T-파드가 failed 뜨는 상황이란
개요
파드의 생애주기를 정리하다가, 파드의 failed 상태와 내부 컨테이너의 상태의 정확한 연관을 파악하고 싶었다.
문서에 따르면 파드는 내부 컨테이너가 최소한 하나가 재시작 불가능일 때 failed가 된다고 한다.
또한 노드 연결이 끊겼을 때도 마찬가지로 failed가 뜬다고 했다.
내 생각으로는 노드 불량으로 인한 failed는 컨트롤러가 다시 관리를 진행해서 해당 파드를 다른 노드로 옮기도록 하지 않을까 한다.
아무리 failed라고 해도 유도리가 없잖냐...
세팅
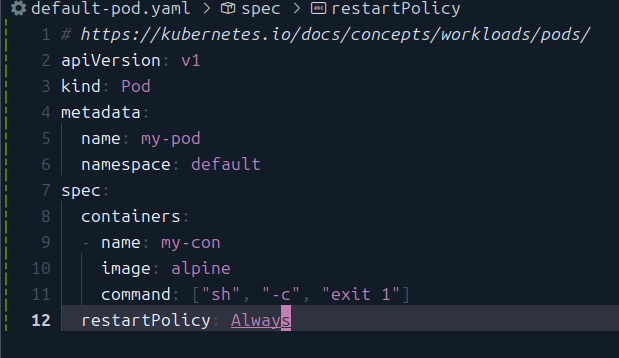
기본적인 상황은 이렇게 만들었다.
즉, 실행이 되자마자 실패가 뜨게 된다.
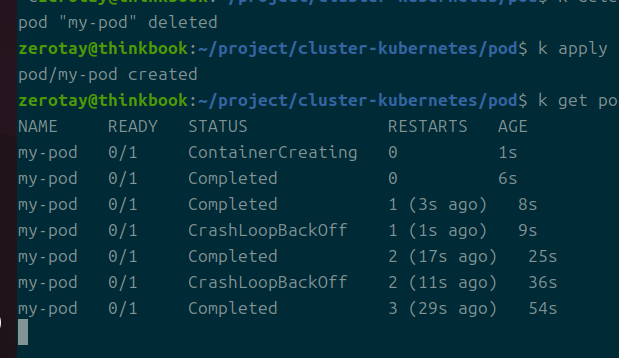
참고로 command 부분을 넣지 않으면 컨테이너의 실행은 completed되고, 이를 재시작하면서 CrashLoopBackOff가 발생한다.
이걸 막고 싶으면 당연히 무한 루프를 도는 프로세스를 만들면 된다.
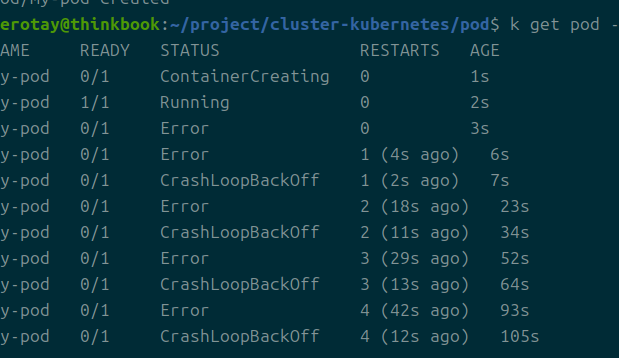
아무튼 이렇게 에러가 발생하고, 이를 재시작한다.
