도커와 쿠버네티스 시작하기
쿠버네티스와 클라우드 네이티브
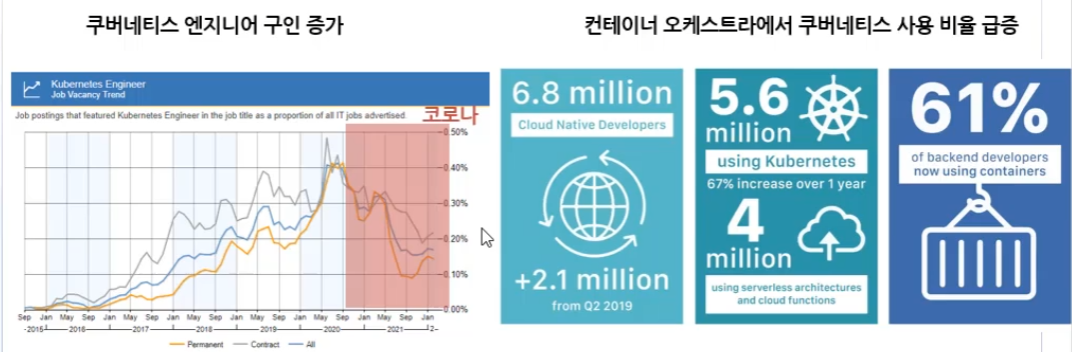
쿠버네티스 이슈
쿠버네티스란?
컨테이너 기반 오픈소스 가상화 프로젝트.
CNCF에서 관리 중
점차 쿠버네티스 지원 기업 증가 중
쿠버네티스에서 많이 활용되는 애플리케이션들

쿠버네티스의 장점을 알아보기 위해 몇 가지 용어와 지식을 보도록 한다.
클라우드 네이티브란?
CNCF의 클라우드 네이티브 정의

클라우드의 장점을 최대한 활용하여 정보 시스템을 구축 및 실행하는 환경
클라우드 환경을 통해 이뤄지는 다양한 기술, 패턴, 방법론을 포괄함
쿠버네티스는 클라우드 네이티브 구성요소를 완전히 수행할 수 있는 최고의 플랫폼
기존 앱과 클라우드 네이티브 앱의 차이점
기존 앱은 장기간에 걸쳐 결합되는 모놀리틱 아키텍쳐를 기반으로 함.
클라우드는 마이크로서비스로 구성하여 가상 컨테이너 환경에서 동작하도록 구현
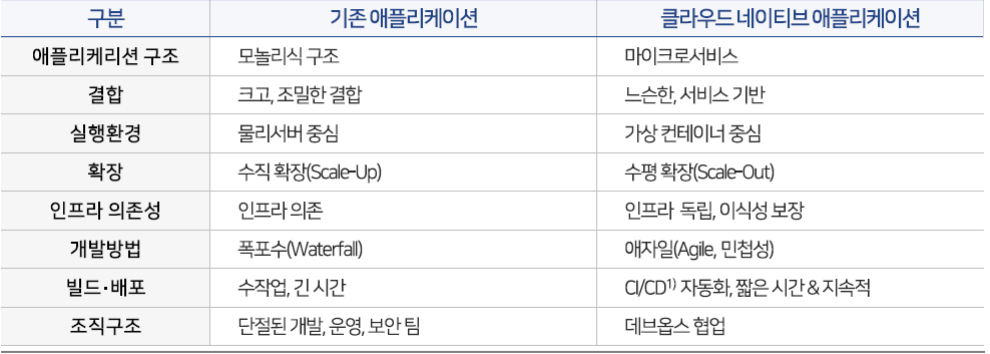
이것은 매우 나이브한 구분이지만, 클라우드 환경이 가지는 특징을 개괄적으로 확인할 수 있다.
클라우드 네이티브 애플리케이션의 차별점
컨테이너 환경을 주로 활용하기에 이식성과 독립성이 보장된다.
환경이 가벼워지고 작은 구조의 서비스를 단위로 하니 애자일에 적합하며, 애자일 방법론을 가능하게 해준다.
CICD, 자동화를 통해 운영이 개발과 긴밀한 연관을 맺게 되며 데브옵스가 가능해진다.
클라우드 네이티브 구성 요소
NIA에서 발행한 클라우드 네이티브 정보시스템을 위한 발주자 안내서에는 다음과 같이 정의한다.
