eBPF
개요
![]()
extended Berkely Packet Filter.
리눅스를 확장해주는, 최근 어무막지하게 각광받는 기술 중 하나이다.
복잡해져버린 리눅스 커널 스택과 독립적으로 커널 레벨에서 샌드박스 프로그램을 실행할 수 있게 해준다.
무얼 하든 ebpf를 이용하는 기술이면 다른 것과 비교해서 월등한 속도가 보장된다고 해도 과언이 아닐 정도이다..
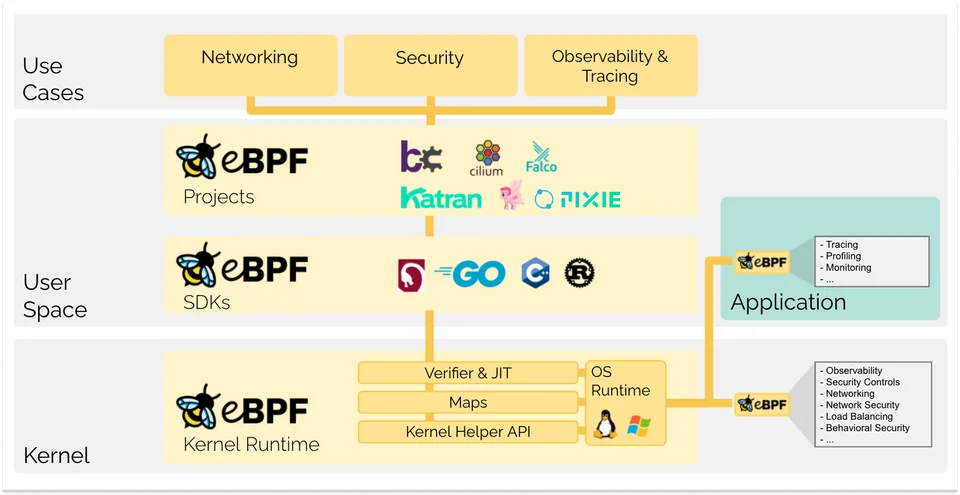
커널 정도의 특별한 권한이 있는 환경에서 샌드박스 프로그램을 실행할 수 있는 기술이다.
커널 코드나 모듈에 대한 로딩 없이 기존 커널의 기능을 안전하고 효율적으로 확장시킬 수 있다.
구체적으로 ebpf가 가지는 장점은 다음의 것들이 있다.
- 빠른 속도 - 커널 레벨에서 코드가 실행되기 때문에 불필요한 과정을 건너뛰어 원하는 기능이 빠르게 실행된다.
- 동적 로딩 - 커널을 재시작하지 않고도 원하는 코드를 런타임 중에 삽입할 수 있다.
- 안정성 - 커널 레벨에서 실행되더라도 매우 엄격한 검증을 통해 코드가 검사되어 커널을 망가뜨리지 않을 것이 보장된다.
내가 처음 이걸 접했을 때가 Cilium이었던 것 같다.
그때도 이게 뭐지 하면서 검색을 했다가 경을 치고 손사래를 쳤었는데, 네트워크 지식도 부족한데 커널 레벨의 뭔가를 한다길래 너무 무서웠다..
그러나 쿠버네티스의 여러 가지를 깊게 파고들다 보니 필연적으로 마주칠 수밖에 없는 운명이었던 것 같다.
그렇다면 공부해봐야지.
내친 김에 내가 활용하거나 코드를 읽을 수 있을 정도로는 파봐야겠다.
배경
리눅스에서는 사용자가 만드는 모든 코드는 유저 스페이스에서 실행된다.
이 공간은 하드웨어와 자원을 직접적으로 활용하는 커널 스페이스와 분리된 공간으로, 각종 커널 레벨에서 필요한 자원을 활용할 때 syscall이라는 인터페이스를 통해 커널에 동작을 요청하게 된다.
단순하게 http 요청을 날리는 코드가 있다고 쳐보자.
conn, err := net.Dial("tcp", "example.com:80")
if err != nil {
fmt.Println("Dial error:", err)
return
}
defer conn.Close()
request := "GET / HTTP/1.1\r\n" +
"Host: example.com\r\n" +
"Connection: close\r\n" +
"\r\n"
_, err = conn.Write([]byte(request))
if err != nil {
fmt.Println("Write error:", err)
http 요청을 위해서는 먼저 tcp 커넥션을 만들어야 하고, 이 커넥션은 출발지와 목적지, 프로토콜 유형 등의 정보가 담겨있는 소켓 구조체를 필요로 한다.
