스토리지
개요
쉽게 말하면 데이터 저장소.
스토리지는 따지자면 소프트웨어적인 개념이라고 생각한다.
하드웨어 스토리지라고 한다면 그것은 통상 디스크라고 부른다.
그러나 디스크를 또 스토리지라고 부르기도 하는 등, 스토리지는 정말 폭넓게 사용되는 표현이다.
나는 레이드를 생각하다보니 디스크랑 스토리지는 분리해서 부르는 게 낫다고 생각한다.
필요성
연산 장치로서의 컴퓨터는 사실 연산을 담당하는 cpu만 있어도 성립할 수 있을 것이다.
그러나 더 복잡한 연산을 하기 위해서 이전 연산의 결과를 저장할 필요가 있고, 그래서 메모리(하드웨어로서는 RAM)가 존재한다.
근데 이조차도 사실 충분하지 않다.
메모리는 가격이 비싸고 cpu와 가까워야 한다는 물리적 제약이 있어, 더 많은 양의 결과를 저장하고 활용하기 위해 보조기억장치가 따로 필요하다.
현대 컴퓨터 아키텍처는 이러한 방향으로 진화되었고, 데이터를 저장한다는 것 자체가 하나의 컴퓨터의 중요한 개념으로 자리잡게 되었다.
그래서 보조기억장치, 데이터를 저장하는 무언가를 우리는 스토리지라고 부른다.
연결 방식
스토리지를 연결하는 방식에 따라 크게 3가지로 종류가 나뉜다.
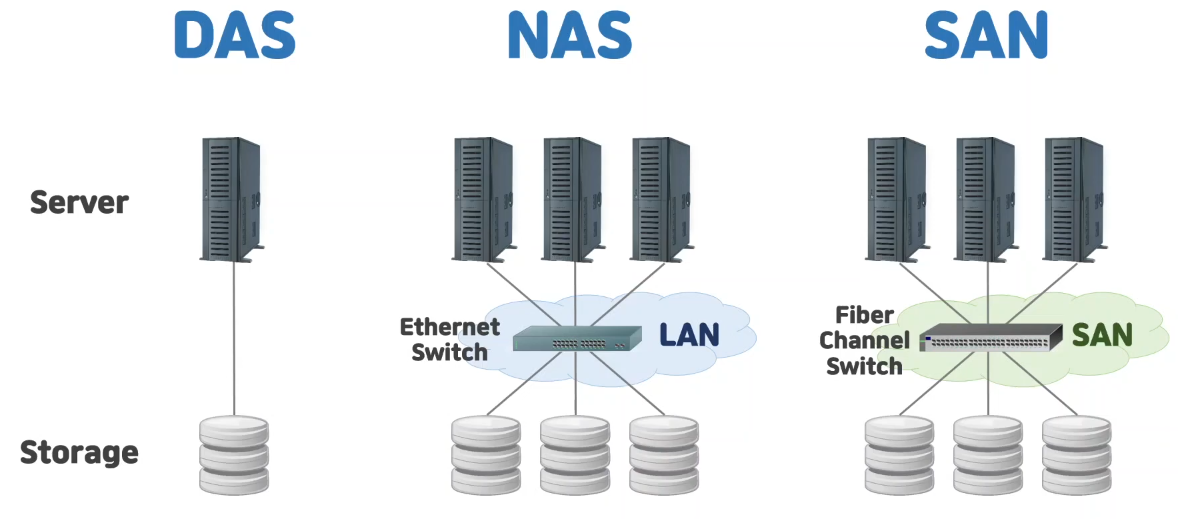
DAS
Direct Attached Storage
그냥 말그대로 꽂아버린다.
별 거 없다.
그냥 우리가 쓰는 컴퓨터는 일단 다 이렇게 스토리지가 구성돼있다.
케이블로 연결하게 된다.
NAS
NAS에 따로 정리한다.
SAN
Storage Area Network
저장 지역 통신망
이건 그냥 저장하는 것을 아예 진짜 서버화 시킨 느낌이라고 보면 될 것 같다.
FC(Fiber Channel Switch)를 통한 고속 네트워크 연결을 특징으로 한다.
그러면서도 이더넷 연결도 가능하기는 하다.
