Kim Wustkamp
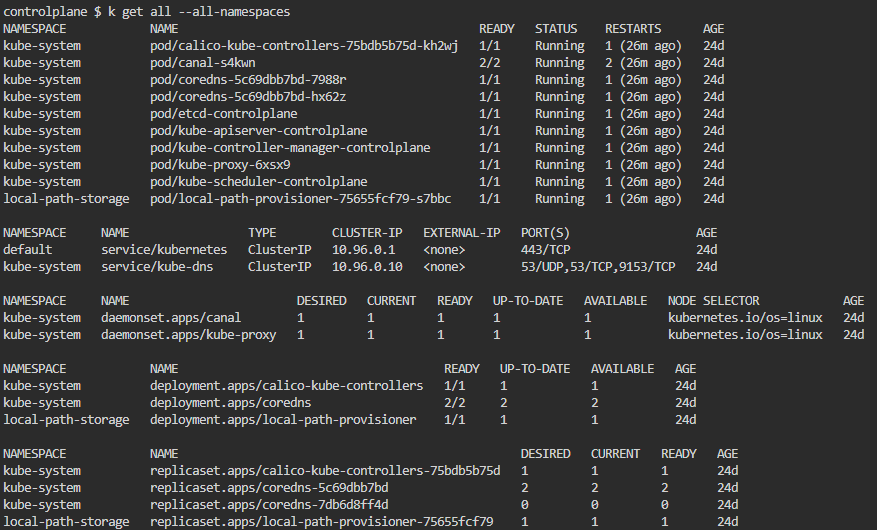
개요
Apiserver Crash
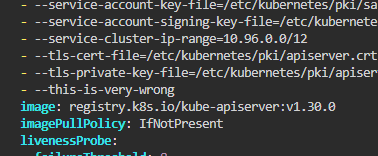
Configure wrong arguement
kube-apiserver가 동작하지 않는 상황을 만들고 해결해보자.
--this-is-very-wrong 인자를 붙여서 설정해라.
이후 해결하라.
Misconfigure ETCD connection
이번에는 api서버 파일에 etcd 설정을 잘못 넣어보라.
--etcd-servers=this-is-very-wrong 인자를 붙여서 설정해라.
var에 들어가지 말고 로그를 확인하고 원상복구해라.