이때 소켓 구조체를 얻고 통신을 보내기 위해서 socket(), 이후 connect() 등의 syscall을 내부적으로 사용하게 된다.
이렇게 리눅스에서는 커널 스페이스와 유저 스페이스를 명확하게 분리하고 유저 스페이스에서는 syscall만을 이용해 실제 필요한 동작들을 할 수 있도록 발전했다.
이러한 방식은 커널을 망가뜨릴 수 있는 임의의 코드 실행을 막아 안정성을 보장하나, 성능이나 깊은 모니터링을 하고 싶을 때 걸림돌이 되는 지점이기도 하다.
ebpf가 개발된 배경에는 결국 리눅스 커널 레벨에 대한 동작을 하고 싶다는 것이 핵심이었는데, 깊게는 네트워크와 관측성에 대한 관심이 컸다고 한다.
리눅스 커널 레벨에 대한 동작을 하고 싶다는 것이 핵심 페인 포인트인데, 깊게는 네트워크와 관측성에 대한 관심이 컸다고 한다.

리눅스에서 제공하는 네트워크 플로우 다이어그램(어떤 부분에서 syscall을 할 수 있는지)인데, 딱 봐도 매우 복잡해보인다.
리눅스의 네트워크는 모뎀 시절, 그러니까 속도와 성능이 중시되지 않던 시대에서 시작해서 점차 코드가 쌓여갔다.
사용자 공간에서 활용될 수 있는 dpdk라는 툴들이 개발되었으나 이들도 상당한 제한이 많았다고 한다.
모니터링의 영역에서도 커널 레벨은 예로부터 전체 시스템을 관측하고 제어할 수 있는 이상적인 공간이었다.
그래서 관측 가능성, 보안, 네트워킹 분야에서 항상 커널을 건드리려는 시도가 많았다.
그러나 너무나도 방대해져버린 커널 진영 탓에, 개발은 항상 더딜 수밖에 없었다.
이런 상황에서 나온 게 1992년 Berkely Packet Filter로, 패킷 필터링을 확장할 수 있도록 만들어진 기술이었다.
(참고로 ebpf와 구분짓기 위해 기존의 bpf는 Classic bpf라고도 부른다고 한다.)
그리고 이것이 더 확장되면서 eBPF가 되었는데, 오늘날에는 패킷 필터링 이상의 기능을 할 수 있기에 이름은 그다지 의미는 없다고 한다.
애플리케이션 개발자는 각종 코드를 커널 레벨에 동작시키며 운영 체제에 추가 기능을 제공할 수 있게 됐다.
운영체제는 jit 컴파일러와 검증 엔진의 도움으로 이 프로그램들이 커널 레벨에서 안전하고 효율적으로 동작하는 것을 보장할 수 있다.
ebpf는 커널 내부에서 동작하면서 OS와 협업한다.
그러면서 커널 스택을 스킵하고 독자적인 툴로서 새로운 아키텍쳐를 세울 기반이 된다.
또한 커널을 개발하는 진영의 지원과 개발로부터 자유롭게 원하는 동작을 커널 단에서 실행시킬 돌파구가 생긴 것이라 개발이 자유로운 편이다.
결론적으로 ebpf가 각광받는 것은, 너무나도 복잡해지고 큰 병목을 일으키는 리눅스 기본 커널 네트워크 스택에서 자유롭게 원하는 동작을 커널 레벨에서 수행할 수 있다는 것으로 이해하면 될 것 같다.
참고로 이 꿀벌은 eBee라고 부른다고 합니다..
동작 방식
그래서 도대체 어떻게 동작한다는 것인가?
