Sachin H R
개요
이 분 문제는 조금 많이 엉성하다.
https://github.com/SachinHR/scenario-examples/tree/main
여기에서 답을 확인해가면 하는 것이 낫다.
Log Reader - 2
alpine-reader-pod가 돌아가고 있다.
모든 로그를 podlogs.txt에 저장하라.

그냥 이거 저장하면 된다.
Log Reader
log-reader-pod 파드가 있다.
모든 파드 로그를 podalllogs.txt에 저장하자.

k logs log-reader-pod > podalllogs.txt
이것도 마찬가지.
ETCD Restore
etcd-controlplane이 kube-system에 돌아가고 있다.
현재 디비를 /opt/cluster_backup.db로 백업하여 저장하라.
--data-dir에 /root/default.etcd를 사용하라.
복구한 출력물을 restore.txt에 저장하라.

일단 etcdctl을 쓰기 위해서는 인증파일들이 필요한데, 이것은 apiserver 양식에서도, etcd 양식에서도 찾을 수 있다.
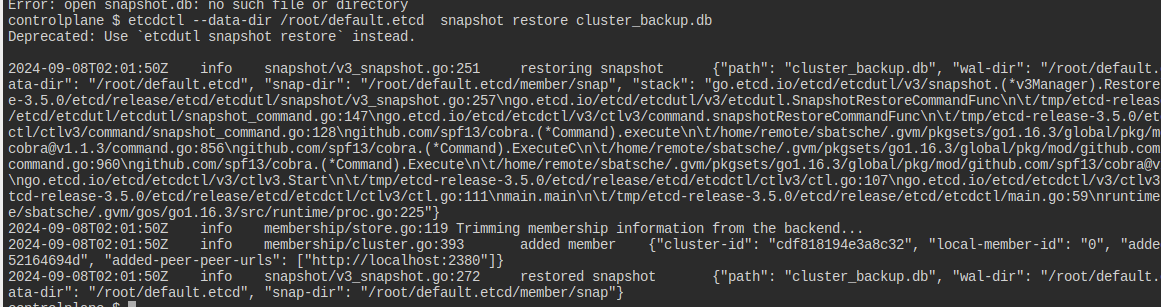
etcdutl을 써보고 싶었으나 설치가 안 돼 있어서 불가.

백업은 먼저 이렇게 한다.

백업이 된 것을 확인할 수 있다.
restore를 할 때는 사용할 디비 경로를 지정해야 한다.

표준 출력으로 나오는 것이 아니라 에러까지 잡아서 넣어야 한다..
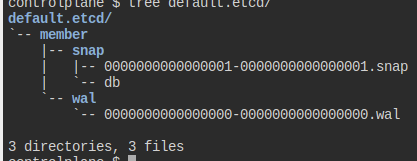
이렇게 디렉토리가 생겼다.
이렇게 하면 백업과 복구는 되는 것이다.
그러나 실제 etcd 파드가 이를 반영하게 하기 위해서는 복구가 된 경로로 etcd 데이터 저장소를 수정해야 한다.
정적 파드라 바꾸기만 하면 알아서 반영된다.
ETCD Backup
etcd-controlplane이 kube-system에 돌아가고 있다.
현재 디비를 /opt/cluster_backup.db로 백업하여 저장하라.
백업할 때의 출력물을 restore.txt에 저장하라.
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/apiserver-etcd-client.crt --key=/etc/ku
snapshot save /opt/cluster_backup.db &> backup.txt
위 문제보다 먼저 풀어야 하는 문제이다.
Secret 1
database-ns에 있는 database-data 시크릿에 있는 값을 디코딩하고, decoded.txt에 넣어라.

시크릿이 확인된다.

내용물은 제대로 보이지 않는다.

yaml 파일로 보면 확인이 되며, 이를 base64로 디코딩하면 된다.
이때 줄바꿈 문자가 같이 들어가지 않도록 주의해야 한다.

echo를 통해 입력으로 데이터가 들어가게 만든다.
이렇게 하지 않을 거라면 아예 파일로 저장한 뒤에 인자로 넣어줘야 한다.
참고로 데이터값은 secret이다..
Secret
database-data.txt 파일의 내용으로 database-app-secret 시크릿을 만들어라

자동완성이 잘 돼서 편하게 할 수 있다.

참고로 이미 인코딩이 돼있는 상태이다.

또한 내용도 이렇다..
또 참고로, 어차피 이렇게 secret와 시켜봐야 etcd에 저장될 때 암호화되지 않기 때문에 결국 외부 인증 공급자를 쓰는 것이 좋다.
Cluster Upgrade
컨트롤 플레인의 kubeadm, kubelet, 클러스터를 전부 한 단계 업그레이드하자.
딱 한 단계만 올려야 한다!
이전에 한 것처럼 문서의 순서를 밟으면 된다.

일단 kubeadm을 업그레이드 한다.
정확하게 1.31.1로 업그레이드하면 된다.
sudo apt update
sudo apt-cache madison kubeadm
sudo apt-mark unhold kubeadm
sudo apt-get update && sudo apt-get install -y kubeadm='1.31.1-1.1'
sudo apt-mark hold kubeadm
sudo kubeadm upgrade plan
sudo kubeadm upgrade apply v1.31.1
sudo apt-mark unhold kubelet kubectl
sudo apt-get update && sudo apt-get install -y kubelet='1.31.1-1.1' kubectl='1.31.1-1.1'
sudo apt-mark hold kubelet kubectl
sudo systemctl daemon-reload
sudo systemctl restart kubelet
귀찮아서 스크립트로 전부 따버렸다.

노드의 버전에서 출력되는 것은 kubelet이기 때문에 kubelet을 재시작하지 않으면 업그레이드된 것으로 나타나지 않게 된다.
Service Filter
svc-filter.sh가 있다.
jsonpath만 사용해서 redis-service의 타겟 포트를 노출하는 명령어를 안 속에 작성하라.
kubectl의 명령어만 사용해야 한다.
어떻게 명령어를 쓰는지가 관건이다.

일단 이렇게 json 경로를 뽑아낼 수 있다.
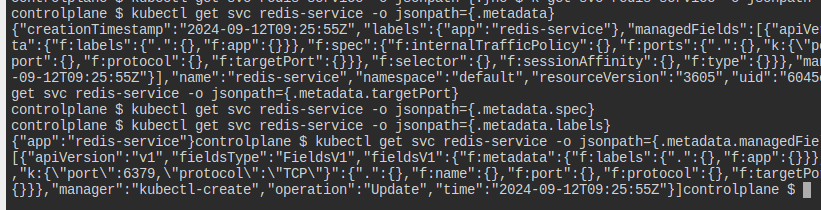
그다음부터 정확한 경로를 찾아나가면 된다.
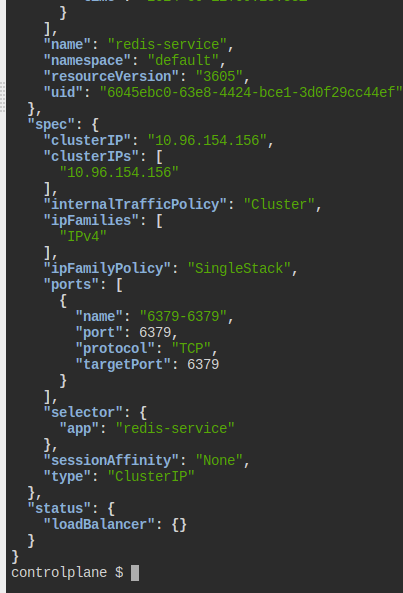
jq를 써서 편하게 보는 것도 방법이겠다.

찾았다.
kubectl get svc redis-service -o jsonpath='{.spec.ports[0].targetPort}'
근데 출제자가 문제를 대충 만들어서 무조건 조금이라도 틀리지 않게 작성해야 한다.
kubectl을 별칭으로 작성하거나 하면 안 된다..
Service account, cluster role, cluster role binding 1
app-account, app-role-cka, app-role-binding-cka를 만들어라.
(이름은 왜 클러스터 롤이지)
해당 계정은 오직 기본 네임스페이스의 파드에만 겟할 수 있어야 한다.

