one failed index
# (all even indexes fail in here), yet all indexes
# are executed as maxFailedIndexes is not exceeded.
- python3
- -c
- |
import os, sys
print("Hello world")
if int(os.environ.get("JOB_COMPLETION_INDEX")) % 2 == 0:
sys.exit(1)
completionMode=Indexed인 경우, 각 인덱스마다 실패 한도를 지정해줄 수 있다.
각 번호별 파드의 실패 횟수를 지정하는 것이다.

이렇게 각 번호의 실패를 전부 따진 다음 실패한 것이 확인된다.
보다시피 번호 1은 성공했음에도 다른 놈들이 실패하자 실패로 기록되었다.

그리고 누가 트롤짓했는지도 상태값에 기록된다.
달리 말하자면, 거의 모든 번호들이 성공해도 단 하나의 번호에서 실패가 뜨면 잡 자체는 실패로 간주된다.
[[#유의사항 - 파드 재시작 절차]]에서 OnFailure면 못 쓴다는 필드가 이거다.
역시 안 쓰는 게 좋겠지?
maxFailedIndexes
이것도 인덱싱 잡의 경우에 대해 지정하는 것으로, 위의 필드와 조금 관련된다.
backoffLimit으로 전체 실패 한도를 지정할 수 있지만, 위의 필드로 인덱스 별 실패 한도도 지정할 수 있지만..
몇 개의 인덱스가 실패해야 실패인지도 지정할 수 있다.
사실 하나의 인덱스만 실패해도 전체 잡은 원래 실패니까 뭔 상관이냐 싶을 것이다.
그러나 .spec.maxFailedIndexes를 설정해주면 진행되던 모든 파드를 종료시켜버릴 수도 있다.
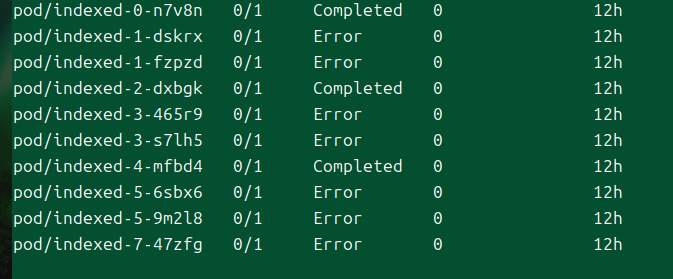
이 필드가 없었으면 원래는 인덱스 9까지 진행을 하여 5개의 번호는 성공한 후에 실패할 잡이었다.
그러나 3개의 번호 파드가 먼저 실패함에 따라 이후 실행 중이던 파드를 모두 종료시켜버렸다.
podFailurePolicy
파드는 리소스 부족, 축출, 노드 오류 등 다양한 이유로 실패할 수 있다.
그래서 구체적으로 어떤 실패를 잡에서 정말 실패로 카운팅해야 하는지 명시해주는 전략이 유효하다.
가령 리소스 부족으로 인한 실패는 실패로 카운팅하고 싶지 않을 수 있다.
그리고 컨테이너의 실패도 어떤 방식으로 오류가 났는지 오류 코드를 여러 가지 내뿜게 할 수 있는데, 이 코드마다 설정을 달리 하고 싶은 경우가 있다.
podFailurePolicy:
rules:
- action: FailJob
onExitCodes:
containerName: main # optional
operator: In # one of: In, NotIn
values: [42]
- action: Ignore # one of: Ignore, FailJob, Count
onPodConditions:
- type: DisruptionTarget # indicates Pod disruption
이런 경우에 .spec.podFailurePolicy에 룰을 작성한다.
onExitCodes로 컨테이너의 종료 코드를 조건으로 걸 수 있다.- 이때 특정 컨테이너 이름을 지정해서 세부적인 커스텀이 가능하며, 안 쓰면 init container까지 포함해서 모든 컨테이너에 대해 적용된다.
onPodConditions를 쓰면 파드의 컨디션을 토대로 조건이 걸린다.
이렇게 조건을 걸고, 취할 액션은 4가지가 있다.
- FailJob - 잡을 통짜로 실패처리한다.
- Ignore - 백오프 제한에 카운팅되지 않고, 파드는 재생성된다.
- Count - 기본 방식으로, 실패가 정상 카운트된다.