훅
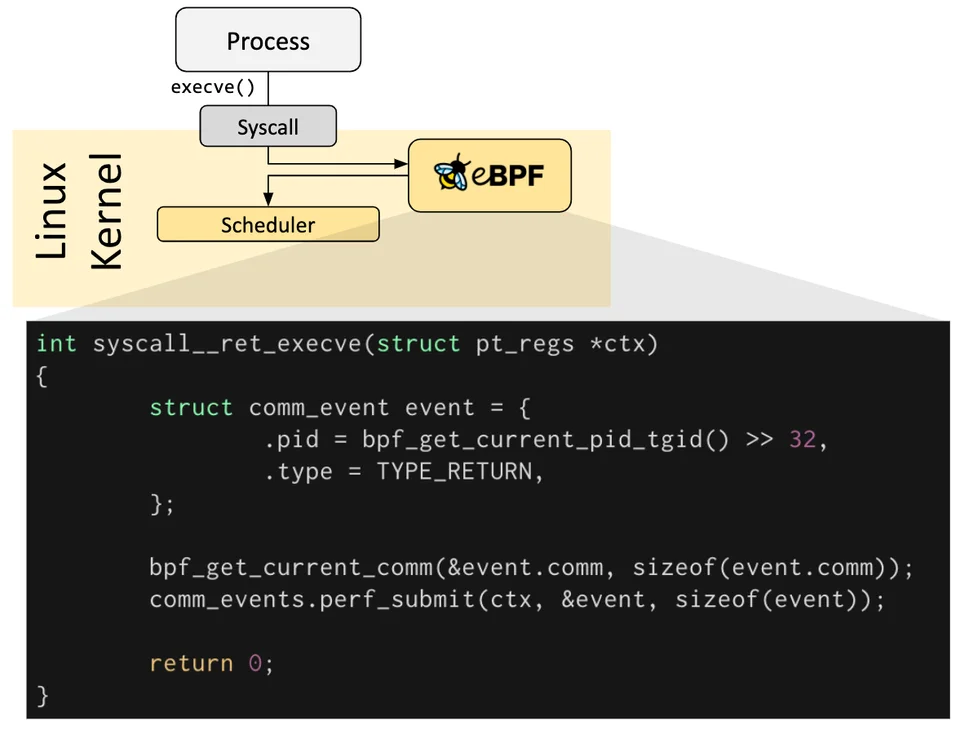
ebpf는 결국 코드를 실행시킬 수 있는 훅이다.
os 레벨에서 특정 이벤트에 따라 훅이 발동될 때, 원하는 프로그램이 실행되도록 하는 것이다.
사전 정의된 훅들이 있어서 이때 원하는 코드가 실행되도록 해주면 된다.
만약 원하는 훅이 없다면, 커널 프로브(kprobe), 혹은 유저 프로브(uprobe)를 이용해 원하는 위치에 프로그램을 부착시켜버릴 수도 있다.
네트워크 트래픽 흐름 상으로 보자면, 아래와 같이 다양한 포인트에 훅이 존재해서 코드를 박을 수 있다.

참고로 실리움에서 핵심적으로 트래픽 관리를 위해 건드리는 부분은 아래 TC, XDP 부분이다.
개발 방법
cilium, bcc, bpftrace등 ebpf를 추상화시켜주는 프로젝트가 여러 개 있다.
이것들이 사용자의 의도에 따라 ebpf 프로그램을 자동으로 구현하며, 이걸 토대로 개발을 진행하면 된다.
더 커스텀을 하고 싶다면 바이트 코드를 직접 만들어야 하는데, 이때는 llvm과 같은 컴파일러를 통해 c와 비슷한 코드를 만들어 올리면 된다고 한다.
프로그램 빌드
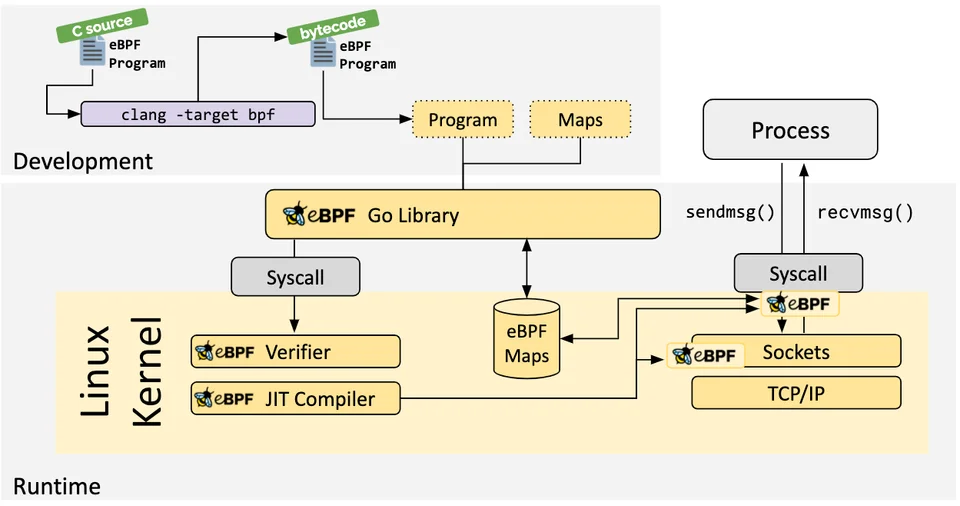
로더 및 검증 아키텍처는 대충 이렇게 표현할 수 있다.