- 마이크로서비스
- 기능 별, 서비스 별로 나누어 애플리케이션 개발
- 서비스를 독립적으로 분리
- 컨테이너
- 독립된 가상환경
- 경량화된 애플리케이션이 가능해짐
- 데브옵스
- 개발팀과 운영팀의 협업
- CICD
- 소규모 개발팀별 자율적, 독립적 서비스 운영
마이크로소프트에서는 비슷하면서 조금 다르다.
- 소규모 개발팀별 자율적, 독립적 서비스 운영
- 마이크로 서비스
- 서비스를 각각 고유한 논리, 상태 및 데이터가 있는 독립적인 서비스로 기능을 분리
- 컨테이너
- 코드, 해당 의존성 및 런타임은 컨테이너 이미지라는 이진 파일로 패키지
- 최신 디자인
- 클라우드 기반 애플리케이션을 생성하기 위해 널리 허용되는 방법 12단계 애플리케이션
- 코드 베이스, 의존성, 구성, 지원서비스, 빌드/릴리즈/실행, 프로세스, 동시성, 일회성, Dev/Prod 패리티, 로깅, 관리 프로세스
- 서비스 지원
- 데이터 저장소, 메시지 브로커, 모니터링 및 id 서비스와 같은 다양한 보조 리소스 구성
- 자동화
- 스크립트를 활용한 인프라(IaC), CI/CD 배포 자동화
모놀리틱 아키텍쳐
전통적인 아키텍처로, 서비스가 하나의 앱 속에서 동작
기능이 많아지면서 거대해짐
다음의 단점을 가진다.
- 스케일아웃할 때
- 불필요한 서비스까지 복제하여 리소스 낭비
- 종속성 충돌
- 각 기능이 다른 종속성을 가지는 경우 존재
- 모든 종속성을 매 업데이트마다 관리하기 복잡함
- 전체 빌드 배포
- 소스코드가 하나로 이뤄져 작은 수정을 해도 전체를 다시 빌드
마이크로서비스 아키텍쳐
모놀리틱의 대안
애플리케이션의 각 기능을 분리하여 개발 및 관리
다음의 장점을 가진다.
- 빠른 개발
- 개발자는 특정 비즈니스 로직에만 집중하여 빠르게 개발할 수 있음
- 유연한 스케줄링
- 단위 개발, 빌드, 테스트, 배포를 통해 팀 단위로 기간 설정을 자유롭게 할 수 있음
- 효율적 자원 활용
- 필요한 서비스에 대한 리소스만 추가 확장을 통해 확보할 수 있음
- 고효율 저비용의 스케일아웃을 실현할 수 있음
- 복잡한 필요한 종속성 해소
- 서비스 별로 각각의 종속성을 확보시켜 자유로워짐
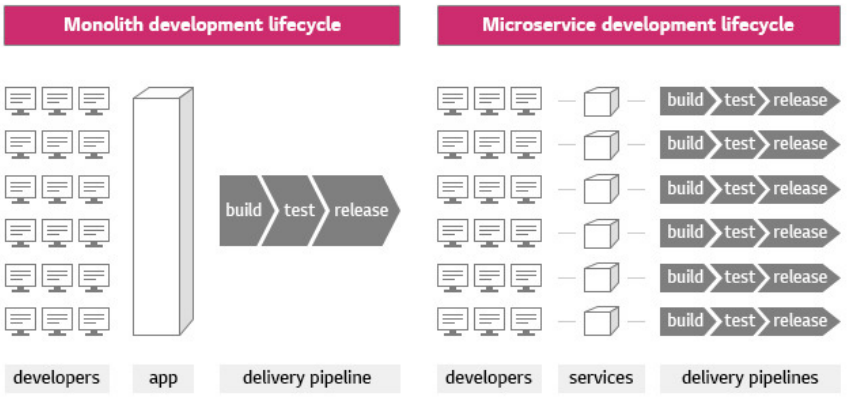
아마존이나 구글은 평균 15분마다 한번씩 배포가 이뤄진다.
이것은 MSA를 통해 가능하다.
- 서비스 별로 각각의 종속성을 확보시켜 자유로워짐
다음의 문제를 가질 수 있다.