순서대로 만들어준다.
모른다고 출제자 깃허브를 참고하면 도움이 안 된다.
왜냐하면 레포지토리에는 예전 기준의 답이 들어있기 때문이다.
이전에는 클러스터롤을 하라는 문제가 나왔었다.

이렇게 테스트를 해볼 수 있다.
Service account, cluster role, cluster role binding
ServiceAccount group1-sa, ClusterRole group1-role-cka, ClusterRoleBinding group1-role-binding-cka가 있다.
이때 이 계정이 Deployment에만 create, get, list를 할 수 있도록 만들자.

일단 언급된 클롤은 get만 있다.
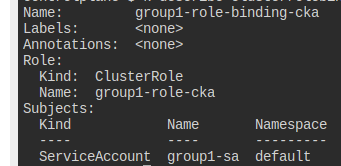
제대로 바인딩이 되어 있으니, 롤만 수정하면 될 듯하다.
별 것 없이 해당 클롤 edit만 해주면 끝난다.
직접 테스트도 꼭 해보자.
Pod Resource
모든 네임스페이스에서 가장 cpu를 많이 소모하는 파드를 찾아라.
그것을 high_cpu_pod.txt에 pop_name,namespace 형식으로 적어라.
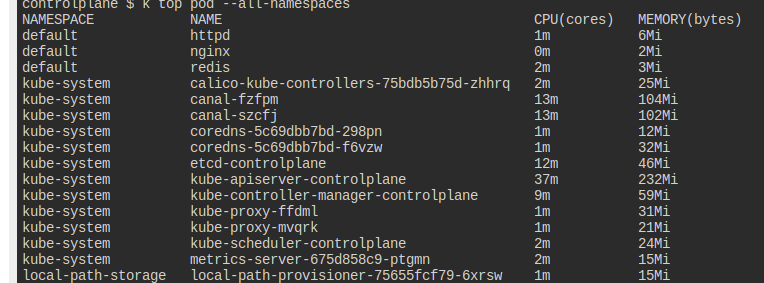
top을 사용하면 현재 사용량을 확인할 수 있다.
kube-apiserver가 가장 많이 먹는 것이 확인된다.
Pod Logs - 1
product 파드의 로그를 찍으면 Mi Tv Is Good라 출력될 것이다.
양식 파일에서 변수 부분을 수정해서 Sony Tv Is Good가 나오도록 하라.
k get pods product -o yaml >> pod.yaml
간단하다.
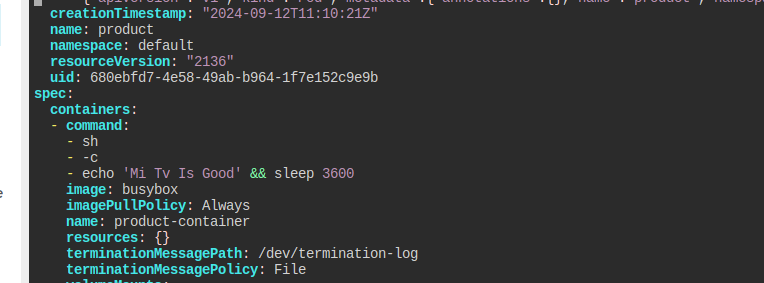
여기 이 부분만 고쳐주면 끝이다.
당연히 이전 파드를 지우고 다시 apply한다.
말은 환경 변수를 사용해야 한다는 것 같았는데, 막상 보니까 그렇지 않았다.
Pod Log
다음의 요구사항을 만족하는 파드를 만들어라
- 이름
alpine-pod-pod - 이미지
alpine:latest - 컨테이너 이름
alpine-container - sh로
tail -f /config/log.txt를 할 것- 이 명령어는 args로 전달하고, sh는 command로 전달
config-volume이란 이름으로log-configmap이란 ConfigMap을 마운팅할 것- 재시작 정책은
Never
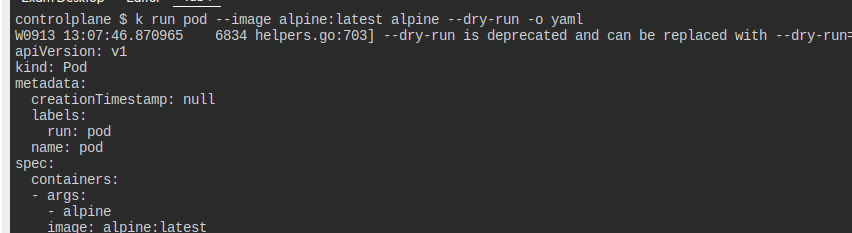
그냥 요구사항대로 파드를 만들면 된다.
시작은 대충 만들어서 양식만 얻어내고, 여기에서 세부 설정을 넣자.
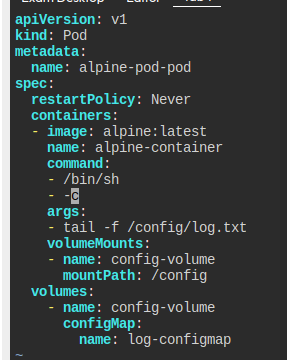
문제가 매우 짜증나는 게, command와 args를 분리해서 작성해야 한다.
그런데 심지어 -c옵션은 무조건 command쪽에 넣어야만 한다.
이것만 유의하면 됨
Pod filter
nginx-pod의 application를 출력하는 스크립트를 짜라
jsonpath만 사용하라.
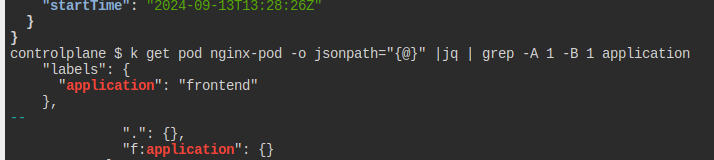
뭘 말하나 했는데, 아마 labels를 말하는 것 같다.
kubectl get pod nginx-pod -o=jsonpath='{.metadata.labels.application}'
매우 귀찮지만, 정확하게 이렇게 쳐야 통과한다.
Create Pod
nginx 이미지를 쓰고 sleep 시키는 sleep-pod라는 파드를 만들자.
k run sleep-pod --image nginx --command sleep 3600
그냥 대충 이렇게 만들면 된다..!
자동 완성 기능을 적극 활용하면 좋다.
Node Resource
가장 메모리를 많이 소비하는 노드를 찾자.
current_context,node_name 형식으로 high_memory_node.txt에 저장하자.

top으로 확인해보니 controlplane이 답인 듯하다.