간단하게 말하자면, 개발자가 코드를 실행하면 이것이 검증과 jit 컴파일 과정을 거쳐 커널에 들어간다.
훅이 발동되면 bpf 시스템 콜을 통해 ebpf 프로그램이 실행된다.
검증
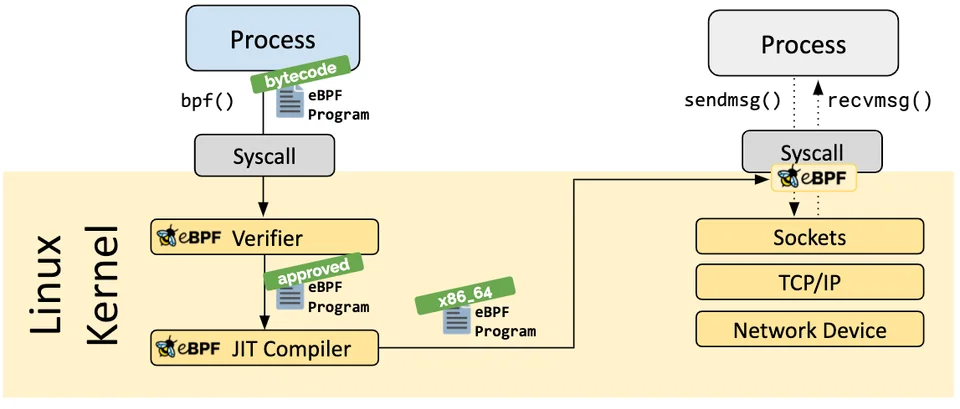
구체적으로는 커널 내부로 먼저 동적으로 로드되는데, 이때 검증과 컴파일을 거친다.
위의 그림으로 보면 ebpf 관련 Go 라이브러리를 통해 만든 코드가 시스콜로 들어가서 검증과정을 거친다.
이 과정이 매우 까다롭다고 하는데, 아무래도 안전성 때문에 당연한 것 같다.
간단하게만 보자면..
- ebpf를 로드하는 프로세스 자체가 특별 권한, root여야 한다.
- 반드시 종료되도록 구현돼야 한다.
- 루프를 돌 수는 있으나, 종료되는 것이 보장돼야 한다.
- 크래시나 악영향을 끼치지 않는 것이 보장되어야 한다.
- 초기화되지 않은 변수, 영역을 벗어난 메모리 접근 전부 불가
- 시스템에서 요구하는 크기를 만족해야 한다.
- 유한한 복잡성, 즉 실행 경로에 대한 검사도 이뤄진다.
이후에는 경화(hardening) 과정이 일어난다.
- 프로그램을 실행하는 내부 메모리는 읽기전용으로 생성된다.
- 어떠한 임의의 조작이 일어날 경우 커널은 바로 크래시를 일으킨다.
- 취약점 대처
- cpu 분기를 잘못 예측해 사이드 채널 공격을 할 가능성을 차단한다.
- 이를 위해 일시적 명령어로 메모리 마스킹 등의 작업을 한다.
- 상수 마스킹
- jit 스프레이 공격을 방지하기 위해 변수를 가린다.
JIT 컴파일
검증을 통과하면 Just-in-Time 컴파일 과정이 다음에 일어난다.
이건 말 그대로 프로세스가 돌아가는 와중에 컴파일을 바로 해서 프로세스를 실행하는 바이너리에 갖다붙이는 기술이다.
맵
ebpf가 활용할 수 있는 메모리 공간이라고 보면 된다.
이 맵을 통해 ebpf 프로그램은 각종 정보를 불러오고 저장할 수 있다.
사용할 수 있는 자료 구조의 예시는 다음과 같다.
- 해시 테이블, 배열
- LRU
- 링 버퍼
- 스택 추적
- LPM(Longest Prefix Match)
헬퍼 함수
ebpf가 임의의 커널 함수를 호출할 수 있는 건 아니다.