- 데이터 정합성 유지
- 트랙잭션 보장, 테스트가 어렵다
이를 해결하기 위해 쿠버네티스가 도입되는 것이다.
데브옵스 모델
개발과 운영의 협업을 통해 전체 라이프사이클을 관리하는 철학 또는 운동
팀 간의 프로세스를 자동화하는 일련의 과정으로도 정의
장점
- 빠른 개발
- 업무 이해도 향상으로 필요한 기능 개발이 빨라짐
- 빠른 배포
- 어려운 구축과 운영을 자동화해 빠른 릴리즈 가능
- 안정성
- 잘 짜여진 자동화와 릴리즈 비용 감소로 인한 협업 강화, 안정성 확보
기본적으로 개발자와 시스템 관리자는 관점이 다른데, 이를 통합시키는 과정이라고 할 수 있다.
- 개발자의 관점
- 기능을 개발하여 사용자 경험 개선
- 운영에 필요한 최적화를 시스템 관리자한테 짬 때림
- 시스템 관리자의 관점
- 배포와 운영의 인프라, 보안 담당
- 앱들 간의 암묵적 상호의존성을 관리하기 힘듬
- 버전 차이로 발생하는 이슈를 빠르게 알기 힘듬
이러한 불편함을 해소하는 것이 데브옵스의 의의
마이크로서비스 성공 사례
넷플릭스
2013년 최초의 마이크로서비스

VM을 통해 수백 개의 서비스 운영
유레카와 같은 자바 진영의 MSA 라이브러리와 툴을 개발함
2000년 당시 문제
- 개발속도 저하
- 데이터센터 비대화
- 서버 점검의 문제
- 서비스 중단
이로부터 넷플릭스는 두 가지 변화를 이끌었다.
- 조직 변화
- 개발팀이 운영하고 책임
- 소규모로 독립적, 자율적 운영
- Build, Run, Support
- 기술 변화
- AWS 기반의 마이크로서비스 운영
- 전세계 무중단 운영
- 유레카 등의 자체적인 기술들 개발하고 오픈소스로 공개
아마존
2000년대 당시 문제
- 확장성 부재
- 컴포넌트 문제로 전체 시스템 장애
- 느린 배포
- 다양성 부족
이를 타파하고 2015년 마이크로서비스 발표
보안-개발-운영자-DB-기획으로 나뉘어지던 팀을 서비스 별로 2피자(8명)팀으로 구성
수천 개의 자율적 데브옵스팀이 존재하고 각 팀이 서비스를 담당함
가상화 개념과 컨테이너
가상화란 무엇일까?
하드웨어에 종속된 리소스를 추상화시켜 유용한 IT 서비스를 만드는 기술
물리적 머신의 기능을 여러 환경에 배포하여 효율적으로 자원 활용
가상화의 역사
IBM에 의해 1860년대부터 시작했으나, 2000년대 초 본격 도입
하이퍼바이저 같은 기술이 개발되어 한 컴퓨터에 여러 명이 액세스 가능해짐
기존에는 하드웨어 벤더 사에 앱 환경이 종속되는 이슈가 존재
하이퍼바이저 정의와 가상화 원리
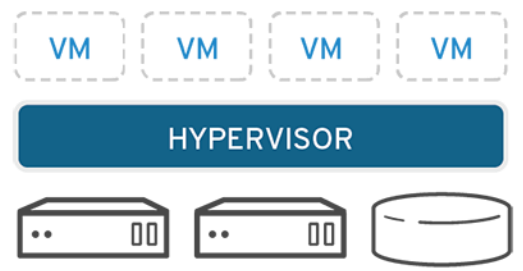
하드웨어를 파티셔닝하고 물리적 리소스를 분리
이 기능을 수행하는 것이 하이퍼바이저
호스트 컴퓨터에서 여러 OS를 동시에 실행하는 논리적 플랫폼
두 종류가 존재한다.
- type 1
- 하드웨어에 직접 설치된 하이퍼바이저
- 모든 게스트 os는 두번째 수준
- wsl2
- type 2
- host os 위에 하이퍼바이저 구동
- 모든 게스트 os는 세번째 수준
- 윈도우에 설치하는 vm들
두 방식이 존재한다.