config로 context를 확인할 수 있다.
echo kubernetes-admin@kubernetes,controlplane >> high_memory_node.txt
Log Reader - 1
application-pod에 있는 에러 로그만 poderrorlogs.txt에 저장하자
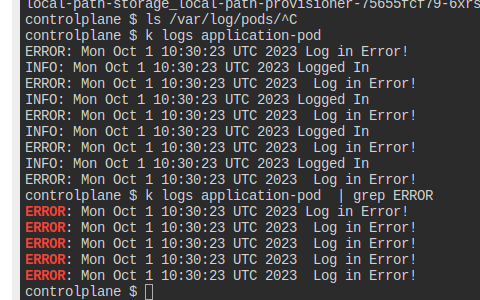
무슨 방법이 있나 하고 찾아봤지만, 그냥 grep으로 문자열을 검사하는 수밖에 없는 듯하다.
Services
nginx-pod가 있다.
nginx-service로 클러스터 내부에 노출시키자.
포트포워딩하여 curl로 접근이 가능하도록 만들자.
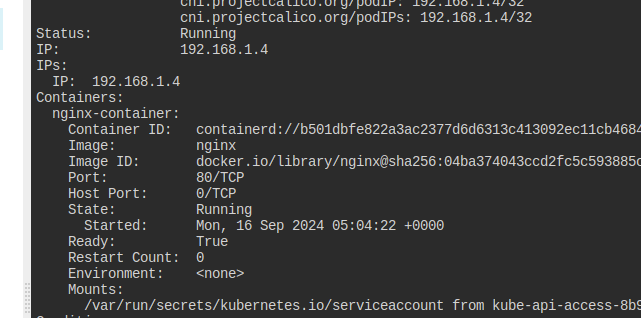
해당 파드는 80번 포트가 열려 있다.
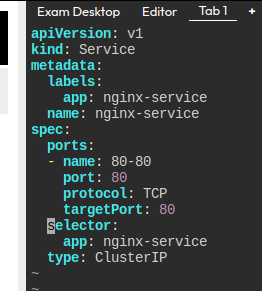
일단 서비스를 하나 만든다.
셀렉터는 nginx로 바꾼다.
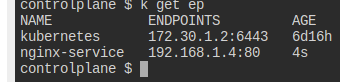
제대로 엔드포인트가 만들어졌는지도 확인해본다.
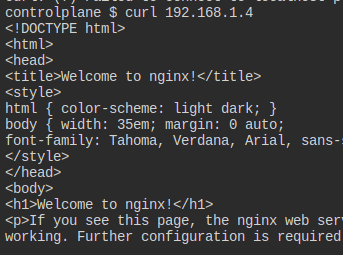
여기까지만 해도 curl로 클러스터 ip로는 접근이 가능해진다.
정답도 인정된다.
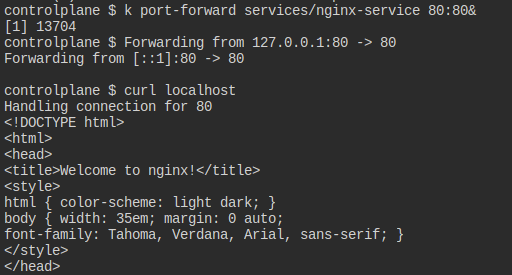
근데 내 생각에는 이걸 바란 게 아닐까 한다.
port-forward를 쓰면 잠시 포트를 로컬호스트로 연결해둘 수 있으니 이걸 바란 게 아닐까..
ClusterIP
nginx-deployment의 80번 포트를 8080에서 노출하는 nginx-service를 만들자.
매칭된 ip들을 pod_ips.txt로 저장하자.

디플이 관리하는 파드는 app: nginx-app을 사용하고 있다.

연결된 엔드포인트는 이렇게 나온다.
이름 커스터마이징을 하기 위해 결국 양식으로 만든다.
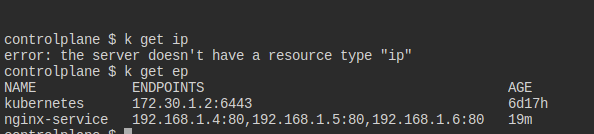
남은 건 ip들을 원하는 방식으로 꺼내어 저장하는 건데, 방법을 잘 모르겠다.

어떻게든 꺼내어보고는 있는데, 쉽지는 않네.
이 정도 수준에서 만족하고 나머지는 알아서 수정해서 넣었다.
CoreDNS
dns-ns 네임스페이스에 dns-rs-cka라는 레플리카셋을 만들자.
registry.k8s.io/e2e-test-images/jessie-dnsutils:1.3를 이미지로 삼고, dns-container라는 이름의 컨테이너에 3600초 슬립시키고 2개의 복제본을 만들어라.
만들어지면 해당 파드를 통해 nslookup kubernetes.default 를 하고 결과물을 dns-output.txt에 저장하자.

네임스페이스부터 만들어야 한다..
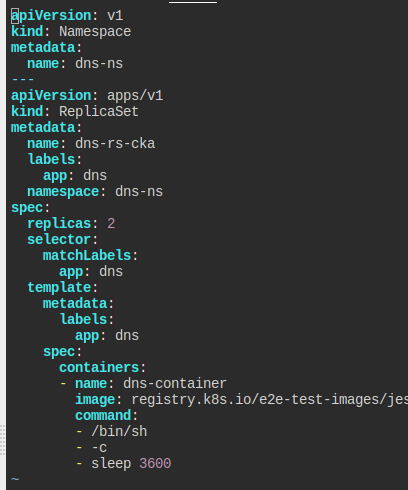
네임스페이스부터 만들고, 레플리카셋을 만든다.
공식 문서에서 양식을 가져왔다.

그러나 내부에서 동작이 잘 일어나지 않는다.
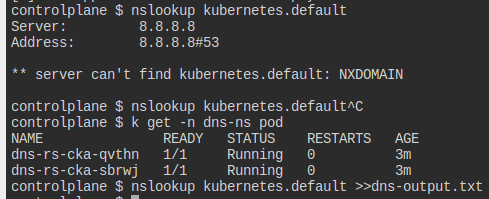

직접 들어가보니 타임아웃이 발생하고 있다.
뭐.. 근데 그냥 이렇게 내고 정답으로 처리가 된다;;
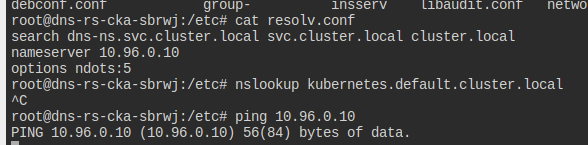
내부에 들어가서 보니까 네임서버가 동작을 안 하는 듯 하다.

연결된 엔드포인트가 없어서 생기는 문제인 것일까?
https://stackoverflow.com/questions/65744565/kubernetes-dns-lookg-not-working-from-worker-node-connection-timed-out-no-ser
이런 이슈일 가능성도 있다.
CoreDNS - 1
다음의 조건 만족하는 Deployment를 만들어라.
dns-ns네임스페이스에 있어야 한다.- 이름은
dns-deploy-cka - 2개의 복제본
registry.k8s.io/e2e-test-images/jessie-dnsutils:1.3이미지 사용dns-container에sleep 3600커맨드
파드가 돌아가면 nslookup kubernetes.default를 하고 결과를 dns-output.txt에 저장하자.

먼저 네임스페이스를 만들어준다.
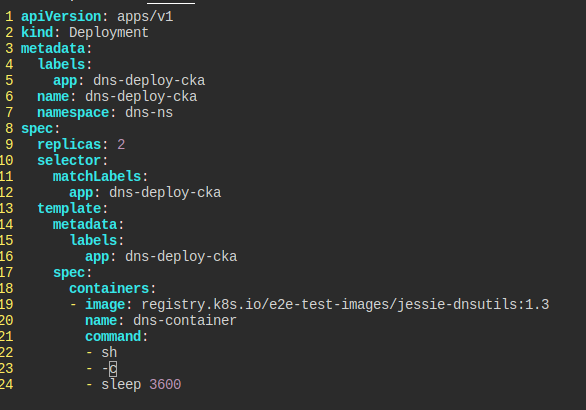
요구에 맞춰 디플로이먼트를 만든다.

위 문제와 다르게 이쪽은 잘 나온다.
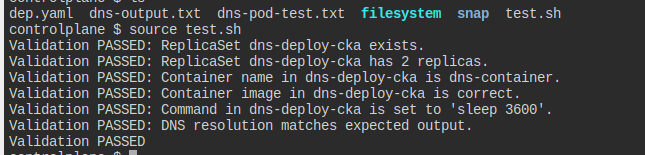
깃허브의 검증기를 가져와 테스트해봤는데, 막상 결과는 failed라고 하니 나는 그냥 넘어가려고 한다.
이 정도 검증은 내가 시험에서도 할 것 같고 그 이상 틀렸다고 생각하지 않고 넘어갈 것 같다고 생각하기에, 시험 환경에 맞춰서 내가 연습하고 있는 것이라면 잘 하고 있는 것이라 생각할 만한 것 같다.
Ingress
nginx-service로 노출된 nginx-deployment가 있다.
nginx-ingress-resource를 만들어라.
- pathType: Prefix
- path: /shop
- Name: nginx-service
- Port: 80
- ssl false
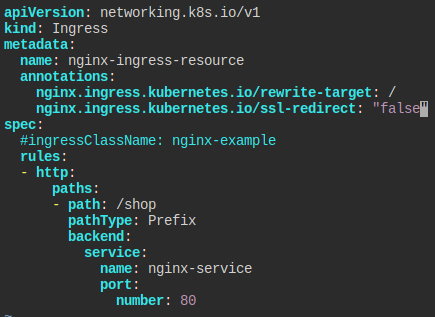
공식 문서를 보고 따라하면 된다.
ssl-redirect는 깃허브까지 가서 봐야 하던데, 공식 문서에 없어서 곤혹을 치룰 수도 있겠다.
ingressclass를 지정하지 않으면 디폴트 값이 사용된다.
Network Policy
my-app-deployment는 my-app-service로 노출되고 있고, cache-deployment도 있는 상태.
다음의 조건을 만족하는 네트워크 폴리시를 만들어라.
- 이름:
my-app-network-policy my-app-deployment로 가는 들어오고 나가는 모든 트래픽을 다음의 조건에 맞게 제한한다.- 파드로부터 오는 트래픽을 허용한다.
app=trusted가 붙은 파드로부터 오는 트래픽만 허용한다.- 파드로 나가는 모든 트래픽은 허용한다.
- 그 외의 모든 트래픽을 제한한다.