말 그대로 해본다.
이번에는 api 서버 자체가 맛이 가는 것은 아니지만 Etcd와 연결이 되지 않는 상황
이렇게 고장내고, api server가 다시 뜰 때까지 기다린다.
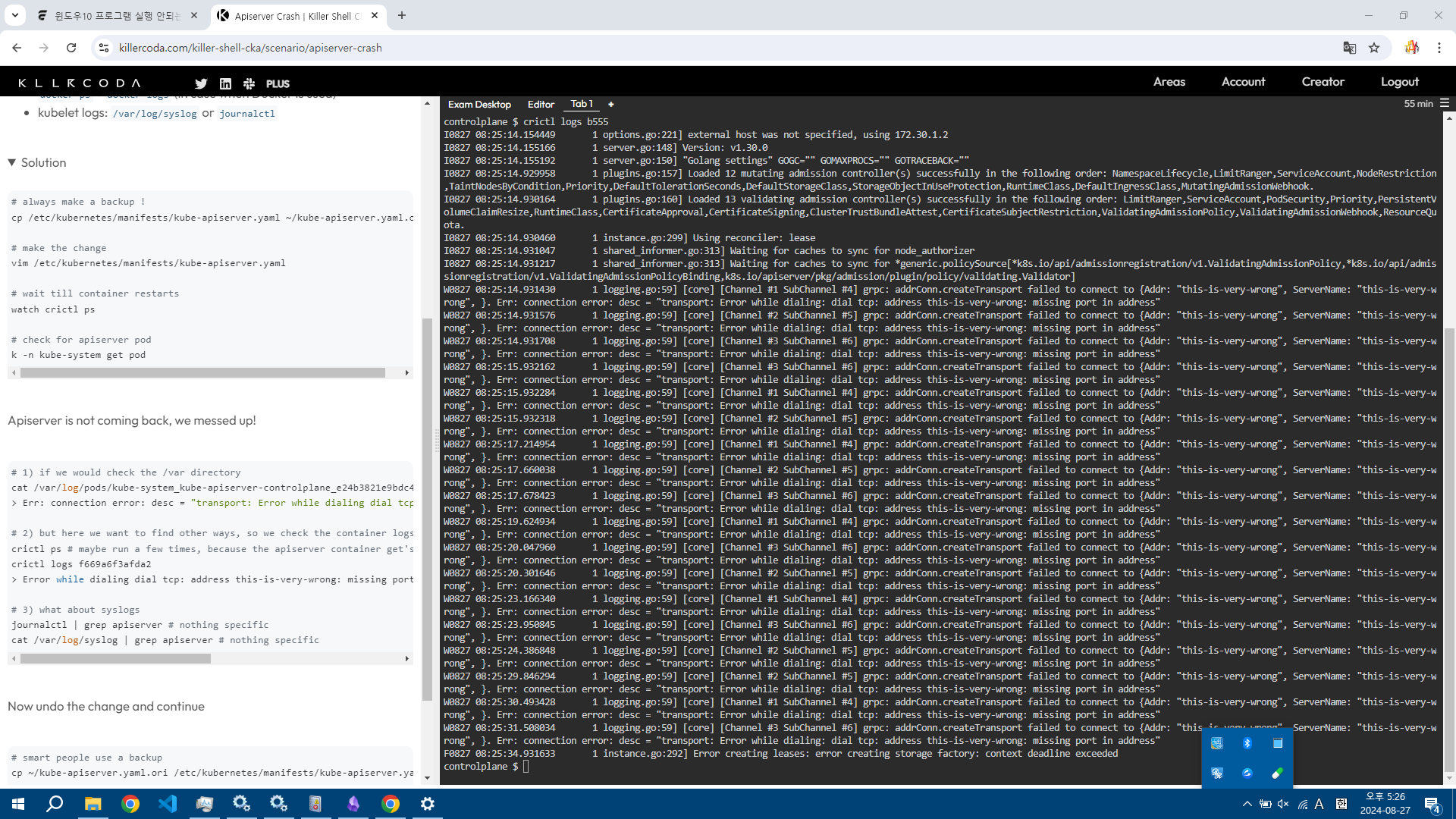
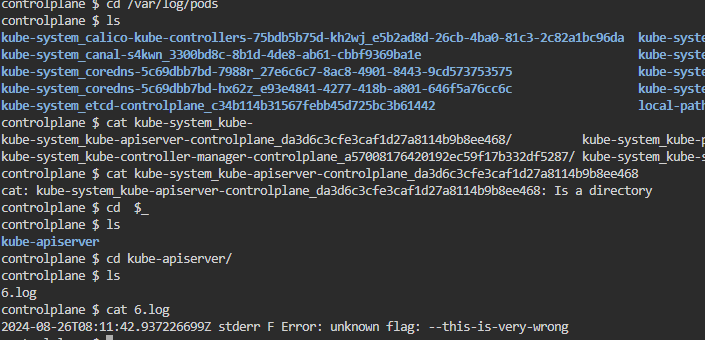
이후에 crictl logs {api server id}를 확인한다.
Invalid Apiserver Manifest YAML
이상한 양식으로 api서버 넣어라.
그 다음 다시 해결해라
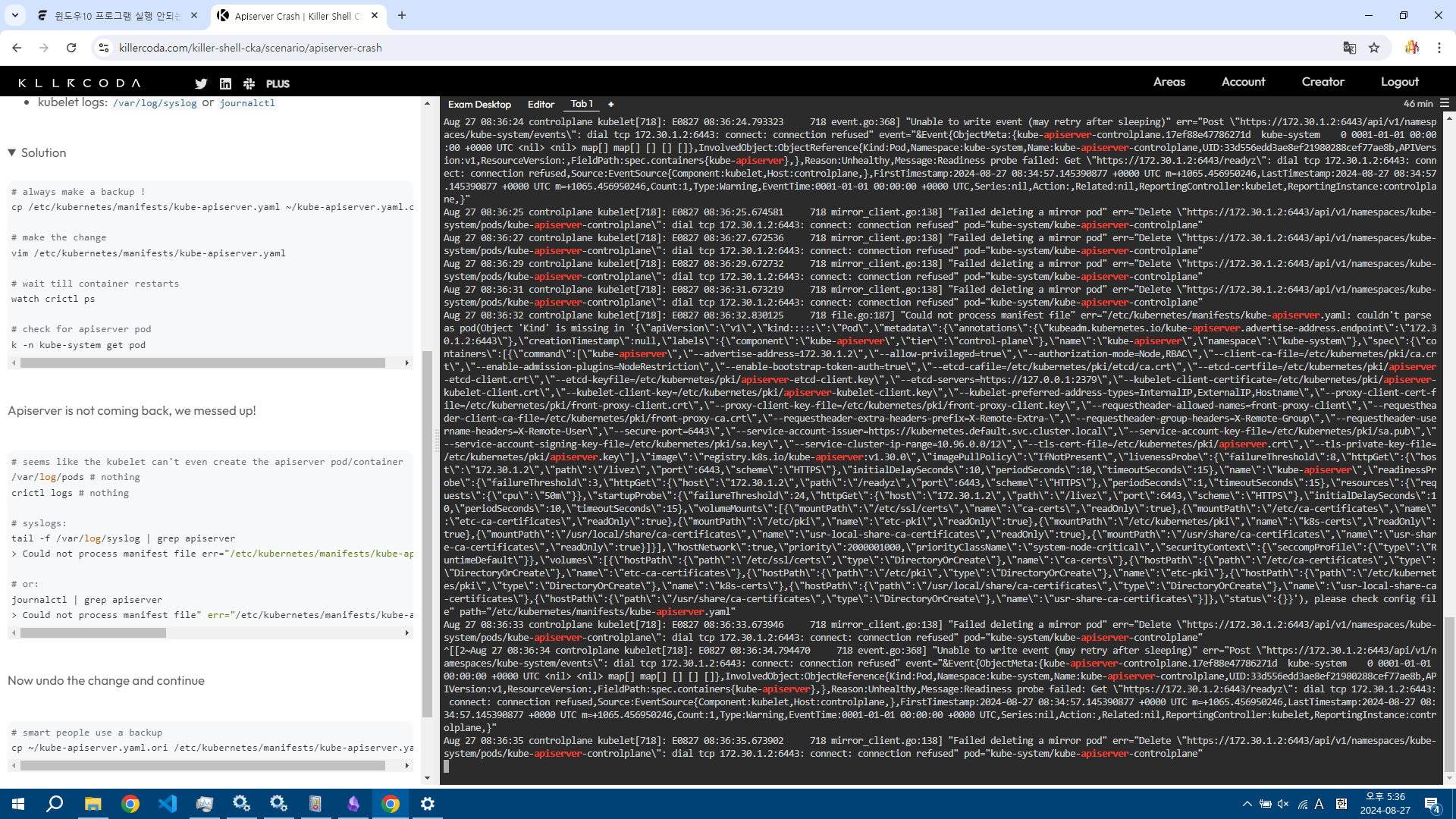
tail -f /var/log/syslog | grep apiserver를 한 결과이다.
apiserver 파일을 파싱할 수 없다고 나온 게 가장 긴 로그.
관련한 에러도 마구 뜬다.
결론
컨트롤 플레인에서 에러가 발생한다면 이를 어떻게 대처할 수 있는가?
당연히 로그를 확인하고 대처해야만 한다.
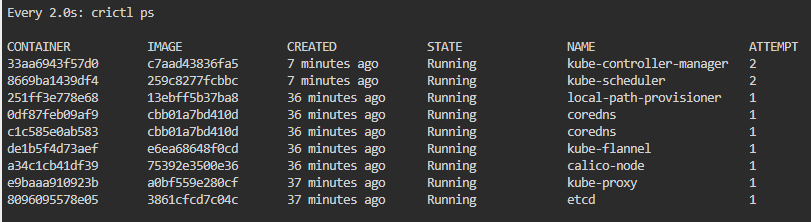
이때 crictl을 통해서 어떤 컨테이너가 문제 있는지 파악하고, 파드#정적 파드를 건드려서 해결을 할 수 있는 경우가 많다.
/var/log/containers에 들어가서 확인해봐도 되고, journalctl을 쓰는 것도 방법이다.
Apiserver Misconfigured
이제부터 실전
3가지 위치에서 api 서버가 문제가 있으니 이를 해결하라.

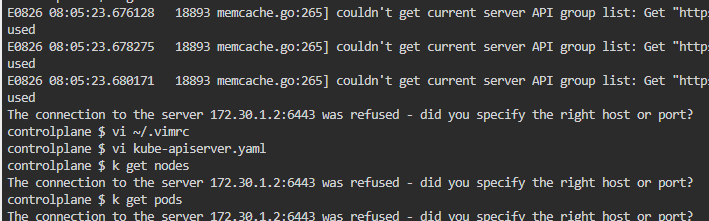
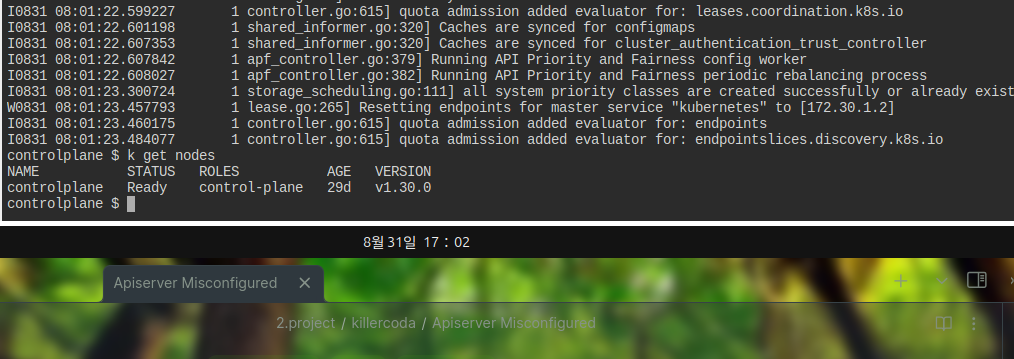
일단 api서버가 떠있지 않은 것인지 kubectl 자체가 먹히지 않는다.

보다시피 api 서버가 안 띄워지고 있다.
처음부터 띄워지지 않았기에 컨테이너나 파드 로그를 통해 확인도 이뤄지지 않는다.