DAS와 NAS의 결합체처럼 볼 수 있다.
일단 DAS처럼 전용 광케이블을 따로 사용하며 NAS처럼 네트워크로 연결된다.
이 놈은 전용 케이블을 사용하는 만큼 고속이다.
또한 아래에서 볼 블록 스토리지 형태로 사용된다.
용량 확장도 용이하기에 대규모 데이터베이스를 구축할 때 용이하다.
대신 그 만큼의 가격을 감당해야 한다고 한다.
개인적으로, 아직 이 놈은 실물로 영접해본 적이 없어서 감이 잘 오지 않는다.
특히 개인 환경에서 사용할 일이 없는 녀석이라 더 그런 것 같기도 하다.
대체 얼마나 빠르고, 얼마나 비싼 걸까..?
저장 방식
그럼 우리는 어떤 데이터를 어떤 방식으로 저장할 수 있을까?
대충 말하자면 아래에서 설명할 방식들은 내려갈수록 한 단계씩 추상화되는 방식이다.
스토리지를 서비스로 사용하는 입장에서 어느 정도의 추상화 상태로 이용할 것이냐, 그것 정도를 구분하는 시점에서 보면 이해가 조금 더 빠를 것 같다.
Block Storage
데이터를 일정한 덩어리(블록)로 나눠 저장하는 방식
단적으로 말하자면, 그냥 물리적 장치 그 자체를 말한다.
현대의 모든 스토리지(임베디드 영역은 또 모르겠다)는 기본적으로 블록 단위로 구성이 되어 있다.
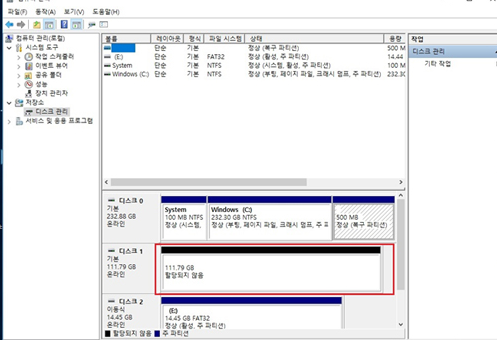
디스크 파티셔닝이니 뭐니 할 때 나눌 때 이 형태의 스토리지를 보게 된다.
데이터를 일정한 크기의 덩어리로 나누어 저장하는 방식
블록은 파일보다도 작은 단위이다.
단적으로 보자면, a라는 글자는 아스키코드로 치면 97을 뜻하고 이진수로 컴퓨터에 저장이 될 것이다.
그때 그 이진수는 조각조각 블록의 단위로 나뉘어 저장이 된다는 것.
이 블록들을 합쳐 우리가 볼 수 있는 데이터로 만들어내는 것이다.
그래서 블록은 그냥 물리적으로 저장된 단위 자체를 말하는 것과 같다고 본다.
프로토콜이나 어떤 형식에 딱히 얽매이는 방식이라기보다 가장 순수한 형태의 저장 형태라고 보면 되겠다.
다양한 접근 경로로 신속한 검색이 가능하며, OS에 종속적이지도 않다.
자유롭기에 대규모 DB 운영에서 유리하다.
위에서 본 SAN이 이러한 방식을 사용한다.
다만 이 블록을 읽기 위한 메타데이터나 방식에 대한 일체의 설정을 사용자가 관리해야 하니 운영 비용이 증가한다.
4.RESOURCE/KNOWLEDGE/AWS/AWS로 치면 Amazon EBS가 여기에 해당한다.
File Storage
블록 방식에서 한 단계 추상화된 방식이라 보면 되겠다.
말 그대로 파일시스템, 계층 구조 단위로 스토리지를 사용하는 방식.
OS 위로 소프트웨어를 다루는 우리 입장에서는 사실 가장 익숙하다.
USB 같은 것을 꽂았을 때 나오는 디렉토리, 그게 파일 스토리지 방식이다.