- 전가상화
- 하드웨어를 전부 가상화
- 게스트 운영체제 변경하지 않음
- 물리적 가상화하는 CPU 기술 필요
- 네이티브 방식
- 반가상화
- 완전 가상화를 하지 않음
- 게스트 운영체제 커널 일부 수정 필요함
- 하이퍼바이저가 모든 제어를 담당하여 높은 성능
VM은 오버헤드가 크다.
하이퍼바이저, OS가 독립적으로 구성되기 때문
컨테이너
가상환경을 통해 마이크로서비스를 격리하는 기본 기술
컨테이너 런타임 프로세스를 활용
하드웨어를 구현하지 않기에 매우 빠름
격리된 프로세스가 host OS의 자원을 활용함
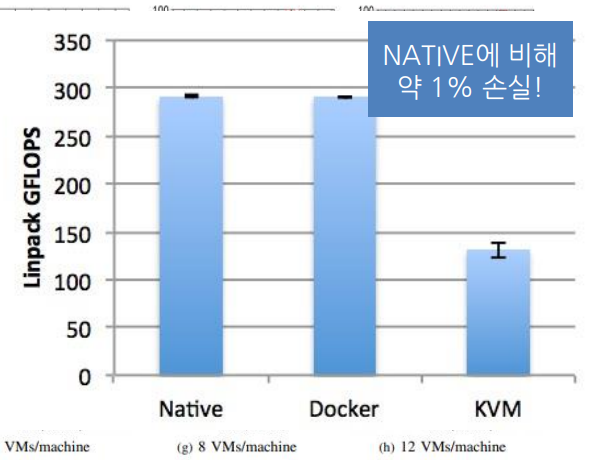
cpu사용량은 native와 비교해서 1퍼센트 정도밖에 차이나지 않는다.
리눅스 네임스페이스
컨테이너를 격리하는 기술
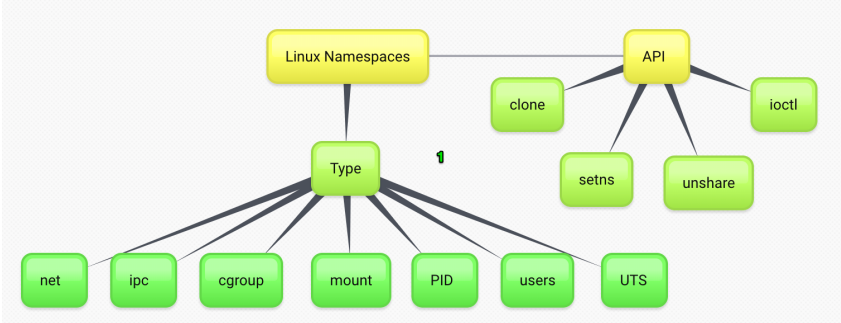
각 프로세스 별로 파일 시스템, 네트워크, 유저 호스트네임 등을 격리할 수 있음
cgroups
프로세스의 리소스를 제한하는 기술
cpu, 메모리 등을 분리
union mount file system
동일 디렉토리에 여러 파일 시스템을 마운트하는 기술
먼저 마운트된 것 위에 추가적 마운트 실행
겹치는 것이 있을 경우 덮어씌워짐
레이어를 분리시키고, 원본을 저장하며 원하는 최종본을 만들 수 있음
도커
컨테이너 기술을 지원하는 프로젝트 중 하나
사실상 표준으로 자리잡음
애플리케이션에 국한되지 않고 의존성, 파일 시스템을 전부 패키징하여 빌드 및 배포를 단순화

아키텍쳐
- docker cli
- 컨테이너를 컨트롤하는 명렁어
- CRI
- OCI에서 제시한 컨테이너 런타임 표준
- ContainerD, CRI-O
- 표준을 만족하는 다른 오픈소스 프로젝트
- runC
- OCI와 호환되는 컨테이너 생성 저수준 런타임
containerD의 역사
2013년 도커의 구성 요소로 출발
2017년 독립형 프로젝트로 분리 후 CNCF에 기부됨
쿠버네티스의 컨테이너 런타임의 표준으로 자리잡음