다만 journalctl을 보면 kubelet에서 에러를 띄워주는 것이 확인된다.
일단 api서버의 양식이 제대로 파싱되지 않고 있다.
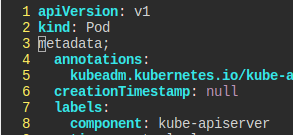
이 부분을 고쳐주었다.

이제는 컨테이너가 살았다 죽었다 하기에 로그를 볼 수 있게 되는데, 모르는 플래그가 있다고 한다.

이 친구의 이름은 authorization-mode이다.
모르면 공식 문서에서 플래그를 찾아보면 된다.

이제는 컨테이너가 실행은 되는 모습이다.

하지만 계속 재시작을 반복하는데, 23000 포트로 가는 부분이 거절된다고 나온다.

etcd로 연결하는 부분이다.

etcd는 해당 yml 파일을 보면 2379 포트를 사용한다.

이것까지 해결하니 돌아가기 시작한다.
딱히 이상은 없는 것 같다.
Kube Controller Manager Misconfigured
kube-controller-manager에 문제가 생겼으니 해결해보라.
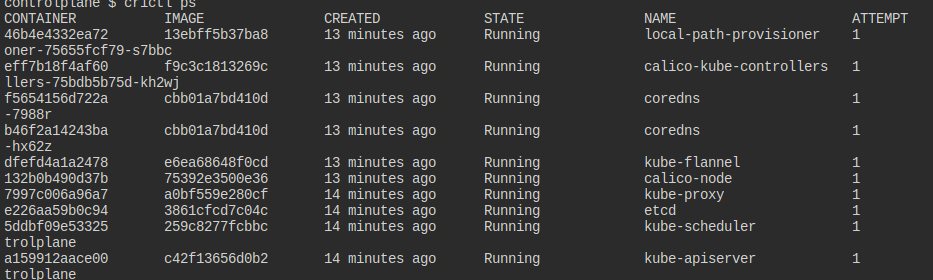
아예 컨트롤러 매니저가 뜨지 않고 있다.

그냥 쿠베 로그로 확인해보니 이러한 이슈가 있다.
공식 문서를 참고해봤으나, 관련한 flag는 그냥 없어서 지워버렸다.
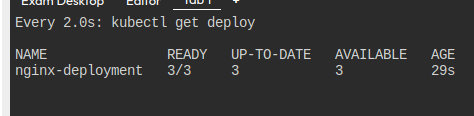
컨트롤러가 잘 작동하여 디플로이먼트도 잘 먹는다.
Kubelet Misconfigured
node01의 kubelet이 망가진 모양이니 고쳐봐라.
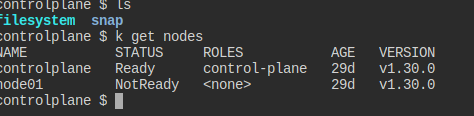
과연 한 놈이 문제가 있다.

ssh로 넘어와도 되는 거였다;;
아무튼 넘어와서 확인해보면 확실히 kubelet이 문제가 있다.

journalctl로 확인해보니 이상한 플래그가 들어가있다.
kubelet은 컨테이너 런타임이기에 컨테이너의 문제를 해결하는 방법으로 해결할 수 없다.

서비스의 상태를 보고 찾아들어가서 확인해본다.
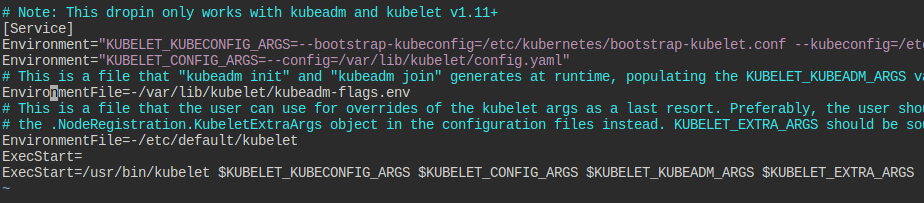
이번에는 정적파드로 해결할 수 없다.
서비스 사양을 찾아보고, 관련한 플래그가 담긴 곳을 찾아본다.

나와 있는 각 환경 파일을 찾아다니다보니, 이 놈에 improve-speed라는 놈이 있다.
이놈을 지우면, auto restart가 걸려 있어 서비스가 시작된다.
혹시 모르면 직접 재시작해도 좋다.
Application Misconfigured 1
application1 네임스페이스에 Deployment가 있다.
다른 거 쓰지 말고 얘만 사용해서 잘 돌아가게 만들어라.

있긴 한데, 이렇게 문제가 발생한다.
컨테이너 생성부터 안 된다는 것.

디플과 하위 파드의 이벤트를 보니 ConfigMap에서 문제가 발생했다.

실제 놈은 이렇게 생겼으니까, 이걸 활용해야 한다.

configmap의 이름은 name쪽이다.

Application Misconfigured 2
다른 클러스터의 양식을 그대로 가져와서 Deployment를 배포해보는데 제대로 동작하지 않는다.
어느 클러스터에서든 동작하도록 만들어보자.

전부 pending에 걸려있다.

로그를 뜯어보니 단서가 나온다.
staging-node1 노드에서만 실행되도록 설정됐다.
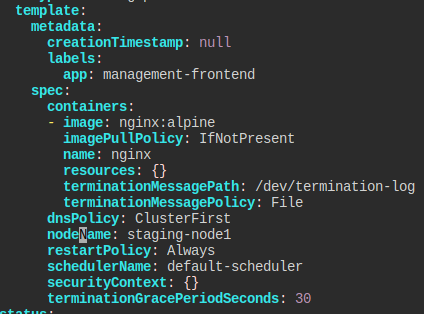
특정 노드에 스케줄되도록 지정이 돼있다.
이러면 범용적으로 돌아갈 수는 없다.
그래서 그냥 단순히 노드를 특정하는 부분을 주석 처리했다.
Application Multi Container Issue
Gather logs
management 네임스페이스에 멀티 컨테이너 Deployment이 있다.
해당 디플의 모든 컨테이너의 로그를 /root/logs.log로 모아라.
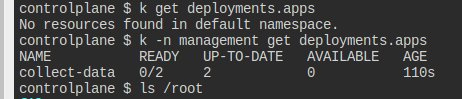
로그를 모아두기만 하면 된다.
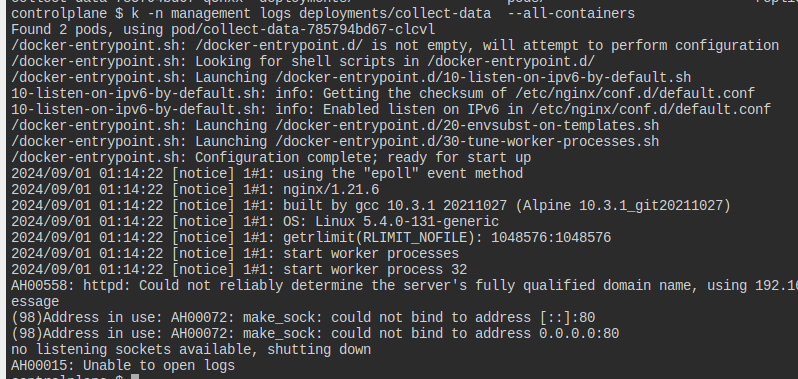
--all-containers옵션을 통해 한꺼번에 모든 컨테이너의 값을 가져올 수 있다.
nginx와 httpd가 같은 포트를 열어서 httpd가 꺼진 상황인 듯하다.