정책을 적용하는 파드가 무엇인지부터 작성한다.
파드의 라벨은 app: my-app이다.

사실 문제가 조금 이상하다.
파드에서 오는 트래픽을 허용한다는 게 첫 조건인데, 다음 조건은 특정 라벨의 트래픽을 허용하라고 한다.
검증 스크립트를 보니까, 같은 네임스페이스에서 오는 파드 트래픽을 허용하고, 라벨이 붙은 놈은 80 포트만 허용하라고 한다.
문제가 정말 문제 있다고 생각한다.
아무튼 이를 토대로 정책을 작성한다.
NodePort
app-service-cka라는 노드포트를 만들어라.
nginx-app-space 네임스페이스에 있는 nginx-app-cka 디플로이먼트를 노출시켜야 한다.
tcp에 포트, 타겟 포트는 80이다.
노드포트는 31000이다.

대상 삼을 라벨은 app=nginx-app-cka이다.

조건에 맞춰 양식을 작성한다.
NodePort - 1
다음의 조건을 만족하는 디플로이먼트를 만들어라.
- 이름:
my-web-app-deployment - 이미지:
wordpress - 복제 수: 2
이후에는 my-web-app-service라는 이름으로 노드 포트 30770을 노출하는 서비스를 만들어라.

포트 번호에 대한 이야기가 없어 그냥 80으로 했는데 잘 먹혔다.
Nslookup
nginx-pod-cka 파드를 만들고, 이것을 nginx-service-cka라는 이름으로 노출해라.
busybox:1.28 이미지를 써서 nslookup을 해보고, 결과를 nginx-service.txt에 저장하자
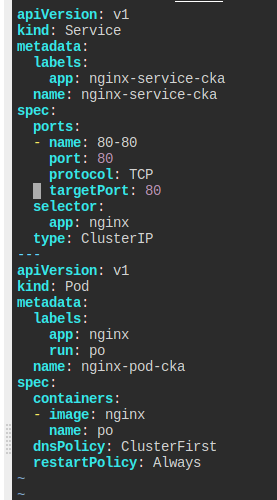
셀렉터 지정을 위해 제대로 만들어준다.
이후에는 그냥 nslookup 아무 파드 하나 잡고 해서 결과를 저장만 하면 된다.
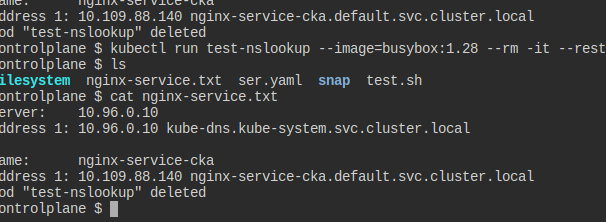
왜 계속 틀리나 봤는데, 이제는 pod "test-nslookup" deleted까지 똑같았어야 한댄다..
진짜 수준 심각하다.
Storage Class
green-stc라는 StorageClass를 만들어라.
kubernetes.io/no-provisioner를 써야 한다.- 바인딩 모드는
WaitForFirstConsumer - 볼륨 확장이 가능해야 한다.
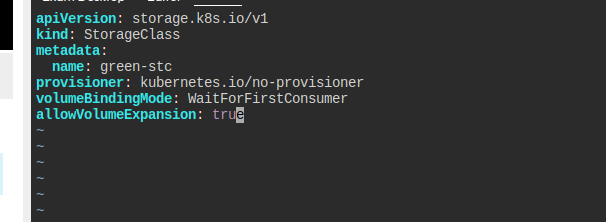
공식 문서 맨 아래 해답이 있다.

잘 만들었다면, sc가 생긴다.
Shared Volume
my-pod-cka라는 파드와 my-pvc-cka라는 pvc가 이용 가능한 상태이고, 다음의 요구를 맞춰라.
busybox이미지를 써서 사이드카 컨테이너를 만들어라.tail -f /dev/null를 통해 계속 돌아가도록 만들자.
- 메인과 사이드가
shared-volume을 통해 연결되도록 하자./var/www/shared에 마운트한다.- 사이드카 컨테이너는
read-only여야만 한다.
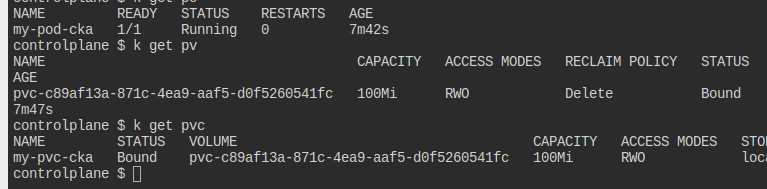
준비물은 다 갖춰졌다.
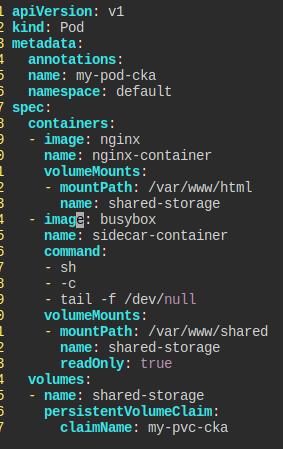
get으로 파드를 꺼낸 후, 내 입맛에 맞게 수정했다.
웃긴 게 여기 컨테이너 이름을 무조건 sidecar-container라고 지정해야 한다.
문제에는 명시가 되어 있지 않는데 말이다.
Persistent Volume Claim Resize
yellow-pvc-cka라는 PersistentVolume을 yellow-pv-cka에서 60Mi만큼 요청하도록 바꿔라.
성공적으로 됐다는 것을 보장해야 함