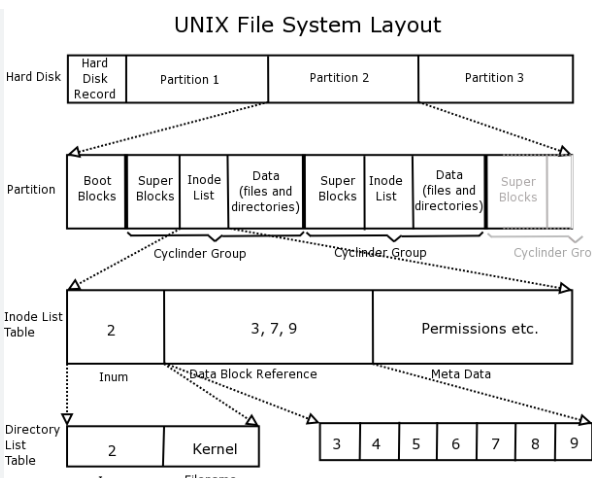
위의 블록스토리지와 비교하자면, 맨 윗층 그대로 사용하는 게 블록 스토리지.
그리고 inode나 각종 메타 데이터들로 블록들을 구조화시켜 사용하는 것이 파일 스토리지되시겠다.
블록 위에 이 파일시스템을 어떻게 구성하는가에 따라 세부적인 종류가 나뉜다.
리눅스에서는 대체로 ext4, 윈도우에서는 ntfs를 사용한다.
이것에 대해서 나중에 깊게 정리하는 시간을 가지면 좋을 것 같다.
위의 NAS는 이 방식으로 서버와 연결된다.
4.RESOURCE/KNOWLEDGE/AWS/AWS에서는 Amazon Elastic File System가 이것에 해당한다.
친숙하고 견고한 방식이라 흔히 애용되지만, 데이터가 많아지면 속도가 느려진다.
Object Storage
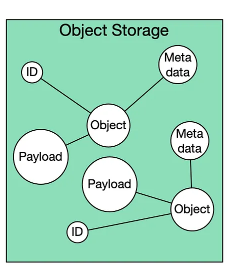
객체 방식으로 한 단계 더 추상화시킨 방식...
이라고 말은 했지만, 사실 파일시스템과 별개의 무관한 저장 방식을 가지고 구현된 것으로 알고 있다.

데이터를 오브젝트라는 단위로 관리한다.
파일처럼 뭔가 또 새로운 단위 개념인데, 그 자체로 메타데이터와 id 등을 가지고 있게 설계됐다.
파일시스템에서의 메타데이터는 크기가 제한적이지만 이 녀석은 자유롭게 메타데이터 구성이 가능하다.
그래서 나는 이걸 언어에서의 오브젝트라고 이해해도 된다고 생각하는 편인데, 일반 변수와 클래스의 차이 중 하나는 클래스는 크기가 자유롭다는 것이다.
이 놈도 비슷하게 한 데이터의 크기가 자유롭고 추가할 수 있는 메타데이터도 무궁무진하다.
오직 고유한 것은 키.
키를 통해서 해당 오브젝트를 접근할 수 있다.
그래서 hash를 생각하면 또 편하다.
평면 구조라는 특징도 가지고 있다.
대표적으로 Amazon S3가 있다.
로컬에서 사용하는 minIO라는 것도 있다.
대신 오브젝트는 수정이 불가능해서 언제나 덮어쓰는 방식으로 만들어야 한다.
Ceph는 내부적으로 이 스토리지 방식으로 구현이 되어 있다.
성능 지표
데이터와 관련된 성능으로는 크게 2가지가 중요하다고 볼 수 있다.
- 용량
- 입출력 속도
용량에 대해서는 직관적으로 성능을 파악하는 것이 쉽다.
100기가 짜리 usb라고 한다면, 말 그대로 100기가까지는 데이터를 넣을 수 있다는 뜻이 될 것이다.
입출력에 대해서 사용되는 성능 지표가 좀 골 때린다.
아래 개념들을 살펴보자.
IOPS
Input/Output Operations Per Second
1초당 처리할 수 있는 입출력 횟수.
말만 들으면 간단하지만, 사실 입력만 빠른 저장 장치도 있고 데이터를 순차적으로, 혹은 랜덤하게 접근하는가에 따라 다양한 속도의 차이가 발생한다.
1 / (평균 접근 시간 + 데이터 전송 시간)
그래서 보통 이러한 평균 공식으로 계산된다고 한다.