과연, 하나만 크룹백이 터지는 중이다.
Fix the Deployment
방금 두 컨테이너가 80 포트를 쓰는 게 문제였으니, 하나는 지워라.
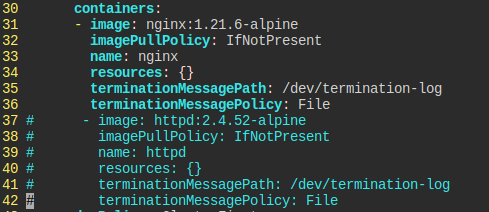
한 쪽은 주석처리해버렸다.
edit으로 수정해버렸다.
ConfigMap Access in Pods
Create ConfigMaps
두 개의 컨피그맵을 만들어야 한다.
tree=trauerweide이란 내용의 trauerweide라는 ConfigMap을 만들어라.
cm.yaml 파일을 이용해서도 하나 만들어봐라.
문제 잘못 읽고 계속 실수로 cm을 만들면서 이걸 cm.yaml에 덮어쓰는데 그러지 말자..
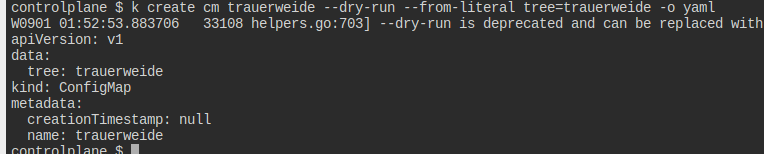
help를 통해 만드는 방식을 파악하고 쳐주었다.
제대로 만들어지는 듯하니 이대로 진행
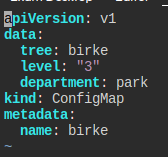
cm.yaml 파일은 이렇게 생겼다.
Access ConfigMaps in Pod
nginx:alpine 이미지로 pod1을 만들어라.
trauerweide를 환경변수 TREE1란 이름으로 받아라.
birke의 configmap의 키는 전부 /etc/birke/*의 볼륨으로 받아라.
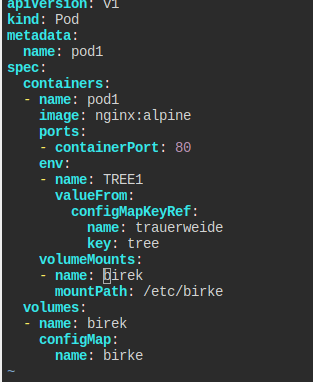
공식 문서를 참고할 것도 없이 그냥 create -h 쳐서 찾아본다.
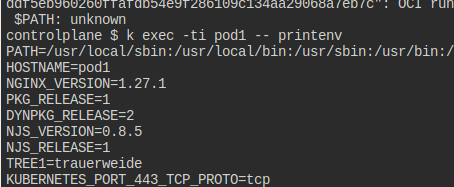
트리는 잘 들어갔다.
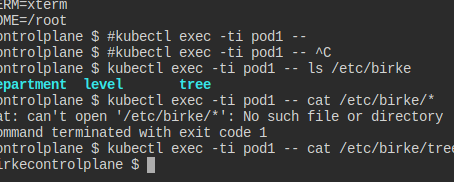
파일로도 원하는대로 들어간 것 같다.
참고
컨피그맵 내용을 잘못 만들어서, 해당 내용을 수정했는데 이게 파드에 바로 반영이 안 됐다.
찾아보니 환경변수로 넣은 경우에는 무조건 파드를 재시작해야 한다고 한다.
볼륨으로 넣은 경우에는 자동으로 추적해주기는 한다는 듯.
Ingress Create
Create Services for existing Deployments
world 네임스페이스 안에 Ingress로 접근돼야 하는 두 Deployment가 있다.
디플과 같은 이름이고 포트가 80번이 열린 ClusterIP Service를 만들어라.

각각의 서비스를 만들어줘야 한다.
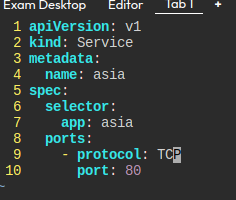
이런 식으로 만들어봤으나, 엔드포인트가 잡히지 않는다.
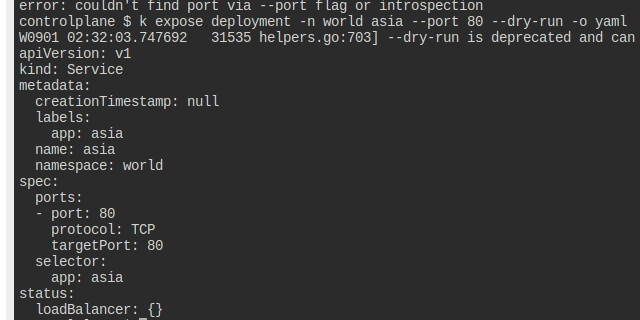
expose를 통해 뭐가 다른지 살펴본다.
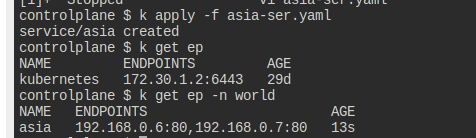
이제 보니까 네임스페이스를 잘못 두고 있었다.

정상적이라면, 이렇게 curl 요청이 잘 먹힌다.
Create Ingress for existing Services
이미 Nginx Ingress Controller는 설치돼있다.
도메인 이름 world.universe.mine이라고 하는 world 인그레스를 만들어보자.
노드에 /etc/hosts에 해당 도메인이 등록되어 있어 정상적으로 이용 가능할 것이다.
30080포트로 europe, asia 각각의 경로 라우팅이 돼야 한다.

이미 인그레스 컨트롤러는 nginx라는 이름으로 있다.
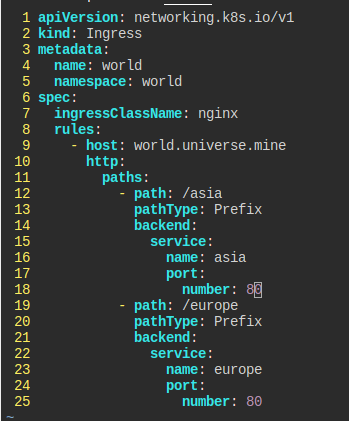
문제 이해를 잘 못해서 이렇게만 만들었다.
그런데 그냥 성공이 떠서, 풀이 내용을 정리해보려고 한다.