pv는 retain 정책을 가지고 있다.
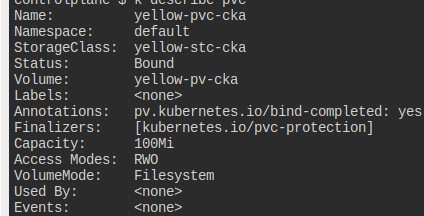
달리 말해 이 녀석만 수정해주면 다 잘 된다는 것.
말 그대로 edit으로 바꿔주면 끝난다.
Storage Class, Persistent Volume, Persisten Volume Claim, Pod
다음의 요구사항을 충족해 만들기
- 스토리지 클래스
- 이름
fast-storage - 프로비저너
kubernetes.io/no-provisioner - 모드
Immediate
- 이름
- PersistentVolume
- 이름
fast-pv-cka - 용량 50Mi
ReadWriteOnce- 경로
/tmp/fast-data
- 이름
- PersistentVolume
- 이름
fast-pv-cka - 요청 30Mi
- 이름
- 파드
- 이름
fast-pod-cka - 이미지
nginx:latest /app/data에 pvc 연결
- 이름
순서대로 만들면 된다.
sc는 기존에 있는 걸 참고한다.
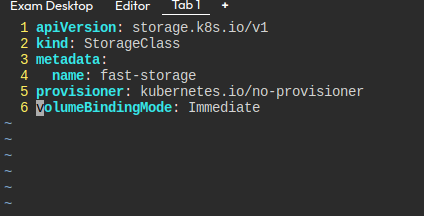
이런 식으로 만들면 된다.
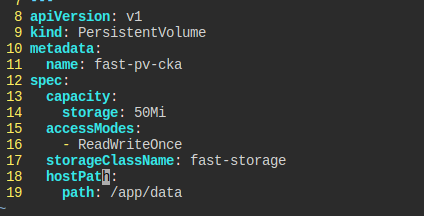
다음은 pv인데, 경로가 존재하니 hostpath로 만들면 된다.
근데 동적 프로비저너 쓰는데 이걸 왜 만드는 건가 싶었는데, local sc는 동적 프로비저닝을 해주지 못한다고 한다.
특히 1.31버전에서는 안 된다고 못 박혀 있다.
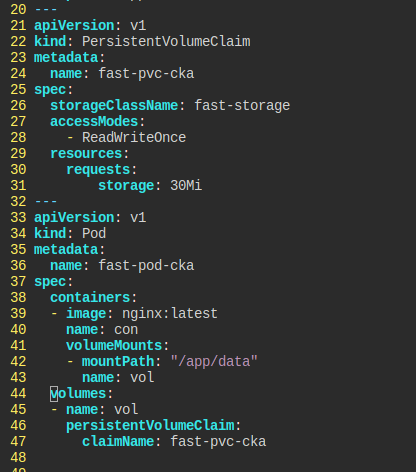
pvc와 파드의 모습.
문서에 있는 내용을 거의 베껴서 넣었다.
Persistent Volume, Persisten Volume Claim, Storage Class
다음의 요구사항을 충족해 만들기
- 스토리지 클래스
- 이름
blue-stc-cka - 프로비저너
kubernetes.io/no-provisioner - 모드
WaitForFirstConsumer
- 이름
- PersistentVolume
- 이름
blue-pv-cka - 용량 100Mi
ReadWriteOnce- 회수 정책
Retain - 경로
/tmp/fast-data - 노드 어피니티
controlplane
- 이름
- PersistentVolume
- 이름
fast-pv-cka ReadWriteOnce- 요청 50Mi
- 명확하게 pv에 바운드되도록
당연히 각각이 연결되게 만들면 된다.
- 이름
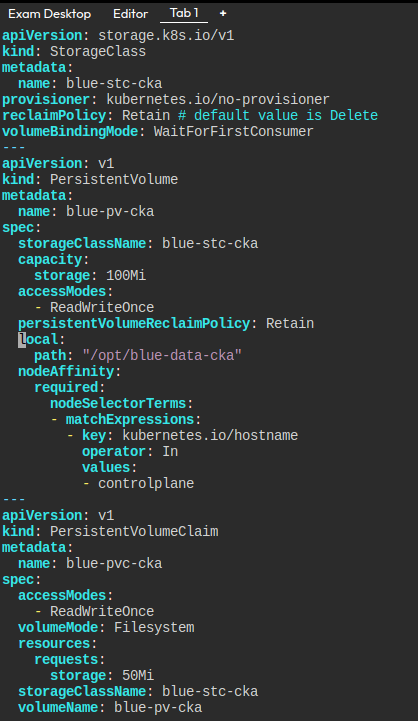
일반 문서에는 잘 안 나오고, api 문서를 보는 게 조금 편하다.
특히 어피니티를 걸 때 그렇다.
이렇게 하면 waitfor옵션 때문에 pvc 자체는 펜딩이나, 볼륨을 명시했기에 할당은 된다.
Persistent Volume Claim, Pod
nginx-pod-cka.yaml 파일이 있다.
다음의 요구사항에 맞춰 수정하자.
- PersistentVolume
- 이름
nginx-pvc-cka - 제한 80Mi
nginx-pv-ckapv,nginx-stc-ckastc.ReadWriteOnce
- 이름
- 이 pvc를 파드에 /var/www/html로 마운팅하기
- 톨러레이션 걸기
- 키
node-role.kubernetes.io/control-plane존재하면NoSchedule
- 키
peach-pod-cka05-str가 돌아가고 여기에 바운딩된 것 확인하기.
마지막 파드는 뭘 말하는 건지를 모르겠다.

요구를 다 맞췄다고 생각했으나, 되지 않는다.
파드가 컨트롤 플레인에 안착해야 한다.
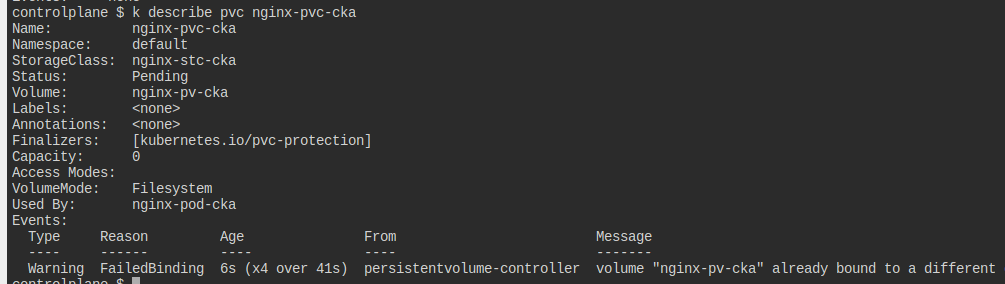
에러 원인을 물색하다 발견한 것은 pvc가 제대로 만들어지지 않고 있다는 것.
아무래도 회수 정책이 retain이었던 것이 문제가 되는 걸까.
수정하면서 계속 지웠다 말았다 한 게 화근인 듯.
retain을 바꾸려면 pv 째로 지웠다 다시 만들어야 한다.
vi apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nginx-pvc-cka
spec:
storageClassName: nginx-stc-cka
volumeName: nginx-pv-cka
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 80Mi
---
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod-cka
spec:
containers:
- name: my-container
image: nginx:latest
volumeMounts:
- name: vol
mountPath: /var/www/html
volumes:
- name: vol
persistentVolumeClaim:
claimName: nginx-pvc-cka
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
나머지는 그냥 요구사항대로 만들면 된다.
그냥 기다리기만 해도 해결되는 문제였다;;
Persistent Volume Claim
red-pv-cka라는 pv가 있다.
다음의 조건을 만족하는 pvc를 만들어라.
- 이름
red-pvc-cka - 리퀘스트
30Mi - 접근 모드
ReadWriteOnce
간단하게 내용만 맞춰주면 된다.

Persisten Volume, Persistent Volume Claim, Pod
pvc, pv, pod를 만들어라.
- pv
- 이름
my-pv-cka - 용량 100Mi
- 호스트 패스
/mnt/data - 스토리지 클래스
standard
- 이름
- pvc
- 이름
my-pvc-cka - 스토리지 클래스
standard - 용량 100Mi보다는 적게
- 이름
- pod
- 이름
my-pod-cka - 이미지 nginx
/var/www/html에 마운팅
- 이름

한번에 전부 만들어준다.

기다리다보면 바운딩된다.
Persistent Volume, Persistent Volume Claim
pvc, pv를 만들어라.
- pv
- 이름
gold-pv-cka - 용량 50Mi
- 호스트 패스
/opt/gold-stc-cka- node01에만 있으며 이쪽으로 연결되게 해야 한다.
- 스토리지 클래스
gold-stc-cka - 라벨
tier: white
- 이름
- pvc
- 이름
gold-pvc-cka - 스토리지 클래스
gold-stc-cka - 용량 30Mi
- 라벨을 통해 pv와 연결
- 접근 모드
ReadWriteMany
- 이름
node01 노드에 연결이 돼야 한다는 제약이 있다.
pv에서 관련하여 할 수 있는 설정은 nodeaffinity이다.
구체적으로는 해당 노드에 있는 파드들만 사용할 수 있도록 하는 것인데, 결과적으로는 같은 말이긴 하다.
어차피 호스트패스로 하고 있기 때문이다.

근데 애초에 해당 노드에 디렉토리가 있다고 문제에 나와있었는데.. 없다.