레지스트리 연동, 컨테이너 관리와 관련된 하위 수준의 작업을 처리
컨테이너의 진화
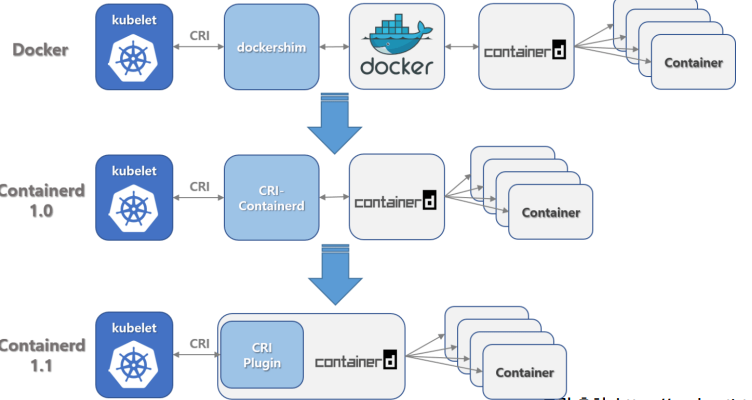
초기 쿠버네티스는 도커를 컨테이너 기술로 활용
당시에는 dockershim이라는 도커의 스펙에 호환되는 프로세스를 사용
그러나 2020년 이후 효율적인 작업을 위해 도커를 분리하고 오픈소스인 containerd를 기반으로 재구축
이후에는 containerd가 자체저긍로 CRI의 모든 역할을 담당
컨테이너 레지스트리
레지스트리는 이미지 저장소
대표적으로 docker hub가 있으며, 클라우드 벤더 별로 또 존재.
harbor를 통해 프라이빗 레지스트리를 구축 가능
도커의 한계
서비스가 커질수록 컨테이너 양이 급격히 증가
관리가 어려워짐
컨테이너 배치, 배포 전략을 복합적으로 다루기 어려움
쿠버네티스

2014년 구글이 공개한 오픈소스
컨테이너 운영 노하우가 담긴 오픈소스
다수의 컨테이너를 운영하는 오케스트레이션 도구
많은 시스템을 통합하고 컨테이너를 제공하기 위한 API 제공
컨테이너 기본 사용 방법
설치는 다양한 자료가 있으니 그걸 참고하도록 한다.
# search app in docker registry
docker search <image>
# show info
docker info
# show info of image
docker inspect <image>
docker run -d --name <name> -p <hostPort>:<containerPort> <image>
dockre exec -ti <name> bash
docker logs <name>
# vice versa
docker cp <path> <container>:<path>
docker stop `docker ps -a -q`
레지스트리
도커 허브를 무료로 사용할 수 있다.
도커 라이프 사이클
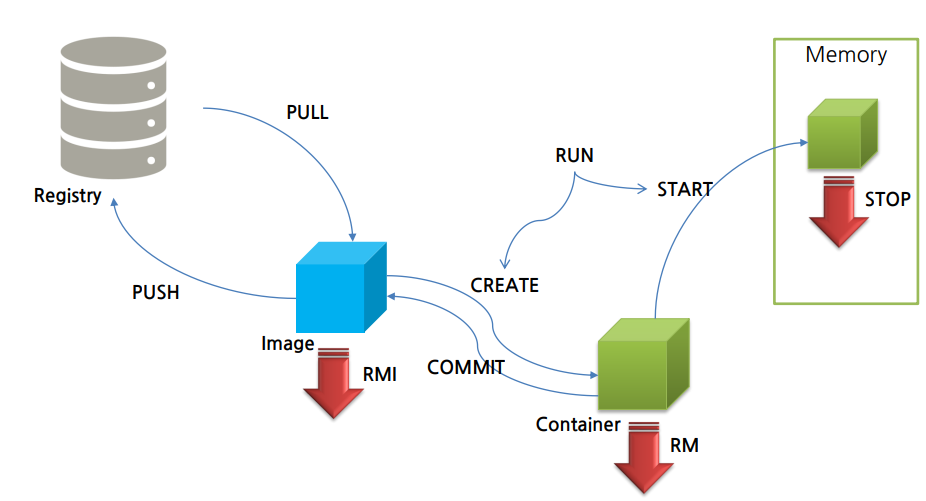
run은 pull, create, start의 작업을 통칭할 수 있다.