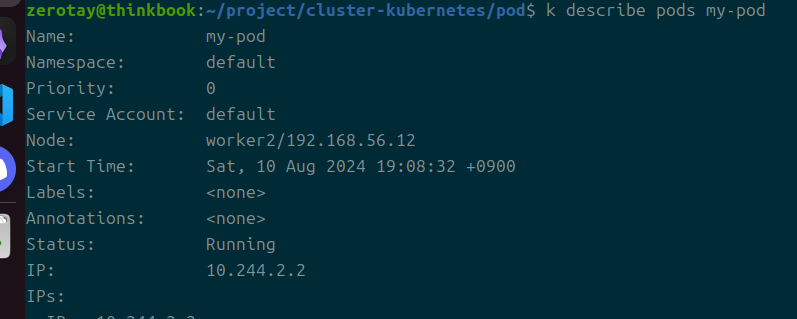
이렇게 에러가 뜨더라도 파드 자체의 상태는 계속 Running인 것이 확인된다.
재시작 정책 never로 바꾸기
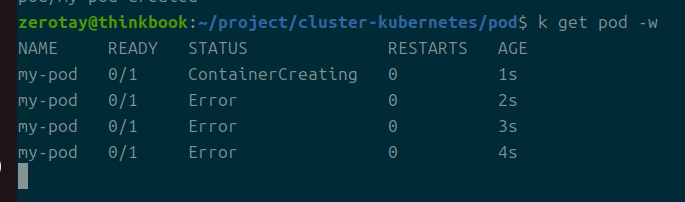
재시작을 못하게 막은 상황.
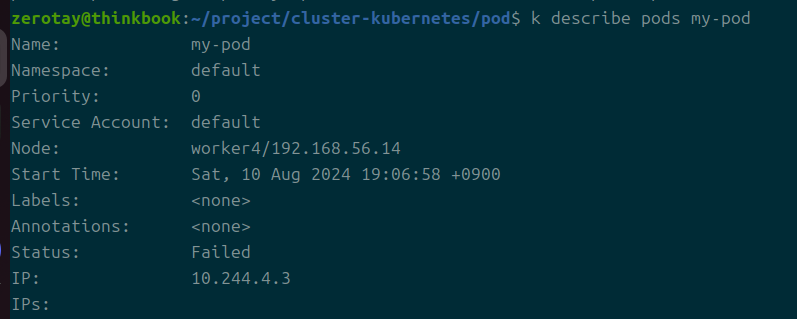
성공적으로? Failed가 뜨는 것이 확인된다.
즉, 재시작 정책이 never일 때 파드는 failed가 된다.
노드 연결 끊어버리기
처음에는 이걸 어떻게 세팅하나 막막했는데, 생각해보니 그냥 노드 하나를 꺼버리면 되는 부분이다.
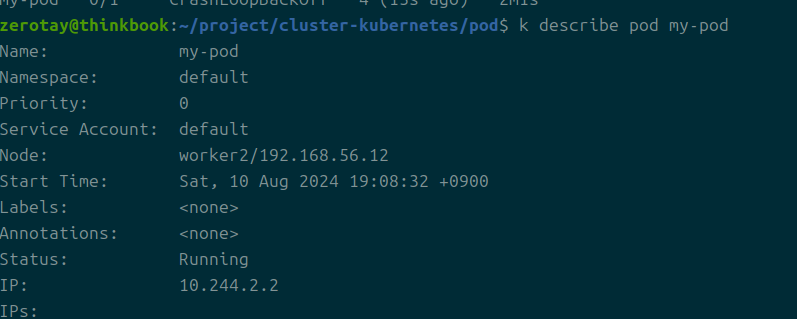
2번 워커 노드에 현재 파드가 바인딩되었다.
그래서 꺼버렸다.
까먹고 노드 상태를 바로 반영하도록 하지 않았는데, 기본적으로 쿠버네티스는 노드의 연결이 끊겨도 5분정도는 기다리면서 확인을 진행한다고 한다.