대신 커널에서 열어주는 api를 호출할 수는 있는데, 이 목록은 점점 늘어나고 있다고 한다.
다음과 같은 예시가 있다.
- 랜덤 숫자 생성
- 현재 시간 및 날짜 조회
- ebpf 맵 조회
- 프로세스, cgroup 컨텍스트 가져오기
- 네트워크 패킷 및 전달 로직 조작
꼬리 재귀 및 함수 호출
ebpf 프로그램 끼리는 서로 호출하고 심지어 재귀도 가능하다.
이건 execve 시스템 콜이 프로세스에서 동작하는 방식과 유사하다.
장점
원래 리눅스 커널에 대해서 개발자는 함부로 접근할 수 없다.
다만 하드웨어를 추상화해주며 제공되는 시스템 콜 인터페이스(SCI)를 통해 사용자 공간에서 이를 조작할 수 있을 뿐이다.

커널에 대해서 필요한 기능이 있다면? 위의 과정을 거쳐야만 한다.
이런 과정이 없어지니까 가히 혁명이라 하는 것이다.
관련 도구
bcc
파이썬 프로그램에 ebpf를 작성할 수 있게 하는 프레임워크이다.
아래 튜토리얼에서 사용하는 모습을 간단하게 볼 수 있다.
bpftrace
llvm을 사용해 스크립트를 ebpf 바이트코드로 컴파일한다.
bpftool
bpf 관련 조작을 수행할 수 있는 cli 툴.
튜토리얼에서 나오듯이, 맵부터 trace, 코드 상태 등에 대한 다양한 추적을 할 수 있다.
직접 개발하지 않는 입장에서도 디버깅을 할 때 유용하게 사용할 수 있지 않을까 한다.
설치
직접 빌드하여 사용할 수 있도록만 지원하고 있다.[1]
git clone --recurse-submodules https://github.com/libbpf/bpftool.git
cd bpftool/src
make install
만약 make가 없다면 관련한 툴도 없는 것이다.
# make가 없다면 이렇게
apt install -y build-essentials
# 나머지 의존성
apt install -y libelf-dev zlib1g
튜토리얼
랩을 통해 기본적인 연습을 해볼 수 있다.[2]
hello world
#!/usr/bin/python3
from bcc import BPF
program = r"""
int hello(void *ctx) {
bpf_trace_printk("Hello World!");
return 0;
}
"""
b = BPF(text=program)
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
b.trace_print()
간단하게 hello world를 출력하는 예제이다.
ebpf 프로그램은 program이라는 문자열 변수로 커널에 저장될 것이다.
이 파이썬 스크립트는 이 프로그램을 커널에 로드하고, execve(프로세스 실행) 시스콜이 실행될 때마다 발동되는 kprobe에 달라붙는다.
그래서 이 프로그램을 실행한 후 다른 터미널에서 아무 명령어를 치면, ebpf의 hello world가 출력될 것이다.

실행되지 않는 임의의 문자를 그냥 입력했더니 이렇게 나왔다.
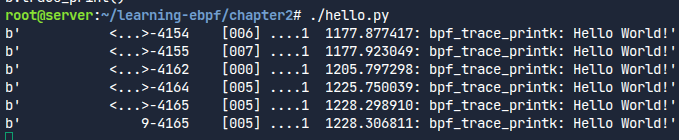
ls, echo 등 각종 명령어들을 실행해봤다.
더 이상 안 보고 싶으면 그냥 ctrl + c를 하면 된다.
그럼 bpf 코드를 보자.
매개 인자는 이 함수가 발동될 때 들어오는 정보이다.
bpf_trace_printk는 헬퍼 함수이다.
map
bpf 코드가 실행될 때 사용할 수 있는 메모리 공간, 데이터 구조.
#!/usr/bin/python3
from bcc import BPF
from time import sleep
program = r"""
BPF_HASH(counter_table);
int hello(void *ctx) {
u64 uid;
u64 counter = 0;
u64 *p;
uid = bpf_get_current_uid_gid() & 0xFFFFFFFF;
p = counter_table.lookup(&uid);
if (p != 0) {
counter = *p;
}
counter++;
counter_table.update(&uid, &counter);
return 0;
}
"""
b = BPF(text=program)
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
# Attach to a tracepoint that gets hit for all syscalls
# b.attach_raw_tracepoint(tp="sys_enter", fn_name="hello")
while True:
sleep(2)
s = ""
for k,v in b["counter_table"].items():
s += f"ID {k.value}: {v.value}\t"
print(s)
조금 더 코드가 복잡해졌다.