이렇게 만들어줬다.
원래는 readwriteonce도 넣어놨었는데, 검증 로직이 또 첫번째 값이 무조건 many여야만 하게 해뒀더라.

hostpath에 디렉토리라고 타입을 명시했는데, 이것은 확실하게 디렉토리가 있을 때만 연결되도록 하는 옵션이다.
이번 문제에서 요구하지는 않는다.
Persistent Volume
pv를 만들어라.
- 이름
black-pv-cka - 용량 50Mi
- 호스트 패스
/opt/black-pv-cka- node01에만 있으며 이쪽으로 연결되게 해야 한다.

단순하게 만들면 된다.
Deployment Issue 1
nginx-deployment 디플이 동작하지 않는 것을 해결하라.

해당 디플이 관리하는 파드의 이벤트를 보면 해답이 나온다.
초기화 컨테이너 부분에서부터 문제가 발생하고 있다.

nginx-configmap으로 바꿔주면 될 것 같다.

원래는 nginx-configuration이라 돼있었다.

이를 해결하니 다른 문제가 발생한다.

쉘이라는 이름이 없는 것도 문제다.

테스트가 실패하길래 뭔가 했는데, 함부로 볼륨의 이름도 바꾸면 안 된다;;
실제 시험에서도 이럴 수 있으니 조심하는 게 좋겠다.
Pod Issue
hello-kubernetes 파드가 돌아가도록 수정하라.

현재 이슈는 이렇다.
커맨드를 주옥 같이 써놨다는 거다.

또 왜 안 되길래 왜 그런가 했는데 /bin/sh로 적으면 또 안된다 씹 ㅋㅋ
Pod Issue - 1
nginx-pod가 안 돌아가니 고쳐주세오 찡찡

이미지를 그지 같이 받고 있다.
latest라고 바꿔준다.
Pod Issue - 2
redis-pod가 안 돌아가니 고쳐주세오 찡찡

이번엔 pv가 없다.

사진을 pv로 잘못 찍었는데, pvc로 이름만 바꿔주면 해결될 듯하다.

그러나 문제는 해결되지 않았다.

pvc 쪽의 이벤트인데, 이것과 문제가 관련있는가?

pv는 manual을 스토리지 클래스로 쓰고 있다.
이걸 수정하는 게 핵심이겠다.

마지막으로 이미지 이름도 고쳐줘야 한다.
이제야 좀 문제스럽게 문제가 나온다.
Pod Issue - 3
frontend 파드가 펜딩 상태니 고쳐주세오 찡찡
파드의 어떠한 설정도 지우면 안 됨!

어피니티에 맞는 노드도 없고, 테인트도 없는 것으로 보인다.

어피니티 세팅은 NodeName:frontend가 무조건 요구되고 있다.

근데 다시 생각해보니까 애초에 노드에 테인트가 없으면 되긴 하는데..
파드의 설정을 바꾸면 안 되기에 노드에 라벨을 넣어줘야할 것으로 보인다.

테인트 관련은 역시 이슈가 없었다.
라벨을 업데이트할 때 이미 있는 라벨이라면 overwrite 옵션을 넣어줘야 한다.
Pod Issue - 4
postgres-pod.yaml가 있는데, 이게 동작하도록 해주자.
파드의 어떠한 설정도 지우면 안 됨!

프로브들이 이상하게 생겼는데, 이걸 고치지 말라고?

에러가 이렇게 뜨는데..

그냥 바꿔서 해봤다.
검증 스크립트는 그냥 돌아가는 지만 확인하던데..
아무래도 설정을 지우지 말라는 것은 그냥 문제가 생긴 부분을 없던 것으로 만들지는 말라는 뜻인 듯하다.
Pod Issue - 5
redis-pod.yaml가 있는데, 이게 동작하도록 해주자.
파드의 어떠한 설정도 지우면 안 됨!

리소스 요청 시 리밋과 요청량이 문제다.
최소 리퀘스트와 최대 리밋을 지정해야 하는데, 거꾸로 된 것이다.

그래서 그대로 순서만 바꿔줬다.
Pod Issue - 6
my-pod-cka가 안 돌아가니 고쳐주세오 찡찡
파드 설정 건드리지 마라!

pvc 문제가 있나보다.

접근 모드에 문제가 있다.

pvc는 readwritemany를 바라고 있다.
pv는 해당 모드를 지원하고 있지 않으니, 해당 모드를 추가해준다.
Pod Issue - 7
node01에 테인트가 걸려있다.
application-deployment.yaml파일에 톨러레이션을 업데이트하고 돌아가게 만들어라.
파드 설정 건드리지 마라!

이렇게 테인트가 걸려있다.

정확하게 equal을 통해 value까지 맞는 값으로 넣어줘야 정답으로 쳐준다.

원하는 위치에 스케줄링됐다.
Kubectl - Config Issue
컨트롤플레인에서 kubectl이 안 먹는다.
설정 파일은 .kube/config에 있다.

포트, 경로 문제일 수도 있다.

etcd, apiserver가 전부 동작하고 있으므로 kubectl을 확인해보자.

내 인생 처음 보는 포트 번호다..!

혹시나 해서 apiserver의 포트 번호도 확인하고 바꾼다.
Deployment Issue
이제부턴 양식 건드리진 말은 빼겠다.
어차피 다 있어서..
postgres-deployment.yaml의 문제를 찾아 동작하게 만들자.

컨테이너가 만들어지지 않는다.

조금 더 가디려보니 시크릿을 잘못 가져오는 이슈가 있는 모양이다.

시크릿은 이렇게 생겼다.

여기만 바꿔주면 된다.
이름과 키 전부 바꿔주자.
Pod Issue - 8
nginx-pod가 nginx-service로 노출되고 있다.
kubectl port-forward svc/nginx-service 8080:80가 안 되는 이슈를 고쳐라.
curl http://localhost:8080이 가능하도록 하라.

엔드포인트가 만들어지지 않았다.

포트 이슈는 아니었고, 파드 쪽에 라벨이 없었다.

라벨은 실시간으로 붙일 수 있다.

포트포워딩은 터미널 입력을 가져가버려서 귀찮다..
Kubelet Issue
controlplane노드의 kubelet에 문제가 있다.
위치는 /var/lib/kubelet/config.yaml, /etc/kubernetes/kubelet.conf에 있다.

컨플에 문제가 있다.

kubelet이 동작하지 않는다.

인증서 연결에 문제가 있다.

실제 인증서 파일은 이렇다.

여기를 바꿔준다.
ca.crt가 kubelet이 클러스터 apiserver가 신뢰할 수 있는지 확인할 때 쓰는 ca 정보 파일이다.
처음에는 apiserver-kubelet-client.crt를 썼는데, 구체적으로 이건 apiserver가 가진 인증서 정보 파일에 해당한다.
그래서 ca.crt는 self signed이고, 후자는 전자에 의해 서명됐다는 걸 명심하자.

이제보니 포트에도 또 장난질을 쳐놨다.

이번엔 kubelet.conf파일을 바꿔준다.
한번 돌아가면 알아서 재시작을 하지 않기에 systemctl restart를 시켜야 한다.
Deployment Not UP-TO-DATE
stream-deployment가 up to date되지 않는데, 1이 되도록 고치자.

애초에 레플리카가 0이잖냐;;

간단하게 스케일링 해준다.
Deployment Issue 4
database-deployment 돌아가게 해주세요 찡찡

파드를 보니 pvc가 없댄다.

실제 있는 놈의 이름은 이러니 이걸로 고쳐준다.

바인딩이 안 되길래 뭔가 했는데, 요청 리소스에 문제가 있는 것 같다.

100Mi를 받은 볼륨에 150을 요청하고 있다.

pvc를 바로 수정이 되나 했는데, 안 된다고 하니 pv를 늘려본다.

하씨.. 접근 모드도 다르다 하여 ReadWriteMany도 추가해준다.
Controller Manager Issue
video-app가 0개인데, 2개로 늘려주자.

디플로이먼트는 정상적이나, 컨트롤러가 챙겨주지 못하는 상황 같다.