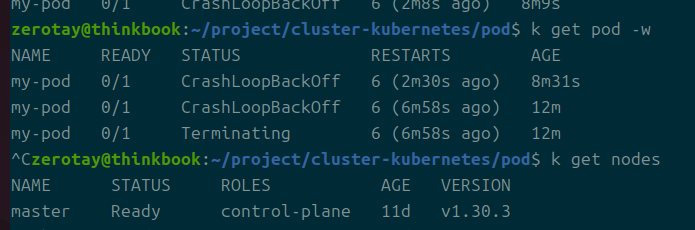
시간을 기다리다보니 갑자기 terminating 상태가 지속되는 것이 확인됐다.
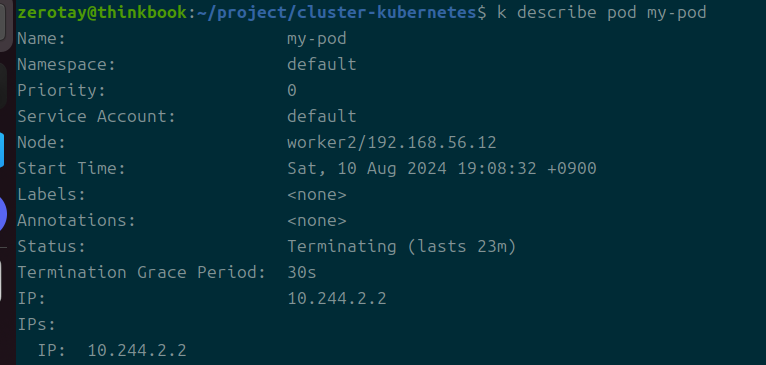
언제 한번이라도 failed가 뜨는가 보려고 했는데 바로 terminating 상태가 되어버려서 확인이 불가하다.
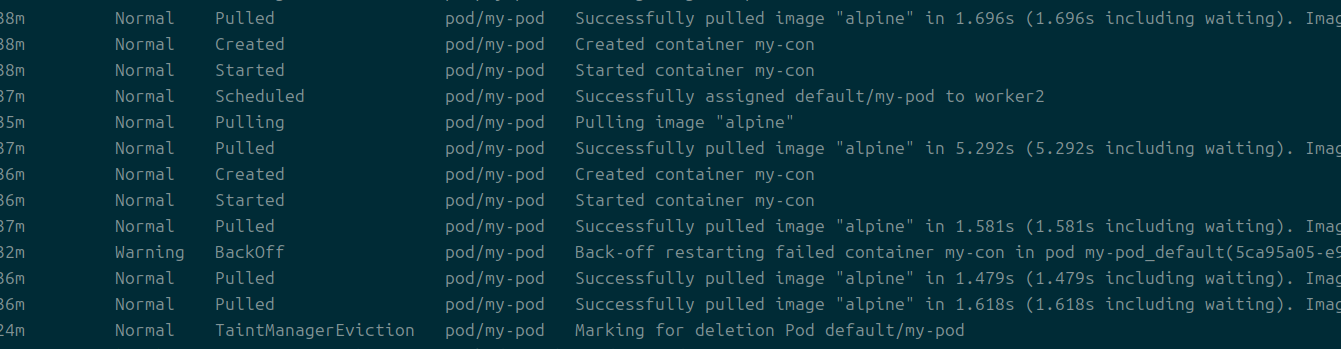
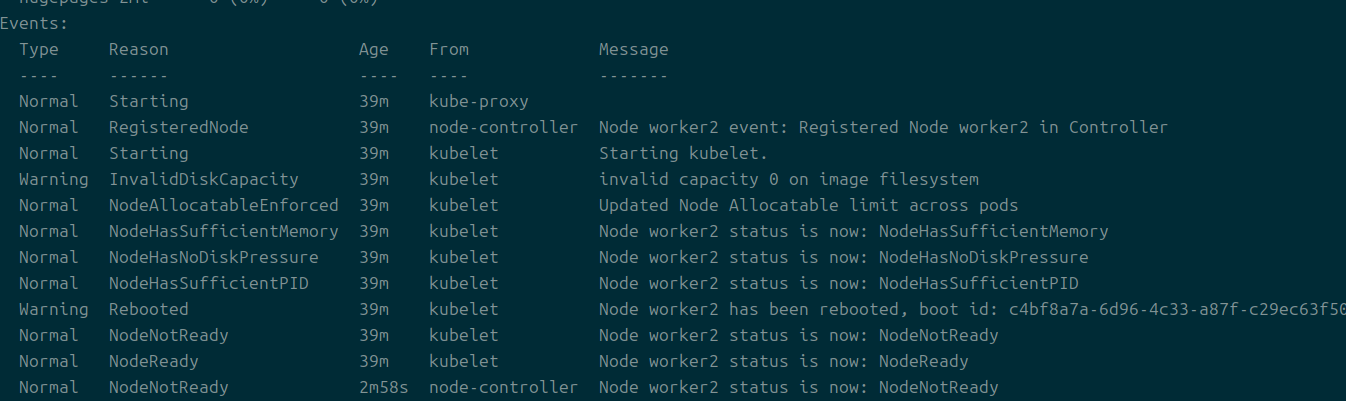
추가적으로 kubectl get events --field-selector involvedObject.name=my-pod라는 방식으로 이벤트를 확인해봤다.
marking for deletion pod라고 뜨는 것이 확인된다.
이 상황이 되니 문제가 있었던 것이 delete로도 삭제가 진행되지 않았다는 것.
my-pod는 더 이상 건드릴 수 없는 영역이 된 것마냥 계속 머물러 있다.

젠장 ㅋㅋ
아마 이건 노드 자체를 추적 못하도록 없애야 해결이 되지 않을까 싶다.
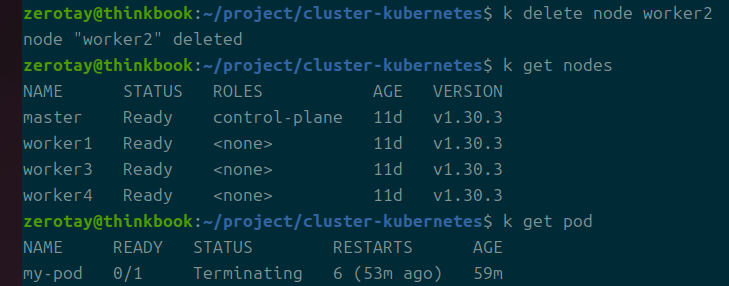
아니, 그래도 이 좀비 같은 놈은 남아있다.