대신 start의 명령을 무조건 실행하므로, create의 명령이 실행할 때만 사용하는 것이 권장됨
commit을 통해 컨테이너 자체를 이미지화시킬 수 있음
이미지 레이어
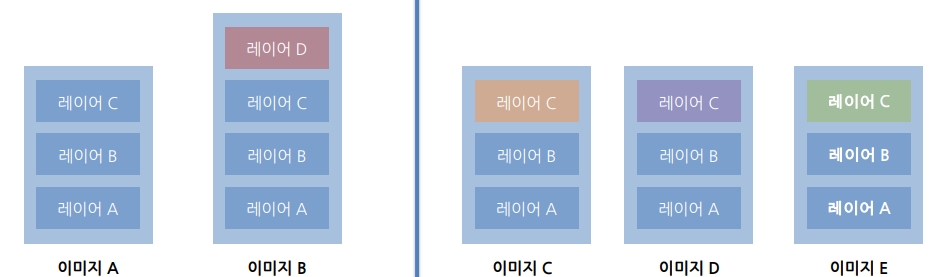
이미지는 레이어로 이뤄져 있으며, 공유할 수 있는 레이어를 서로 공유함
A를 지우더라도, 레이어 abc는 지워지지 않음
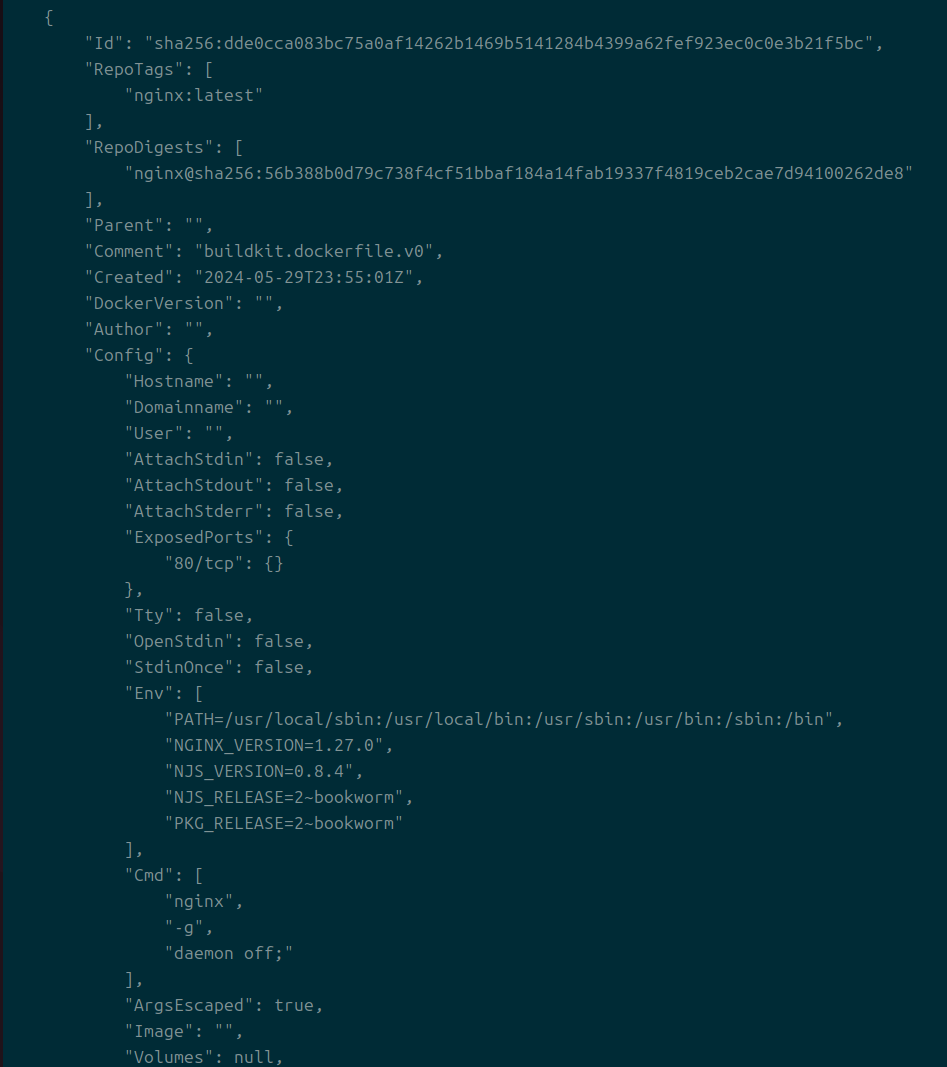
이미지 inspect를 하면 이런 모양을 볼 수 있다.