딱히 커스텀 컨트롤러 설정을 둔 것도 아니었으니, 기본 놈들을 보는데 controller가 확실히 문제가 있다.

정적 파드를 손봐줘야겠다.

여기가 문제다.
Network Policy Issue
red-pod, green-pod, blue-pod 파드가 있다.
red-pod는 red-service 서비스로 노출돼있다.
이 파드에 네트워크 정책을 적용했으나, 다른 두 파드로부터 접근이 가능한 상황이다.
green-pod만 접근 가능하도록 수정해라.

전부 같은 네임스페이스에 있다.
확인해보니 블루는 레디스, 그린은 톰캣, 레드는 느징스였다.

확인해보니 대놓고 레드로 들어오는 인그레스에 대해 제약을 걸고 있다.
그런데 그린, 블루 둘다 가능하게 돼있다.
포트 제약은 존재하지 않는다.

자연스럽게 블루만 지워준다.
Node Not Ready
컨트롤 플레인의 kubelet이 동작하도록 고쳐라.

정확한 원인은 모르겠으나, kubelet은 죽은 상태이다.
..? 그냥 일단 재시작해봤는데 통과.
Kubelctl - Port Issue
kubectl을 쓸 때 다음과 같은 에러를 마주한다.
The connection to the server 172.30.1.2:6443 was refused - did you specify the right host or port?
몇 초 기다리면 다시 되지만, 곧 다시 에러가 뜰 것이다.
컨트롤러 매니저가 계속 재시작될텐데, 이걸 고쳐라.
이 문제는 쿠버네티스 동작 방식을 알고 있어야 풀기 수월하다.

아니; 그냥 컨트롤러 매니저가 문제라고 이야기하면 되지, kubectl은 잘만 작동한다..

kubectl로도 추적이 가능하다.
프로브가 실패해서 재시작되는 중이다.

여기에서 문제가 생기고 있다는데, 사실 다른 양식들도 확인해봤으나 전부 비슷했다.

포트가 잘못된 걸까 봤는데, 기본 포트는 또 이게 맞다.
그렇다면 인증서 파일을 잘못 쓰고 있는 것일 수도 있겠다.

kubeconfig에 있는 값을 바꿔봤으나 달라지는 건 없었다.
근데 잘 보니 api server가 not ready다.. 이제 봤네..

스타트업 프로브가 게속 실패하고 있었다.
포트는 6443으로 열려야 한다는 것은 실행 시 커맨드를 봐도 알 수 있다.

이걸 수정하니 갑자기 이런 문제가..

그러더니 이런 문제가 발생하고,

이후에는 다른 놈들이 not ready가 됐다.

컨트롤러 매니저 컨테이너 로그를 보고 있다.
6443포트가 여기에서 등장한다.
아무래도 apiserver와의 통신이 실패한다는 것을 어필하고 있는 것 같다.
달리 말하자면, 아직 apiserver가 병신이란 거다.
...
그런데 시간이 지나고 다시 보니 해결됐다.

도저히 이해가 안 돼서, 다시 문제를 켜봤는데 이번엔 시작부터 안 터진다.
사실 이건 전형적으로 kubectl이 apiserver와 통신하지 못할 때 생기는 문제가 맞다.
이건 살짝 정리가 필요할 것 같다.
일단 문제는 apiserver이긴 했다.
이놈이 스타트조차 제대로 안 된 게 이슈였던 것이다.
그러나 이놈에 의존을 해야 하는 다른 놈들은 일단 문제없이 켜져있었다.

왜 그랬을까? 일단 이 프로브들은 정상동작했단 것이다.

내부 로그를 보면 이때도 문제가 있기는 했다.
정확하게는 apiserver와 통신이 안 돼서 계속 apiserver를 부르는 작업을 했다.
이게 사실 문제가 되는 부분은 아니다.
다만 문제는 왜, apiserver가 재가동된 이후에 이놈들의 프로브에 문제가 생겼나 하는 것이다.
아. 정적 파드 양식에 변화가 생기며 kubelet은 자동으로 apiserver를 재가동시켰을 것이다.
그러자 재가동되는 동안 다른 컨테이너에서의 헬스체크들은 connection refused가 아니라 손실되었을 것으로 생각된다.
그러자 프로브 체크도 불가능하게 되었고..
이에 따라 살아있지 않은 상태라 판별하고 kubelet은 나머지들을 되살리는 작업을 했을 것 같다.
그러나, 이미 내가 문제를 푸는데 시간을 너무 지체하여 restart 횟수가 많이 차있었다.
그렇기에 재시작 횟수가 많아질수록 지수적으로 재가동 기간을 늘리는 쿠버 설정 상 오랫동안 파드들이 낫 레디인 상태로 방치되었다...
이런 해석이 선다.
어느 정도 일리는 있는 게, 다시 풀면서 바로 이슈를 해결하자, 재시작이 금방 되면서 다른 파드들도 금새 ready 상태가 됐다.
지금 나는 두 가지 가정을 한 것이다.
- controller manager와 scheduler는 앞선 헬스체크의 응답이 돌아오지 않으면 프로브 체크도 안 되는 동기 방식으로 동작.
- 재시작이 되지 않는 동안, 파드는 낫 레디 상태로 방치되고 있음
후자는 거의 확실하다.
다만 전자가 정말 그러한지에 대한 확신은 조금 없다.
이런 설명밖에 되지 않으니 맞는 것 같기는 하지만.
Deployment Issue 3
postgres-deployment 동작하게 해주세요 찡찡

또 컨피그맵 없어서 난 이슈다.

실제 놈은 이런 이름이다.
혹시 해서 봤는데 시크릿 값도 잘못 됐다.
Deployment Issue 2
frontend-deployment.yaml가 돌아가게 만들자.

단순하게 네임스페이스만 만들어주면 된다.
Persistent Volume, Persistent Volume Claim - Issue
my-pvc가 바운딩되도록 만들어라.

일차적인 원인은 스토리지 클래스.

기본이 되는 sc는 하나밖에 없다.
직접 만들라는 뜻 같기도 하다.

sc를 만들었으나 그냥은 안 된다.

pv를 확인해보고, 사양에 맞게 pvc도 일단 수정했다.
standard를 주석해버렸는데, 이거 풀고, volumeNAme도 지정했다.
그러자 해결됐다.
CronJob Issue
cka-pod가 cka-service를 통해 내부에 노출돼있따.
cka-pod를 서비스를 통해 모니터링하는 cka-cronjob크론잡이 매분 실행되게 하라.

서비스를 통해 모니터링하라고 했으나, 파드로 바로 때리고 있다.

잡이 실패한 채로 계속 실행돼서 점점 쌓이는 중이다.

내부 로그는 역시 호스트를 못 찾는 이슈.

서비스로 만든 놈도 연결이 안 된다.

에라이;; 서비스가 애초에 파드를 노출시키지 않고 있다.
파드 쪽에 라벨을 붙여준다.

드디어 성공하는 크론잡들이 생기고 있다.

완료된 놈들은 그냥 머물러 있다.
크론 스케줄을 */1 * * * *라고 써야 정답이라 하게 해놨다;;
Service account, role, role binding Issue
dev-sa 서비스 계정, dev-role-cka 롤, dev-role-binding-cka 롤바인딩이 있다.
dev-sa가 pods와 services에 대해 create, list, get를 할 수 있게 만들어라.

롤 자체가 제공하는 권한이 잘못 됐다.

지우고 다시 만든다.
롤이나 바인딩은 이렇게 하는 게 가장 편하더라.
Service account, role, role binding Issue - 1
prod-sa 서비스 계정,prod-role-cka롤prod-role-binding-cka롤 바인딩이 있다.
해당 계정이 services에 대해 create, list, get할 수 있게 만들어주자

이번에도 권한이 다르다.
위 문제처럼 똑같이 해주면 된다.
DaemonSet Issue
cache-daemonset 데몬셋이 있는데, 컨트롤플레인에 파드를 배치하지 않는다.
모든 노드에 배치되도록 하라.
보통 컨트롤 플레인에 배치가 안 될 때는 톨러레이션을 의심해야 한다.