대충 내린 결론은, 노드가 없어짐에 따라 TainerManagerEviction을 통해 해당 노드의 자원들을 회수하는 작업을 진행하려하지만 이 과정이 제대로 이뤄지지 못해 파드가 지워지지 않는 것 같다.
그리고 이것은 아직 쿠버네티스의 개발진이 대응하지 못한 이슈가 아닌가 한다.
비슷한 에러를 접하는 글들을 몇 개 봤는데 해결이 되지 않은 것으로 보인다.
결론
파드의 Failed는 다음의 상황에서 발생한다.
- 재시작 정책이 never일 때 컨테이너 실행 실패
- T-초기화 컨테이너는 재시작되는가에서 보면 알 수 있듯 당연히 init 컨테이너의 실패에도 failed가 뜬다.
- 노드의 연결이 끊길 때, 해당 노드에 위치한 파드들은 failed
- 이건 제대로 확인되지 않음
- failed가 뜨도록 유도하고 싶었으나 명확하게 확인하는 것은 힘들었다.
- 노드가 비정상적으로 끊겼을 때 자원이 적절하게 회수되지 않고 그냥 종료되는 상태에 머물러 있는데 이것은 버그가 아닌가 한다.
- 만약 이 버그가 해결이 된다면, 자원은 적절하게 회수될 것이다.
- 확실하지는 않지만, 그렇다면 그 자원이 회수된 경우 역시 다른 노드로 스케줄링되지 않을까 한다.