인그레스 클래스 이름을 확인한다.
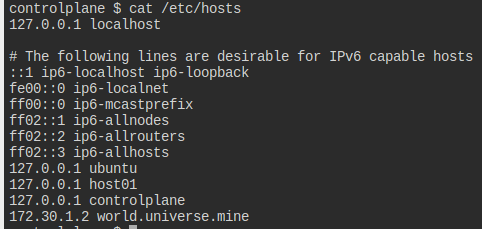
hosts 들먹이는 건, 그냥 도메인 이름이 어차피 로컬에 지정돼있어서 편하게 도메인 이름 작성하라는 거네..
인그레스는 80,443 포트밖에 지원되지 않는다고 하는데, 노드 번호 30080은 무슨 말인가가 궁금했다.
이건 인그레스를 더 자세히 공부해야 이해할 수 있을 듯.
컨트롤러가 정확하게 동작하는 방식은 무엇인가?
는 조금 공부해보니 알겠다.
기본적으로 노드포트 종류로 서비스가 열리고, 이게 external ip가 부여된다.
이 친구는 내부에 nginx 파드랑 연결된다.
이게 인그레스 컨트롤러가 하는 일.
여기에 관리자가 인그레스를 만들면 nginx 설정 파일에 설정을 가하는 것이다.
그리고 그 방식은,, 내가 여태 많이 해봤던 그냥 서버 블록 넣어주는 작업일 것으로 생각된다.
그러니 30080은 그냥 노드 포트가 무엇인지를 나타낸다.
여기로 들어오는 트래픽이 80으로 연결된다.
NetworkPolicy Namespace Selector
space1, space2 네임스페이스가 있다.
space1의 파드들만 space2로 갈 수 있도록 하는 np란 이름의 NetworkPolicy를 만들고 싶다.
대신 space1은 인커밍은 자유롭고, space2는 아웃고잉이 자유롭다.
그럼에도 53포트로 tcp, udp dns 아웃고잉 트래픽은 자유롭게 처리할 수 있게 하라.

각 네임스페이스에 적절한 라벨이랄 게 없으므로, 이름을 라벨로 걸어야겠다.
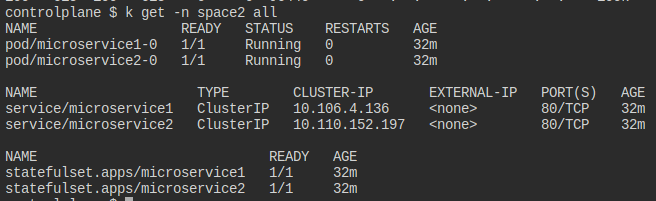
space2에는 StatefulSet으로 만들어진 파드와 이를 연결하는 Service가 존재한다.
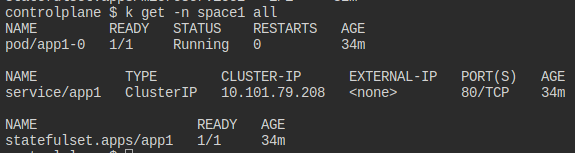
space1에도 마찬가지이다.
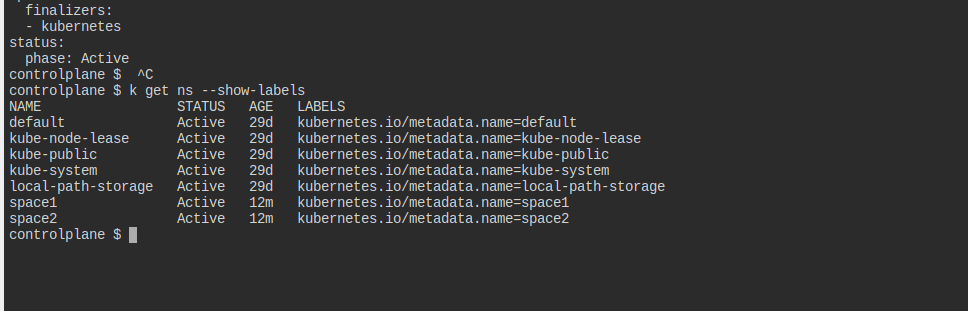
네폴의 기준을 네임스페이스로 걸기 위해 각 네스의 라벨을 알아야 한다.
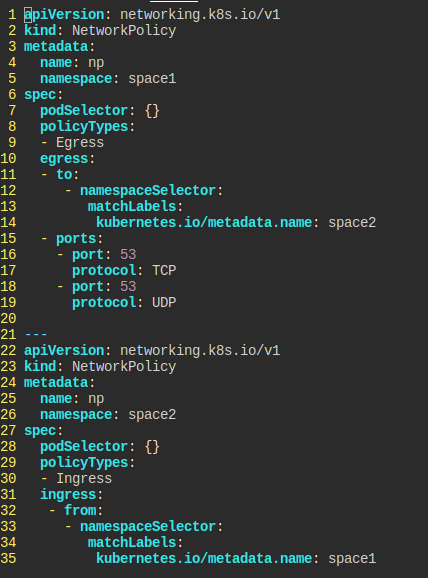
들어오는 트래픽에서는 굳이 포트를 지정하지는 않는다.
이때 주의할 것은, to와 ports는 리스트로 되어 있어야 한다는 것이다.
ports 앞에 -가 없으면, 스페이스2로 나가는 dns 트래픽만 허용된다는 뜻이 된다.