- FailIndex - 인덱스별 백오프 제한이 걸렸을 때, 해당 인덱스 실패 처리를 한다.
이 필드를 쓰는 순간부터 중대한 변화가 하나 생긴다.
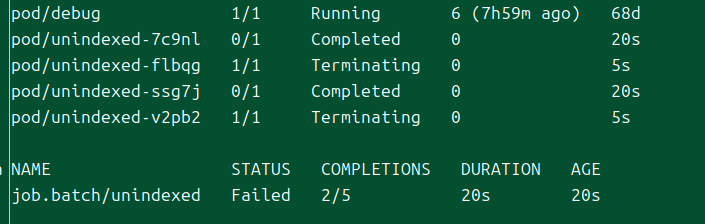
위에는 실행 중인 내가 의도적으로 파드를 지우면서 잡을 실패하게 만든 상황이다.
이걸 보면 알 수 있듯이 기본적으로 잡은 종료되고 있는 파드를 실패로 처리한다!
그러나 이 필드를 쓰게 되면 잡 컨트롤러는 명확하게 Failed 단계인 파드만 매칭한다.
종료 단계인 파드는 그냥 종료일 뿐이다.
그래서 이걸 쓰면 컨트롤러는 정확하게 .status.phase=Failed인 파드에 대해서만 재생성을 한다.
룰은 [[#successPolicy]]처럼 순서대로 적용되며 위에서도 언급했듯 동시에 상황이 나오면 이 실패 정책이 우선한다.
[[#유의사항 - 파드 재시작 절차]]에서 OnFailure면 못 쓴다는 필드가 이거다 222
activeDeadlineSeconds
.spec.activeDeadlineSeconds를 걸어서 아예 잡에 걸리는 시간을 제한을 걸 수 있다.
지정된 시간 안에 잡 성공이 되지 않는 이상 잡이 무조건 실패하는 타임어택을 즐길 수 있다!
파드에도 .spec.activeDeadlineSeconds이 있는데, 이것과는 용도가 다르다.
파드 쪽에서는 어차피 죽어야 할 놈, 잠깐이라도 살려두는 걸 보장하려고 쓰는 거지만 이건 진짜 내가 잡 실행 시간을 지정하고 싶을 때 쓰는 것이다.
ttlSecondAfterFinished
잡은 [[#완료 이후]] 시스템에 남아있긴 하지만, 사실 더 이상 동작하지 않으니 쓸모 없다.
이런 게 쌓이면 kube-apiserver는 부담이 쌓이게 되므로, Cronjob 같은 잡의 상위 컨트롤러를 사용하는 것은 좋은 선택지다.
그런데 여기에 다른 방법도 있다.[2]
.spec.ttlSecondAfterFinished를 두면, 잡이 완료된 이후 생존 시간(Time To Live) 이후 잡은 삭제된다.
내부적으로는 TTL 컨트롤러가 활용되는데, 오직 완료된 잡을 위해서만 작동하는 컨트롤러이다.
잡은 완료된 시점이 기록되는데, 이것을 기준으로 TTL이 돌아간다.
이 TTL 조건은 언제든 걸 수 있다.
- 처음부터 양식에 써넣기
- 이미 끝났거나 진행 중인 잡에 수정하여 넣기
- Admission Webhook 걸기
- 특정 셀렉터를 만족하는 잡에 ttl을 추가하는 커스텀 컨트롤러 만들기
뭐.. 요지는 결국 다 양식에 ttl 조건을 걸어주는 방식인 것이다.
근데 괜히 ttl이 만료된 잡에 갑자기 ttl을 연장하거나 하진 말자.
해당 요청이 성공하더라도 이미 잡이 종료 수순에 들어갔으면 돌이킬 수 없다.
상위 컨트롤러를 이용하지 않은 모든 잡에 대해서는 이것을 설정하는 게 강력하게 권장된다.
왜냐하면 기본 삭제 정책이 orphanDependents라 하여 잡이 사라져도 파드가 안 사라지는 경우가 종종 있기 때문이라고..
궁극적으로야 결국 가비지 컬렉팅될 것이지만, 그럼에도 리소스를 많이 잡아먹는 잡들이 남아 성능에 영향을 줄 수 있다.