맵을 쓰는 방법은 다양한데, 이 중에서 counter_table이란 이름으로 hash 테이블을 만드는 예제이다.
유저 공간에서는 bpf 인스턴스의 키로 접근할 수 있다.
uid를 또 헬퍼 함수로 가져오는데, 이때 gid도 가져온다.
그래서 하위 4바이트만 살리고자 and 처리해버린다.
해시테이블에서 룩업을 하며 해당 uid가 있는지 확인한다.
검증기에서 0값을 참조하는 것을 매우 싫어하는 관계로 null 체크는 꼼꼼히!
테이블에 없다 싶을 때만 업데이트를 하는 것이다.
counter는 직관적으로 테이블에서의 위치를 담는 변수다.
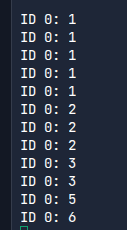
execve가 호출될 때마다 이렇게 한 uid의 실행값이 점점 업데이트되는 것이 보인다.
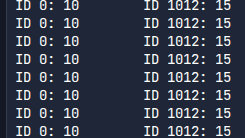
다른 유저로 (예제에서는 liz라는 유저를 미리 만들어줌) 들어가면 이때부터는 새로운 유저에 대한 정보도 나온다.
bpftool
bpf를 사용하는데 있어 유용한 유틸리티.
사실 ebpf는 내부적으로 일종의 가상 머신을 만든다.
그래서 10개의 레지스터를 가진다.
검증 과정을 거친 후, vm에 실행되는 꼴이다.
bpftool prog list
bpf가 실행되고 있을 때 이렇게 실행을 해본다.
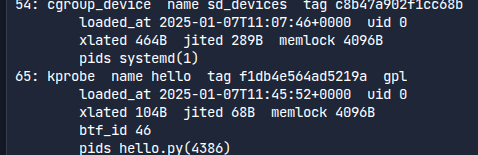
이렇게 커널에 들어간 함수들을 확인할 수 있다.
4386이란 프로세스id로 실행된 것을 볼 수 있다.
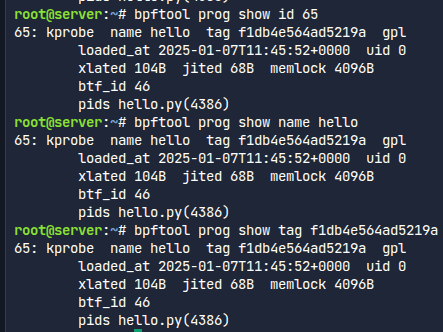
이렇게도 내가 실행한 프로그램을 확인할 수 있다.
int hello(void * ctx):
; int hello(void *ctx) {
0: (b7) r1 = 560229490
; ({ char _fmt[] = "Hello World!"; bpf_trace_printk_(_fmt, sizeof(_fmt)); });
1: (63) *(u32 *)(r10 -8) = r1
2: (18) r1 = 0x6f57206f6c6c6548
4: (7b) *(u64 *)(r10 -16) = r1
5: (b7) r1 = 0
6: (73) *(u8 *)(r10 -4) = r1
7: (bf) r1 = r10
;
8: (07) r1 += -16
; ({ char _fmt[] = "Hello World!"; bpf_trace_printk_(_fmt, sizeof(_fmt)); });
9: (b7) r2 = 13
10: (85) call bpf_trace_printk#-108128
; return 0;
11: (b7) r0 = 0
12: (95) exit
bpftool prog dump xlated name hello로 덤프를 뜰 수도 있다.
간단하게만 보자면.. 일단 앞에 숫자는 메모리에서 해당 코드의 인덱스를 나타낸다.
그리고 뒤의 괄호는 opcode, 즉 명령어 집합 번호를 나타낸다(컴구 으윽).
0번에서는 56~숫자를 레지스터1에 저장하고 있는 것이다.
마지막에 r0에는 관례적으로 종료 코드를 넣게 된다.
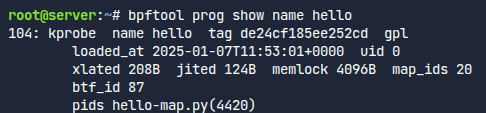
이번에는 map을 사용했던 코드를 본다.