원하는 위치의 데이터로 접근하는데 걸리는 시간과, 그 데이터를 원하는 위치로 전송하는데 걸리는 시간.
얼핏 보면 입출력과 직접적으로 연관이 없는 값으로 계산하는 것처럼 보이기도 한다.
HDD의 경우에는 자기 디스크의 분당 회전수(RPM)이 IOPS를 결정짓는다.
그래서 제한이 결국 있기 마련이고 최대 210 정도가 나온다고 한다.
다음으로 SSD는 플래시 메모리, 즉 전자를 저장하는 칩을 사용하기에 5만 iops도 나온다.
이걸 정확하게 측정하는 방법이 어떻게 되는지는 추가 공부가 필요할 듯.
그럼 IOPS의 크기가 실제 얼마나 영향을 끼치는지는 어떻게 계산할까?
초당 데이터 전송량 = IOPS * 블럭크기(단위 데이터 용량)
이런 공식이 있다.
가령 150K의 IOPS, 단위 블럭이 4K라고 한다면 데이터는 초당 600MB가 전송되는 것이다.
이 경우 2기가 동영상을 꺼내는데 걸리는 시간이 3초 남짓이라 보면 될 거이다.
- 보통 데이터베이스의 블록 단위는 8K, 16K, 32K, 64K
- 보통 파일시스템의 블록 단위는 1Kib, 2Kib, 4Kib(이게 기본)

4.RESOURCE/KNOWLEDGE/AWS/AWS의 Amazon EBS에서 2024년 기준 표준으로 사용되는 SSD 사양.
최대 IOPS는 16K이다.

친절하게 블록 크기는 16K를 기준으로 한다고 알려주고 있다.
그래서 최대 처리량은 16 * 16해서 대충 초당 250 메가를 전송할 수 있게 된다.
엥? 근데 나온 사진에 나온 처리량은 초당 1000메가를 할 수 있다고 한다.
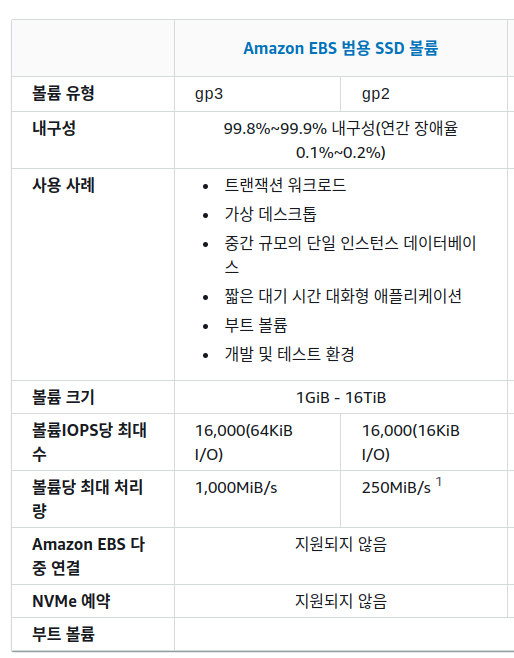
응 고것은 문서 관리 제대로 안 돼서 일어난 낚시였습니다..
사용자 가이드 문서에 들어가서 보면 블록 수에 대해서 또 제대로 나와 있다.
보다보면 aws는 사람들 헷갈리게 하려고 일부러 이러는 것 같다.
Throughput
단위 시간 당 데이터 처리량.
스토리지 쪽에서는 위의 IOPS를 통해 계산되는 데이터 전송량과 거의 동치된다.
단위도 초당 몇 바이트(b/s, Mb/s)와 같은 식으로 직관적이다.
그렇다면 결국 IOPS와 비례하는 값이니까 IOPS는 딱히 의미 없는 것이 아닐까?