확인
k -n space1 exec app1-0 -- curl -m 1 microservice1.space2.svc.cluster.local
k -n space1 exec app1-0 -- curl -m 1 microservice2.space2.svc.cluster.local
k -n space1 exec app1-0 -- nslookup tester.default.svc.cluster.local
k -n kube-system exec -it validate-checker-pod -- curl -m 1 app1.space1.svc.cluster.local
이것들은 작동해야 한다.
space1에서 2로 가는 요청과, space1에서는 dns가 성공해야 한다.
대신 들어오는 건 자유롭게 받아칠 수 있게 validate으로 실험해본다.
# these should not work
k -n space1 exec app1-0 -- curl -m 1 tester.default.svc.cluster.local
k -n kube-system exec -it validate-checker-pod -- curl -m 1 microservice1.space2.svc.cluster.local
k -n kube-system exec -it validate-checker-pod -- curl -m 1 microservice2.space2.svc.cluster.local
k -n default run nginx --image=nginx:1.21.5-alpine --restart=Never -i --rm -- curl -m 1 microservice1.space2.svc.cluster.local
이것들은 작동해서는 안 된다.
space1에서는 space2가 아닌 다른 곳으로의 요청은 dns 제외하고는 실패여야 한다.
space2는 space1 말고는 요청을 받으면 안 된다.
NetworkPolicy Misconfigured
default 네임스페이스에 위치한 level=100x 라벨을 가진 파드들은 같은 라벨을 가진 level-1000,level-1001,level-1002에 있는 파드들과 상호작용할 수 있어야 한다.
np-100x NetworkPolicy를 알맞게 고쳐라.
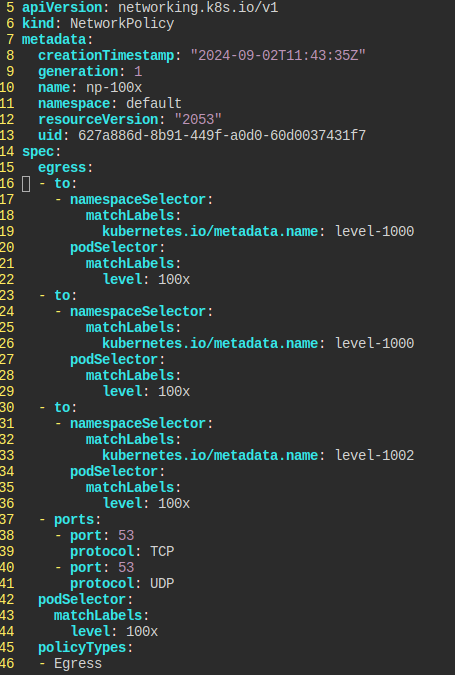
문제점은 그냥 단순히 1001 노드에 대해서 허용하는 egress 부분이 오타가 있는 것이었다.
포트를 명시하지 않으니 오히려 문제가 생겼다.
53 dns 요청을 명시한다는 것은 예외 처리를 의미하기라도 하나?
왜 명시하지 않으면 리졸빙이 안 되지?
명확하게 물어보자면, 80번 포트를 명시하지 않았음에도 curl 요청이 가능한 이유가 무엇인가 하는 말이다.
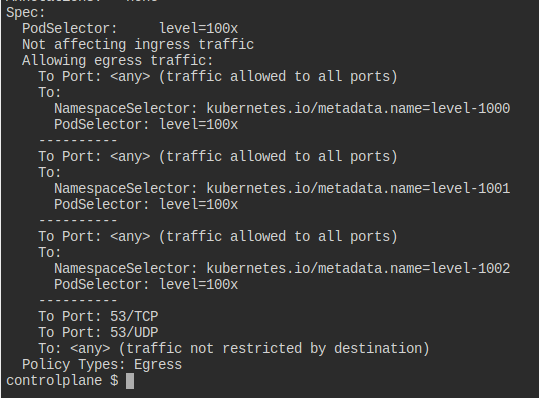
describe를 하고 나서 명확하게 고민이 풀렸다.
문서에서는 port와 to의 조건을 다 만족해야만 한다고 나오는데, 막상 보니까 그렇지 않다.
그냥 각각이 하나의 조건일 뿐이다.
그래서 - 를 어떻게 넣느냐가 중요한 것이다.
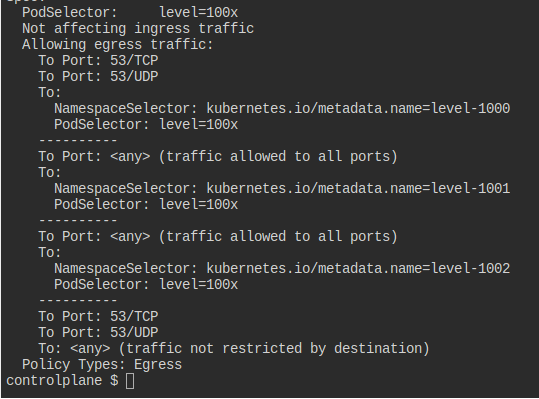
대시만 잘 바꾸면 이렇게 특정 네임스페이스로 가는 쪽은 53 포트만 허용하게 할 수도 있다.
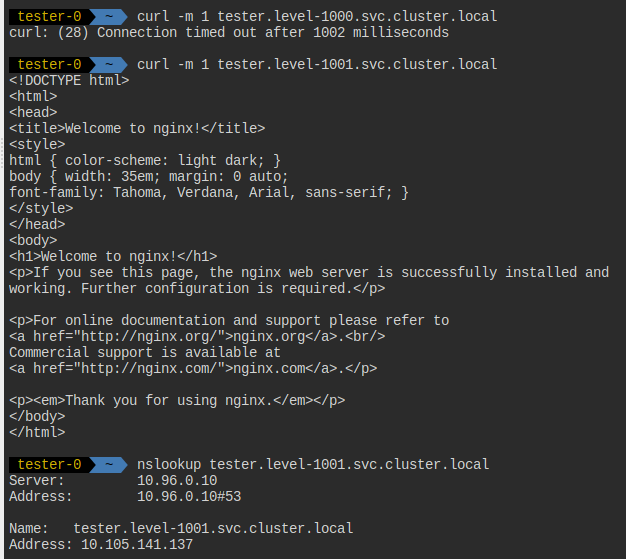
그러면 이렇게 level-1000으로는 80 요청이 불가능해진다.
참고로 이건 내가 해당 노드로 53포트를 열었기 때문이 아니라, 그냥 포트 조건이 풀려있어서 그런 것이다.
네폴은 결국 크게 4가지로 접근을 허용할 수 있는 것이다.
포트, 네임스페이스, 파드, ip
거기에 and 조건을 걸어서 조금 더 세밀하게 조건을 걸 수 있다.
RBAC ServiceAccount Permissions
ns1, ns2 네임스페이스 있다.
pipeline이라는 ServiceAccount를 양쪽에 만들어라.
이 둘은 클러스터의 모든 것을 볼 수 있어야 한다.
이를 위해 view ClusterRole을 사용하라.
이 둘은 각각 자신의 네임스페이스에 Deployment을 만들고 지울 수 있다.
kubectl auth can-i를 통해 검증하라.
이들은 클러스터의 모든 것을 볼 수 있어야 한다.
클러스터롤을 만들고, 바인딩한다.

기본적으로 서아를 만든다.
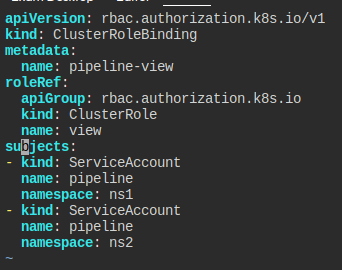
클러스터 전체에 view를 할 수 있도록, 클러스터롤바인딩을 만든다.
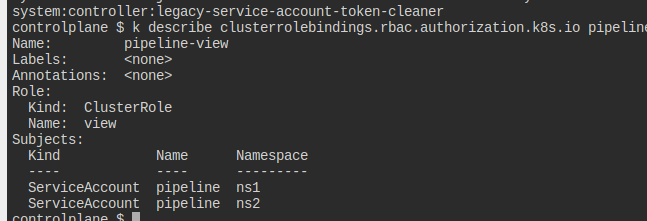
이렇게 하면 view의 권한이 각 서아에 클러스터 전체에 대해서 먹히게 된다.
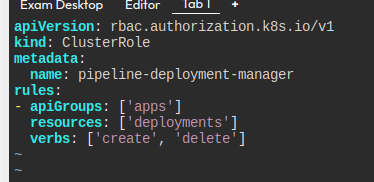
이후에는 deployment에 create, delete를 할 수 있도록 먼저 롤을 만든다.
매번 느끼지만, 정확하게 리소스 이름을 찾는 게 생각보다 어렵다.
각 네임스페이스에 롤을 만들어도 되는데, 일을 줄이고 싶다면 클러스터롤로 만드는 게 편하다.
클러스터롤을 롤바인딩하면 해당 롤을 받은 개체는 자신의 네임스페이스 안에서만 능력을 발휘할 수 있다는 것을 명심하자.
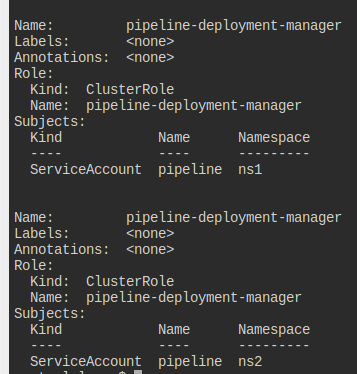
클롤 하나 만들고 각각을 롤바시키면 된다.
만약 그냥 롤이었어도 작업 방식은 같다.
# namespace ns1 deployment manager
k auth can-i delete deployments --as system:serviceaccount:ns1:pipeline -n ns1 # YES
k auth can-i create deployments --as system:serviceaccount:ns1:pipeline -n ns1 # YES
k auth can-i update deployments --as system:serviceaccount:ns1:pipeline -n ns1 # NO
k auth can-i update deployments --as system:serviceaccount:ns1:pipeline -n default # NO
# namespace ns2 deployment manager
k auth can-i delete deployments --as system:serviceaccount:ns2:pipeline -n ns2 # YES
k auth can-i create deployments --as system:serviceaccount:ns2:pipeline -n ns2 # YES
k auth can-i update deployments --as system:serviceaccount:ns2:pipeline -n ns2 # NO
k auth can-i update deployments --as system:serviceaccount:ns2:pipeline -n default # NO
# cluster wide view role
k auth can-i list deployments --as system:serviceaccount:ns1:pipeline -n ns1 # YES
k auth can-i list deployments --as system:serviceaccount:ns1:pipeline -A # YES
k auth can-i list pods --as system:serviceaccount:ns1:pipeline -A # YES
k auth can-i list pods --as system:serviceaccount:ns2:pipeline -A # YES
k auth can-i list secrets --as system:serviceaccount:ns2:pipeline -A # NO (default view-role doesn't allow)
위 케이스를 전부 통과하면 된다.
쿠버 RBAC의 방식을 잘 보여주는 테스트 방식인 것 같다.
무엇이 무엇에서 무슨 짓을 할 수 있는가?
어떤 역할을 어떤 것에 부여하여 어떤 것을 허용해준다.
RBAC User Permissions
applications라는 네임스페이스가 있다.
smoke라는 유저는 파드, Deployment, StatefulSet을 만들고 지울 수 있어야 한다.
그리고 kube-system을 제외한 모든 네임스페이스에 view 권한이 있어야 한다.