여기에는 map id 정보도 있는 것이 보인다.
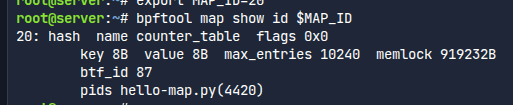
이렇게 해당 맵 정보도 볼 수 있다.
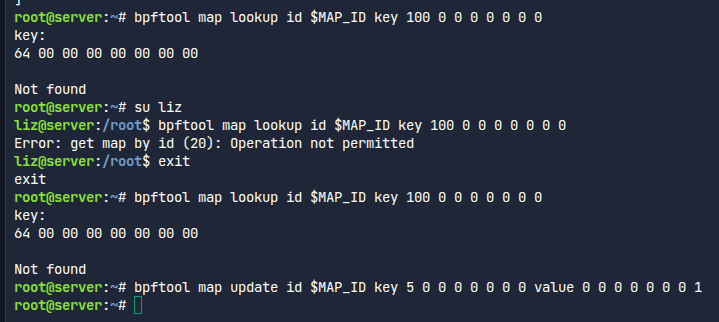
맵 속 내용을 볼 수도, 업데이트도 할 수 있다.
network packet and XDP
XDP는 eXpress Data Path의 약자로, l2 인터페이스에서 네트워크 패킷을 가져오는 경로 인터페이스이다.
이걸 통해 각종 네트워크 작업을 할 수 있게 되는 것이다.
이제부터는 파이썬이 아니라 c로 컴파일한다.
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
int counter = 0;
SEC("xdp")
int hello(struct xdp_md *ctx) {
bpf_printk("Hello World %d", counter);
counter++;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "Dual BSD/GPL";
c에서 직접 코드를 짤 때는 이렇게 한다.
일단 bpf 라이브러리를 가져온다.
SEC("xdp") 매크로를 사용해 네트워크 인터페이스에 붙인다.
XDP_PASS를 반환하면 네트워크 패킷을 그대로 네트워크 스택으로 반환하게 된다.
마지막에는 라이센스를 붙이는데 이것도 검증 요소 중 하나이기 때문이다.
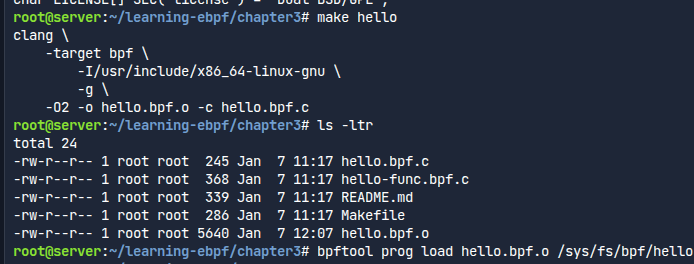
코드를 빌드하여 목적 파일을 만들고, 이를 로드한다.
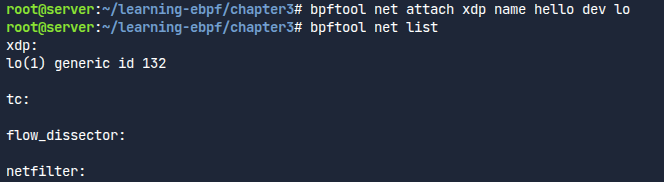
아직 이 프로그램을 실행할 이벤트에 연결이 안 됐다.
그래서 다음의 명령어를 통해 루프백 인터페이스를 프로그램과 붙인다.

제대로 붙었다면 이렇게 ip(명령어)로도 확인이 된다!
이제 본격적으로 트레이싱을 하고 싶다!
bpftool prog trace log를 사용하면 되는데, 이것은 /sys/kernel/debug/tracing/trace_pipe라는 가상 파일을 그냥 출력해주는 것이다.
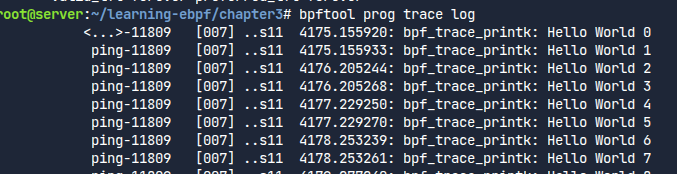
로컬에 핑을 날리자 이렇게 출력물이 나오기 시작했다.
만약 여기에서 패킷을 드랍시키고 싶다면, 반환 값을 XDP_DROP을 주면 된다.