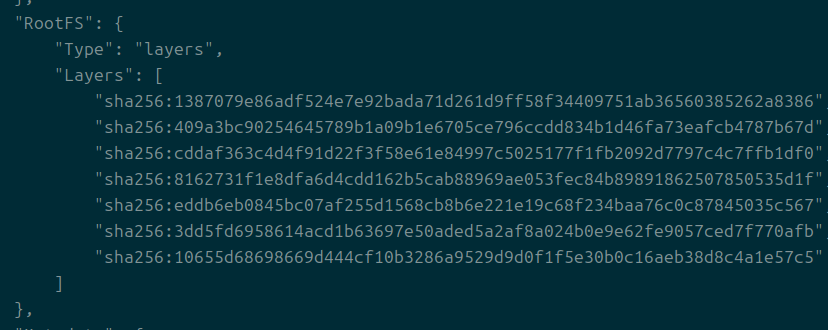
파일시스템에 어떻게 레이어가 돼있는지에 대한 정보도 나온다.
이들에 대한 정보는 image 디렉에 있고, 실질 정보는 overlay2에 있다.
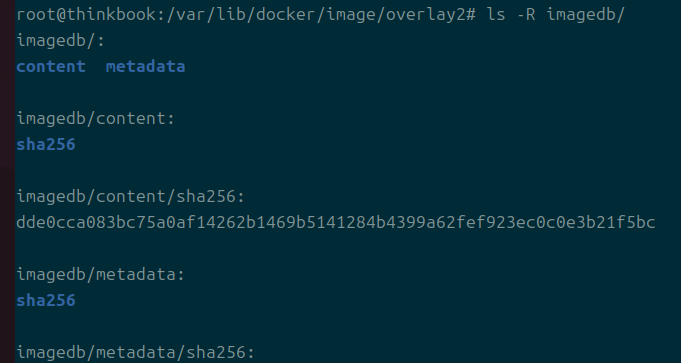
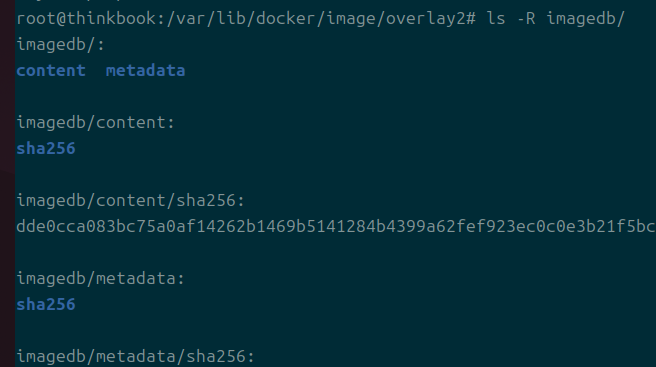
image 디렉 내부에는 imagedb가 있고, 이것이 사용자가 흔히 보는 해시 값을 가진다.
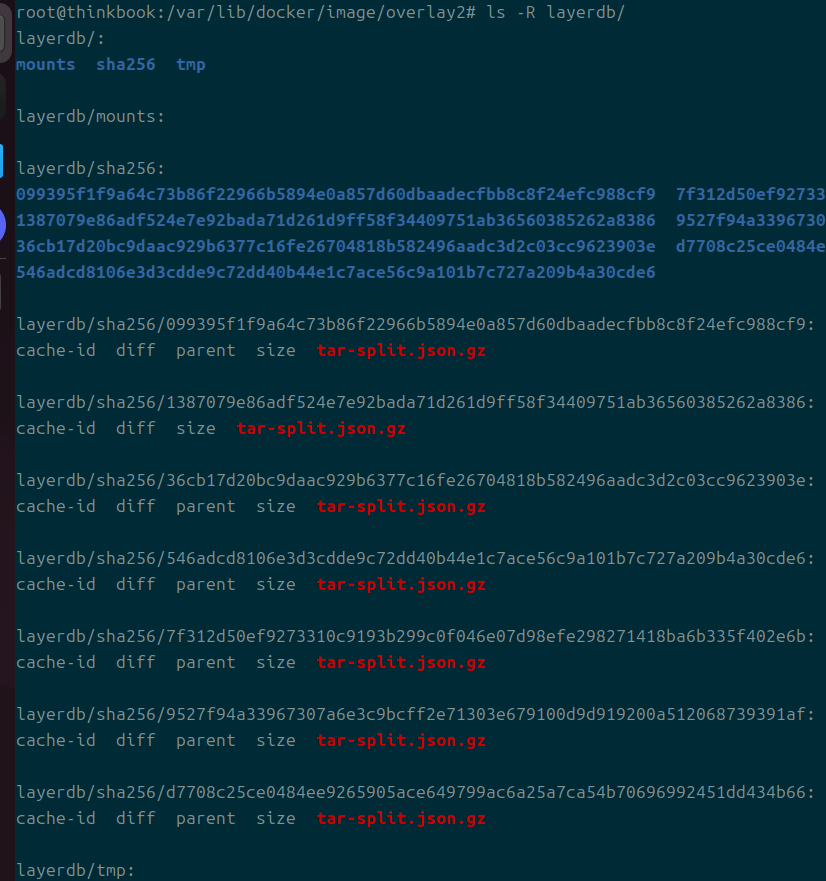
layerdb도 있는데 이건 이미지를 구성하는 레이어에 대한 정보를 담는다.