이런 식으로 일단 create를 해서 양식을 만드는 게 낫다.
특히 role의 경우에는 apigroups 찾는 것도 일이라..
참고로 찾을 때는 k explain을 해서 해당 리소스의 정보를 찾아보면 조금 도움이 된다.

이런 식으로 api-resources로 찾는 것도 방법이다!
이건 축약어도 알 수 있어서 좋은 듯?
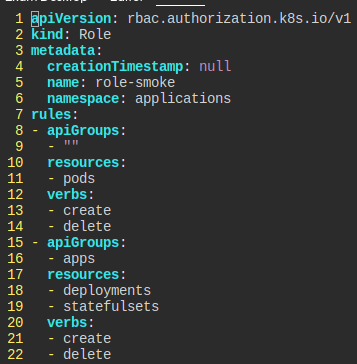
먼저 롤을 만들고, 바인딩한다.

하면서 느끼는 건데 문서가 잘 안 돼 있어서 그냥 create로 어떻게든 만들어내는 게 훨씬 나은 것 같다.
apiGroup 신경 쓰지 않아도 되기도 하고.
kube-system 빼고 모든 네임스페이스에 view 권한을 얻게 하고 싶다면, 그냥 정직하게 그것만 빼고 전부 롤바인딩을 걸어주면 된다.
귀찮지만.. 해주자..
롤 바인딩은 실제로 없는 롤이라도 만들어진다.
그래서 auth로 꼭 확인해주어야 한다.
Scheduling Priority
Find Pod with highest priority
management에 있는 가장 우선순위가 높은 파드를 찾아 지워라.

두 개의 파드가 있고, 우선순위가 많이 높다..
점수가 높은 sprinter 파드를 지우면 끝
Create Pod with higher priority
lion 네임스페이스에 메모리 1기비를 요구하는 파드가 있다.
PriorityClass가 지정되어 있다.
nginx:1.21.6-alpine 이미지의 important 파드를 만들어라.
이 녀석도 같은 메모리를 요구해야 한다.
그리고 기존보다 더 높은 우선순위를 부여해라.
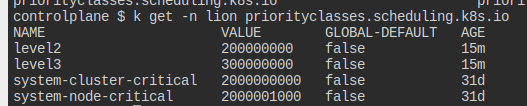
현재 존재하는 우선순위들.
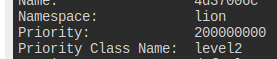
기존 파드는 레벨2이다.
그렇다면 레벨3짜리 파드를 만들면 될 것 같다.
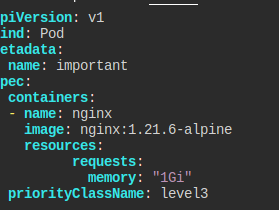
만드는 건 간단하다.
네임스페이스를 깜빡했는데, 잘 해주자.

실습 환경의 노드가 하나뿐이라, 내가 실수를 했을 때 기존 파드는 날아가버렸다.
아무튼 그러한 사실, preempted됐다는 사실은 event를 통해 확인할 수 있다.
조금 의아했던 것은 내가 만든 파드를 없앤다고 해서 이미 제거된 파드가 다시 돌아오진 않는다는 것이다.
Scheduling Pod Affinity
hobby.yaml이라는 양식 파일이 있다.
해당 파드는 level=restricted 라벨이 붙은 파드가 있는 노드에 스케줄되길 선호(prefer)해야 한다.
호스트네임으로 topologyKey를 써야 한다.
테인트, 톨러레이션는 걸려있지 않기에, 테인트, 톨러레이션은 쓰지 않아도 된다.
일단 요구사항을 보자.
내가 설정할 파드는 어떤 노드에 있는 파드를 따라가길 희망해야 한다.
그러니 파드 어피니티에 prefered가 필요하다는 말이다.

노드들의 호스트네임이 각각 다르다.
이 중에서 우리는 호스트네임을 키로 잡고 진행한다.
만약 호스트네임이 같았다면, 스케줄러는 두 노드를 같은 놈이라 간주하고 스케줄링했을 것이다.

라벨 붙은 파드가 존재하며, 이 놈은 node01에 위치한다.
'파드'가 있는 곳을 '선호'하고, level이 restricted여야 한다.
topologyKey, 즉 설정이 걸리게 될 노드의 기준은 호스트네임.
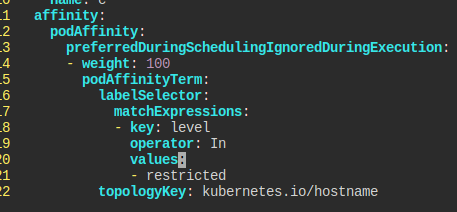
단서를 토대로 Affinity를 구성한다.

파드를 따라가서 노드1에 스케줄링됐다.
문제는 아니고 실습.
정말로 어피니티에 의해 파드가 따라가는 건지 테스트해본다.
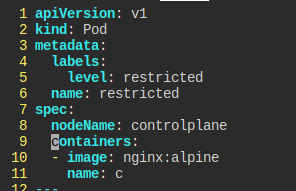
이번에는 컨트롤 플레인에 restricted를 넣어본다.

정확하게 스케줄링되고 있다.
Scheduling Pod Anti Affinity
파드 양식 파일이 있다.
level=restricted 라벨이 있는 파드가 없는 노드에 스케줄될 것이 요구된다.
topologyKey는 호스트 네임.
위의 문제와 조금만 다르다.
이번에는 선호가 아니라 요구, 라벨이 없어야 한다.

Affinity를 만들었다.
topology 부분을 들여쓰기를 한 칸 지우고, 앞에 topology를 지운다.