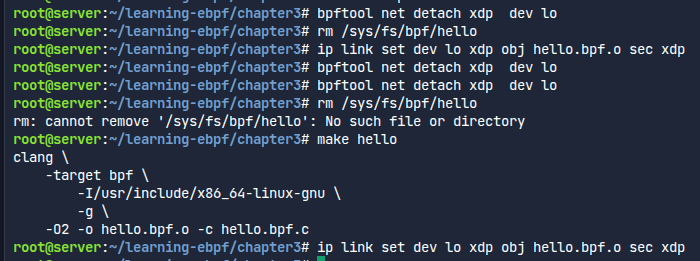
코드를 바꿨으니 다시 빌드하고, 인터페이스에서 기존의 목적파일을 떼어낸다.
추가적으로 커널에 로드된 것도 없앨 수 있게 /sys/fs/bpf/hello도 없애준다.
마지막처럼 ip명령어로 목적파일을 붙일 수도 있다고 한다.
이 상태로 ping을 하니 hello world는 찍히지만 모든 패킷이 버려져 ping은 아무런 응답을 받지 못한다.
verifier
검증기는 커널로 들어가는 프로그램을 전부 검증한다.
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#include "hello-verifier.h"
int c = 1;
char message[12] = "Hello World";
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__uint(key_size, sizeof(u32));
__uint(value_size, sizeof(u32));
} output SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10240);
__type(key, u32);
__type(value, struct msg_t);
} my_config SEC(".maps");
SEC("ksyscall/execve")
int kprobe_exec(void *ctx)
{
struct data_t data = {};
struct msg_t *p;
u64 uid;
data.counter = c;
c++;
data.pid = bpf_get_current_pid_tgid();
uid = bpf_get_current_uid_gid() & 0xFFFFFFFF;
data.uid = uid;
p = bpf_map_lookup_elem(&my_config, &uid);
// The first argument needs to be a pointer to a map; the following won't be accepted
// p = bpf_map_lookup_elem(&data, &uid);
// Attempt to dereference a potentially null pointer
if (p != 0) {
char a = p->message[0];
bpf_printk("%d", a);
}
if (p != 0) {
bpf_probe_read_kernel(&data.message, sizeof(data.message), p->message);
} else {
bpf_probe_read_kernel(&data.message, sizeof(data.message), message);
}
// Changing this to <= means and c could have value beyond the bounds of the
// global message array
// if (c <= sizeof(message)) {
if (c < sizeof(message)) {
char a = message[c];
bpf_printk("%c", a);
}
// Changing this to <= means and c could have value beyond the bounds of the
// data.message array
// if (c <= sizeof(data.message)) {
if (c < sizeof(data.message)) {
char a = data.message[c];
bpf_printk("%c", a);
}
bpf_get_current_comm(&data.command, sizeof(data.command));
bpf_perf_event_output(ctx, &output, BPF_F_CURRENT_CPU, &data, sizeof(data));
return 0;
}
SEC("xdp")
int xdp_hello(struct xdp_md *ctx) {
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
// Attempt to read outside the packet
// data_end++;
// This is a loop that will pass the verifier
// for (int i=0; i < 10; i++) {
// bpf_printk("Looping %d", i);
// }
// This is a loop that will fail the verifier
// for (int i=0; i < c; i++) {
// bpf_printk("Looping %d", i);
// }
// Comment out the next two lines and there won't be a return code defined
bpf_printk("%x %x", data, data_end);
return XDP_PASS;
}
// Removing the license section means the verifier won't let you use
// GPL-licensed helpers
char LICENSE[] SEC("license") = "Dual BSD/GPL";
이게 검증기 속 긁는 예시라고 보면 되겠다.
관련 문서
| 이름 | noteType | created |
|---|
참고
ㅋㅋㅋ
이 친구들 맘에 드는데..?[3]
https://isovalent.com/labs/learning-ebpf-tutorial/?utm_source=website-ebpf&utm_medium=referral&utm_campaign=ebpf-lab ↩︎
https://labs-map.isovalent.com/?utm_medium=email&_hsenc=p2ANqtz-_C_p3fiuiG9zdK80ikaMybHzvF3gRH1qbjY_4bGtl4hIKiCCGyjCbgL0zFwykOGmNb1Xmf5IJNSvrA1JNLBFWFnHpd0g&_hsmi=338984370&utm_content=338984370&utm_source=hs_automation ↩︎