컨트롤플레인에는 저런 테인트가 걸려있어 우리의 데몬셋은 이에 대한 톨러레이션이 준비돼야 한다.

위치를 헷갈렸는데, 결국 파드의 스펙에 들어가야 한다.

변경이 일어나며 새로운 버전이 됐다.
ETCD Backup Issue
컨트롤 플레인이 왜 not ready인지 확인하라.
etcd-controlplane를 확인하고,/opt/cluster_backup.db에 백업하여 저장하라.
콘솔 출력물은 backup.txt에 저장하라.

낫레디 상태일 때는 일단 kubelet부터 의심해본다.

어떤 에러인지 아직은 확실치 않으나, inactive 상태.

그냥 재시작만 해도 살아나는데;;

저장하는 건 간단하다.
엔드포인트 ip를 주의하자.

문제에서는 그냥 출력만 넣어도 되긴 하지만 가급적이면 표준에러까지 출력으로 넣어주자.
Rollback
redis-deployment를 이전 버전으로 돌려라.
돌린 이후 사용되고 있는 이미지를 rolling-back-image.txt에 저장하라.
레플리카를 3으로 늘려라.

현재 버전은 2인 모양이다.

이전 버전으로 돌린다.

돌린 버전은 redis:7.0.13이다.

스케일링까지 하면 끝
Deployment
느징스를 사용하는 nginx-app-deployment를 만들고, 3개로 스케일링해라.
3개로 스케일링하라는 말까지 있는 걸 보면 일단 만들고 스케일링해서 revision을 남기라는 말로 보인다.

간단하게 명령어로 해결한다.
이전에 어떤 강사님은 쿠버의 장점이 선언형 동작 방식에 있다며 양식을 만들어서 해서 좋다고 말했다.
그러나, 이제 살짝 머리가 굵어지고 보니 선언형이란 건 그냥 desired state와 current state의 분리에 대한 개념일 뿐이라 생각한다.
Deployment Scale
redis-deploy 디플이 redis-ns 네임스페이스에 있다.
3개로 스케일링해라.
Contents

Deployment, Secret
webapp-deployment에서 민감한 파일을 그대로 양식에 담고 운영 중이다.
다음을 만족하는 시크릿을 만들어서 바꿔주자.
- 이름
db-secret - 키
- DB_Host: mysql-host
- DB_User: root
- DB_Password: dbpassword
이 키들을 환경변수로 넣어라.

여기를 바꿔주면 되는 것이다.

먼저 이렇게 시크릿을 만든다.

그 다음에 양식을 고쳐준다.

Deployment, Rollout
다음의 조건을 만족하는 디플을 만들어라.
- 이름
cache-deployment - 이미지
redis:7.0.13 - 레플리카 2
- 전략
RollingUpdate MaxUnavailable30%,MaxSurge45%- 전부 레디 상태가 되면
redis:7.2.1로 업그레이드. - revision 개수를
total-revision.txt에 저장

일단 만들고, 만들어진 놈을 yaml로 꺼내서 바꿔주면 양식이 거의 다 완성돼서 편하다.

요로코롬.. 위 사진은 순서를 거꾸로 해서 틀린 거니까 참고하자.

디플로이먼트는 템플릿의 이미지 부분을 바꾸면 알아서 rollout이 일어난다.

아 ㅋㅋ 셀렉터를 app:cache로 하랜다..
Pod, Service - 1
ubuntu-pod 파드를 ubuntu 이미지로 만들고 app=os 라벨을 붙여라.
8080 클러스터 포트를 여는 ubuntu-service 서비스를 만들어서 파드를 노출시켜라.


각각 빨리 만들고, 서비스는 셀렉터만 바꿔준다.
ConfigMap, Deployment
webapp-deployment라는 디플이 사용하는 환경변수는 자주 바뀐다.
APPLICATION=web-app를 가진 webapp-deployment-config-map라는 이름의 컨피그맵으로 관리해라.

이걸 바꿔주면 된다.

간단하게 컨피그맵을 만든다.

아예 envFrom을 해서 컨피그맵의 모든 값을 가져올 수도 있긴 하다.
오타를 내지 맙시다..
Pod, Service
You need to create a Kubernetes Pod and a Service to host a simple web application that prints "It works!" when accessed. Follow these steps:
파드와 서비스를 만들자.
- 파드
- 이름
app-pod - 컨테이너 이름
app-container - 이미지
httpd:latest - 포트
80 It works!가 출력돼야 한다(httpd 기본).
- 이름
- 서비스
- 이름
app-svc - 라벨
app-lab - 서비스 포트
80 - 타겟 포트
80 - 서비스 타입
ClusterIP
- 이름
- 포트포워딩하고, 다른 터미널에서 curl 날리기

일단 파드를 만든다.

서비스도 만들고 셀렉터 수정..

포트포워딩을 해준다.

It works!
Deployment Issue
my-app-deployment.yaml의 문제를 고쳐라.

적용해서 확인하기도 전에 문제가 많다.
일단 이미지 이름 틀려 먹었고, 리소스 순서도 잘못된 듯.

전부 바꿔서 해보니 또 문제가 있다.
요청량이 많아서 스케줄링이 하나가 안 됐다.
이러면 두 가지 해결책이 있다.
리소스 요청량을 줄여버리거나, 톨러레이션으로 컨트롤플레인에도 들어가게 하거나.

top을 막아놨으니 describe로 본다.

nodes1은 합쳐서 한 개의 cpu만 쓸 수 있게 돼있다.
내 생각에 문제 의도는 톨러레이션 아닐까 싶다.
톨러레이션을 템플릿에 넣어준다.

업데이트하는 식으로 썼는데, 기다리다 보면 완성된다.
펜딩은.. 그냥 계속 펜딩에 머물러 있다.

디플에선 현 상황을 인식하고 있다.
새로운 레플리카셋이 진행되며 자연스레 롤링 업데이트가 일어났다.
그래서 두 파드를 만들려고 했으나, 컨트롤플레인 역시 cpu 요청량이 제한된 관계로 새로 만들어진 파드 하나는 어디에도 들어가지 못한 채 남아버렸다.
처음에는 예전에 만들어진 놈이 펜딩된 건 줄 알았는데, 그 놈은 진즉에 없어진 것이다.
근데 이러면 새로운 레플에서는 펜딩 상태를 인식해줘야 하는 거 아니냐..
아무튼 레플 입장에서는 current 상태를 파드가 생성된 개수(etcd에 기록된 것)만 가지고 따진다.
그래서 ready는 1이지만 current는 2라고 말하는 것이다.

이걸 봤으면 조금 더 상태 파악이 빨랐겠다.
롤링 전략 자체는 결국 시간이 지나서 실패했다.

여러번 더 시도해봤는데, 펜딩 상태인 놈은 바로 없애고 새로 또 만들려 했지만, 역시 스케줄링이 안 돼서 진행이 안 된다.
이걸 해결하려면, 아무래도 직접 파드를 지우거나 리소스 요청량을 풀어줘야 한다.

파드를 없애서 해결해봤다.
Deployment History
video-app 디플은 여러번의 업데이트를 거쳤다.
3번째 리비전 당시의 이미지 이름을 app-file.txt에 REVISION_TOTAL_COUNT,IMAGE_NAME 형식으로 저장하라.

뭐가 여러 번인 것인??

쉽게 각 레플리카셋의 리비전 값을 알 수 있지 않을까 했는데, 그런 게 없나..

싶었는데 역시 어딘가에 방법은 다 있다.

jsonpath로 한꺼번에 꺼낼 수 있는 방법이 있다.
Pod
my-pod가 있다.
최대 제한을 50Mi로 바꿔주자.

말그대로 그 부분만 바꿔줬다.
참고로 이렇게 요청량과 제한량이 같으면 QoS가 Guaranted로 바뀐다.
근데 이거는 Burstable로 나오게 되는데, cpu 제한량이 명시가 안 돼서 그렇다.
cpu, memory가 둘 다 명시되고 두 값이 같다면 Guaranted가 되는 것.