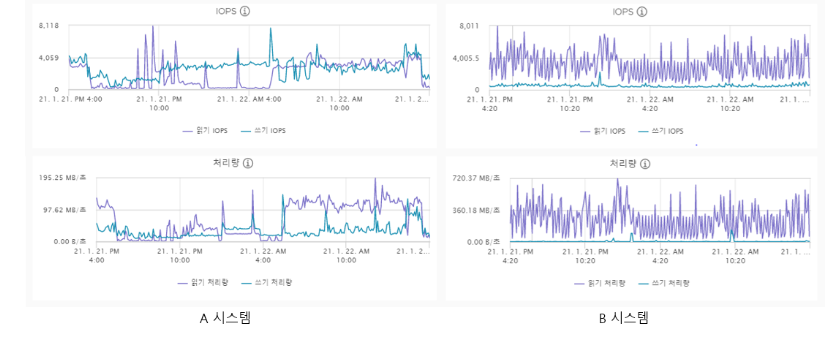
그러나 아닌 케이스가 존재한다.
블록 크기라는 게 결국 처리량에 또 영향을 미치기 때문에 단순하게 그렇게만 생각할 수는 없다.
요컨대 작은 데이터를 많이 보내는 작업을 할 때 처리량이 높은 스토리지라고 해도 IOPS가 낮다면 크게 효과를 발휘할 수 없다는 말이다.
특히 데이터베이스에서는 처리량보다는 IOPS가 중요하다고 한다.
Bandwidth
대역폭.
단위 시간 내 얼마나 많은 데이터를 전송할 수 있는지.
처리량과 말이 비슷해 보인다.
물을 흘려보낼 때 많이 흘려보내는 방법에는 두 가지가 있다.
- 물 속도를 빠르게 하기
- 몰을 흘려보내는 통의 크기를 넓히기
이중 대역폭은 후자에 속한다.
그래서 한번에 전송할 수 있는 패킷 수라고 정의하는 게 조금 더 바람직할 것 같다.
근데 이건 사실 네트워크 스토리지 제품의 성능을 말할 때나 이야기할 지표이고, 스토리지 자체랑은 크게 상관 없다고 생각한다..
그럼에도 네트워크 환경을 통해 연결되는 스토리지도 많기 때문에 무시할 수는 없는 개념이기도 하다.
어떤 글에서는 스토리지 성능 지표를 이야기할 때 표현을 이걸로 바꾸라는 말도 있긴 하다.
아무튼 처리량과 대역폭은 네트워크 지표로 세분화되는 개념이고 스토리지 쪽에서는 크게 차이없다라고 생각해도 무방하지 않을까 싶다.
Latency
지연 시간
어떤 요청이 응답이 돌아올 때까지 걸리는 시간.
단위는 ms 정도 된다고 한다.
얼핏 들으면 그냥 처리량이랑 뭐가 다른가 싶기도 하다.
레이턴시가 1ms면 1000b/s인 것은 아닐까?
스토리지에서의 지연시간은 한 IO 요청을 의미하니 어쩌면 1000 IOPS?
그런데 이게 또 그렇지는 않다고 한다.
스토리지가 한번에 처리할 수 있는 요청의 양은 하나가 아니니까 그런 것이다.
그런 의미에서 위에서 말한 대역폭의 개념이 개입된다고도 볼 수 있을 것이다.
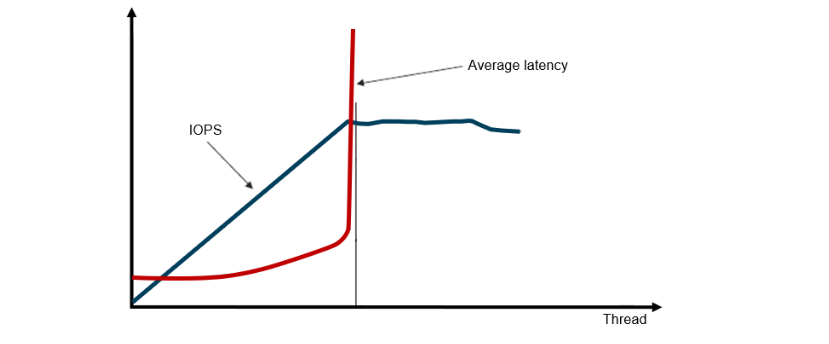
이런 상황이 나오는 게 그래서 그렇다.
요청을 감당할 수 있는 만큼을 넘어서 대기 큐가 차기 시작하면 그때부터는 지연시간이 크게 발생하게 된다.