각 레이어에는 cachedid가 있는데 이 해시 값은 overlay에 들어간 파일과 연관된다.
overlay2에는 실질적인 파일 정보가 들어간다.
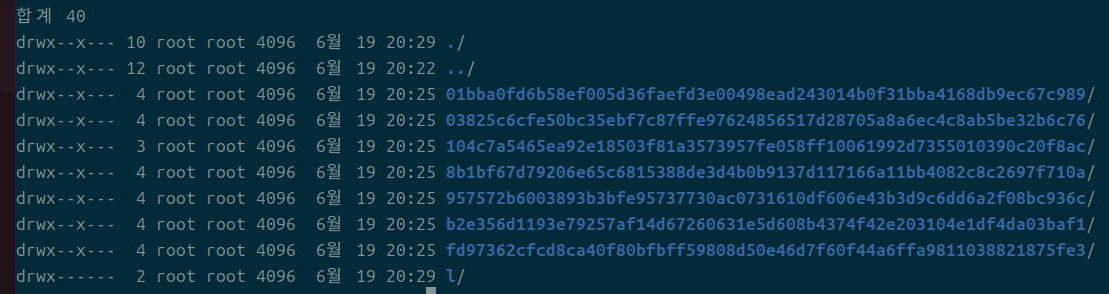
l은 각 레이어의 정보를 가져와서 링킹되어있는 파일이다.
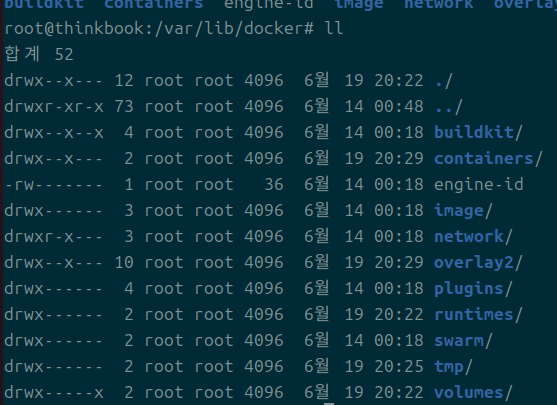
파일상으로 확인할 수 있는 레이어의 구조는 이렇다.
- var/lib/docker
- image
- imagedb
- 이미지당 한 파일
- layerdb가 정보를 가짐
- layerdb
- inspect 시 rootfs로 출력되는 정보
- overlay2가 정보를 가짐
- imagedb
- overlay2
- 이 놈을 따로 가져오면 이미지를 저장할 수 있는 것과 마찬가지
- 컨테이너 내 변경 사항들은 전부 l에 저장됨
- image
이미지 정보는 image, 실질 데이터는 overlay2임을 기억하자.

그래서 데이터도 overlay가 엄청 크다.
모든 레이어의 정보를 저장하기 때문
자잘한 팁
이미지를 inspect해서 열린 포트를 확인할 수 있다
현재 디렉터리를 마운트하고 싶다면 "$PWD" 입력.
마운트 때 :ro를 넣으면 읽기 전용으로 컨테이너에 마운트된다.