성공적으로 다른 노드에 할당이 됐다.
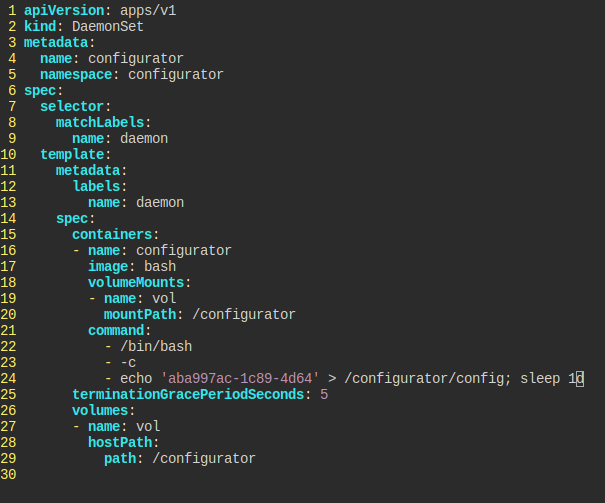
DaemonSet HostPath Configurator
DaemonSet은 노드에 어떤 일을 해야 할 때 주로 설정한다.
다음의 조건을 만족하는 데몬셋을 만들어라.
- 이름은
configurator configurator라는 네임스페이스bash이미지 사용/configurator호스트 경로 볼륨을 마운팅 받고, command를 통해aba997ac-1c89-4d64를/configurator/config경로에 써라.- 쓰고난 후에는
sleep 1d
그냥 말 그대로 따라해봤다.

뭔가 실수한 듯한데, 확인해보니 그냥 /bin/bash가 없는 것이었다.
Cluster Setup
Install Controlplane
두 개의 가상머신이 있으니 이걸로 클러스터를 구성하라.
kube 시리즈는 이미 다 깔려 있다.
일단 controle plane부터 시작이다.
- 1.30.0 버전을 사용하라
- network는 192.168.0.0/16
- NumCPI, Mm에 대한 preflight에러를 무시하라.
/root/.kube/config에 기본 admin.conf 파일을 박아라.

그냥 kubeadm 명령어 help를 쳐보니 각 옵션들이 있어서 선실행을 해봤다.
문제가 있을 수도 있으니 웬만하면 dry run을 먼저 하자.

간단하게 완료.
kubectl을 쓸 수 있게 설정 파일을 가져오는 명령어도 보인다.
그대로 따라해주면 된다.
Add Worker Node
node-summer를 워커 노드로 넣어보자.

사실 이건 별로 할 게 없다.
그냥 ssh로 해당 노드에 접근한 뒤에 처음 init할 때 나온 명령어를 다시 쓰는 것 밖에..
kubeadm token create --print-join-command를 해서 토큰을 받아 사용하는 방법도 있다.
Cluster Upgrade
Upgrade Controlplane
컨트롤플레인, kubectl, kubelet을 업그레이드하자.
현재 버전은 1.31.0이다.
그냥 공식 문서에 있는 코드 그대로 친다.

먼저 가능한 버전을 확인해보니, 다음의 버전들이 있다.
참고로 문서에 있는 코드를 한줄 한줄 치는 게 좋다.
중간 에러가 발생하는 경우 때문에 이후 명령어가 적용 안 되는 경우가 있다.

먼저 kubeadm의 버전을 올려주었다.

업그레이드 플랜을 통해 어떤 것을 사용할 수 있나 나온다.
3버전으로 올릴 수 있을 것처럼 써있지만.. kubeadm이 1버전이라 그렇게는 안 된다고 에러가 뜬다.
apply를 걸어서 실제로 업그레이드하는데는 대략 5분의 시간이 걸린다.

업그레이드가 완료되었으면 아직 동작하고 있는 kubelet을 재시작해줘야 한다.
이때 만약 배포된 리소스가 있다면 드레인 후 작업을 해야 한다.
그리고 kubectl도 업그레이드해줘야 한다!
정리하자면.. 필요한 버전의 kubeadm을 가져와서 온다.
그 놈으로 업그레이드를 진행한다.
그것에 맞게 kubectl, kubelet을 업그레이드한다.
kubelet은 재시작까지 해줘야 한다.
Upgrade Worker node
워커 노드도 업그레이드하라.
풀이랄 것도 없다..
kubeadm upgrade할 때 아까는 apply 였지만 이번에는 node라는 것 정도.

만약 드레인을 하고 싶다면 kubectl이 먹히는 마스터 노드에서 미리 진행하도록 한다.
Cluster Node Join
node01을 조인 시키자.

조인 커맨드를 어디에서 꺼내나 헷갈렸는데, kubeadm token에서 꺼낼 수 있다.
그냥 컨트롤플레인에서 join 커맨드를 가져오고, 이를 워커 노드에 복붙한다.
Cluster Certificate Management
Read out certificate expiration
kube-apiserver의 인증 만기일을 출력하여 apiserver-expiration에 저장하자.
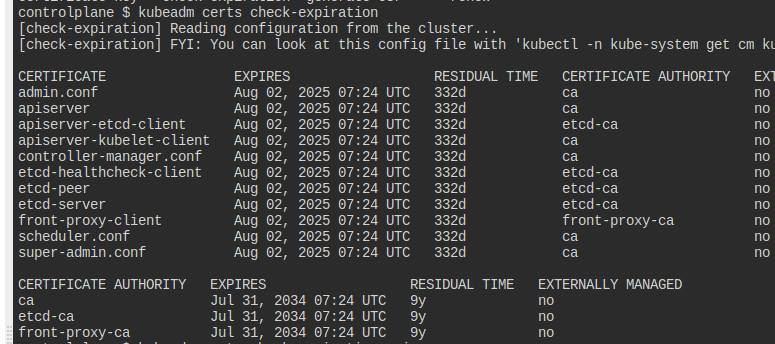
그냥 kubeadm 뒤적거리다 보면 나온다.
expires에 해당하는 내용만 파일로 저장해준다.
Renew certificates
apiserver, scheduler.conf를 새로 갱신하자.
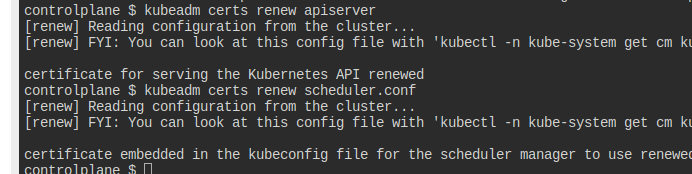
간단하다.
항상 이런 설정 이슈는 이렇게 하는 방법이 있다는 것을 아는 게 중요하다.
설정법은 결국 간단하기 때문이다.
Static Pod move
Move a static Pod to another Node
resource-reserver-beta를 컨트롤플레인에 옮기고, 이름도 v1으로 바꾸자.

node01에 위치하고 있다.
정적 파드는 해당 노드에서 자체적으로 양식을 관리하기에 이걸 통째로 옮겨야 한다.
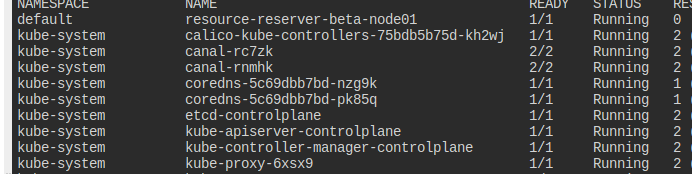
node01에 파드가 위치한다.
그냥 바로 가져와서 이름을 바꿔주면 끝.
노드에 있는 녀석은 지워주도록 한다.