잡을 자유롭게 쓰고 싶다면, 최소한 네임스페이스를 분리하고 제한된 리소스만 사용할 수 있게 걸어두는 것을 추천한다.
기타
여기에서는 조금 잡을 다양하게 활용하는 방법을 다룬다.
작업 중지
잡은 보통 생성된 이후 지정된 설정에 따라 계속 파드를 만든다.
하지만 잠깐 중단하고 싶다면?
.spec.suspend 양식을 작성하여 true로 걸면 작업이 중단된다.
필드를 없애면 다시 작업이 재개될 것이다.
다른 워크로드처럼 rollout을 이용할 수는 없다..
중단하고 다시 시작하면 startTime, activeDeadlineSeconds가 초기화된다.
또한 중단 시에는 완료되지 않은 모든 파드에 대해 종료 시그널을 날린다.
kubectl patch job/myjob --type=strategic --patch '{"spec":{"suspend":true}}'
간단하게 빠르게 날리고 싶다면 이렇게 하자.
이걸 또 어디에 쓸 수 있는가?
가령 파드가 실행된 노드에 집중적으로 잡을 배치하고 싶다거나, 반대로 하고 싶다면, 중지를 걸어두고 양식을 수정할 수 있다.
이때 Affinity, 노드 셀렉팅, 테인트, 톨러레이션 등을 수정해주면 된다.
파드 셀렉터에 대해
웬만하면 잡을 만들 때 셀렉터를 명시하지 말라.
batch.kubernetes.io/controller-uid: a8f3d00d-c6d2-11e5-9f87-42010af00002
위와 같이 시스템에서 알아서 다른 잡과 중복될 수 없는 셀렉터를 만들어준다.
그럼에도 이런 상황을 생각해볼 수 있다.
이전 잡의 양식을 수정해서 새로운 잡을 만들고 싶은데, 그래도 이전 잡의 작업 사항이 새로운 잡에 영향이 가게 하고 싶다.
그렇다면 일단 이전 잡은 --cascade=orphan으로 지워서 파드를 남겨둔 상태에서, 새로운 잡 스펙에는 manualSelector=True로 적은 후 직접 이전과 같은 셀렉터를 달아주면 된다.
파이널라이저
batch.kubernetes.io/job-tracking이란 Finalizer가 잡이 만든 파드에 기본적으로 장착된다.
해당 파드의 상태가 완벽하게 잡에 보고되어 상태 입력이 완료된 후에 이것은 제거된다.
이후에 다른 컨트롤러, 혹은 수동으로 해당 파드를 지울 수 있게 된다.
유동적인 인덱스 잡
혹시 잡을 스케일링하고 싶은.. 경우가 있다면, 병행 수와 완료 개수를 동시에 늘려주자.
인덱스 잡의 좋은 점은 스케일 인을 할 때 큰 번호부터 지워진다는 것이다.
완벽하게 파드가 실패한 후 재생성하기
기본적으로 잡은 한 파드가 종료 상태인 순간 다른 파드를 재생성한다.
그래서 설정한 병행 수보다 파드가 많아지는 순간이 존재하게 된다.
이를 방지하고 싶다면 spec.podReplacementPolicy=Failed로 설정하자.
외부 컨트롤러로 위임
Kubernetes v1.32 - Penelope 기준 베타 기능로 JobManagedBy feature gate를 활성화하면 managedBy를 사용할 수 있다.
이걸 이용해 기본 잡 컨트롤러가 아닌 커스텀 컨트롤러를 사용할 수 있게 된다.
대안
다른 방식들과 많이 다르고 특색은 충분히 드러나는 것 같아서 크게 언급할 만한 대안은 없다고 생각한다.
다만 파드가 파드를 만들게 하는 방식을 사용해볼 수도 있기는 하다.
대표적인 패턴의 예시가 스파크 마스터 컨트롤러가 스파크 드라이버를 만들었다가 지우는 작업이라고 한다.
내 생각에는 높은 결합도가 요구되거나 상관 없는 곳에서 유효한 방식인 것 같다.
관련 문서
참고
진짜 잡 정리가 역대급으로 힘들었다.
파드보다 더 힘들었던 듯.
문서가.. 개인적으로 너무 읽기 힘들게 정리돼있다고 생각한다.