4W - 프로메테우스 스택을 통한 EKS 모니터링
개요
이번에는 오픈소스 모니터링 솔루션으로 유명한 프로메테우스와 그라파나를 활용한 모니터링을 진행해본다.
간단하게 PromQL을 작성하고, 이를 통해 대시보드를 만드는 실습을 진행할 것이다.
미리 말하자만, 대시보드 만들다 이슈가 생겨서 더 디테일하게 만드는 건 포기했다.
사전 지식
프로메테우스

프로메테우스는 처음 사운드클라우드에서 만든 모니터링, 알람 시스템이다.
많은 회사들이 프메를 사용하면서 점차 관측 가능성 툴쪽에서는 거의 defacto가 돼버렸다.
프로메테우스는 여러 특징을 가지고 있다.
- 데이터를 Pull 방식으로 수집한다.
- 즉, 중앙 서버는 각지에 설치된 익스포터가 노출하는 경로로 요청을 날려 데이터를 가져온다.
- 중앙 서버가 경로를 노출하여 다른 곳에서 데이터를 Push 해주는 방식과는 다르기에 분산 환경에서 설정 관리에 용이하다.
- 자체로도 지표들을 확인하고 시각화할 수 있으나, 대체로 Grafana를 이용해 시각화 대시보드를 만들어 곁들여 사용한다.
- PromQL이라고 하는 데이터 쿼리 언어를 가지고 있다.
- 이걸 잘 활용하여 유의미한 데이터를 얻어내는 것이 엔지니어링 역량 중 하나라고 할 수 있다.
- 최소한의 기본기를 가지고 있으면 매우 도움이 되며, 관련한 자격증도 있을 정도니 잘 익혀두는 것이 좋다.
- TSDB
- Time Series DataBase, 즉 시계열 데이터를 저장하는 저장소를 가진다.
- 이를 통해 시간을 단위로 지속적으로 수집되는 로그, 메트릭 데이터를 효율적으로 저장한다.
- 이 저장소는 기본적으로 동적 확장이 지원되지 않으므로, Thanos와 같은 외부 스토리지 솔루션을 사용하는 것이 추천된다.
- 동적 재설정
SIGHUP시그널이나,/-/reload엔드포인트로 요청을 날려 변경된 설정을 동적으로 넣어줄 수 있다.
몇 가지 안 좋은 특징도 가지고 있다.
- 수평 확장이 용이하지 않다.
- 프로메테우스 서버가 동적 확장을 잘 지원하지 않는 듯하다.
- federation이라는 기능을 제공하나, 많이 쓰이진 않는 듯.
- 그래서 다른 서드파티 솔루션을 결국 많이 연계하게 된다.
구조

기본적으로 이런 구성으로 되어 있다.
- Prometheus server
- 데이터를 긁어오고 저장한다.
- TSDB를 사용하여 데이터를 효율적으로 저장한다.
- Exporter
- 중앙 서버가 긁어갈 데이터를 노출하는 서버
- 내가 수집하고자 하는 대상에 익스포터를 설치하면 된다.
- 노드의 정보를 얻고 싶으면 Node Exporter, 스프링이면 Spring Exporter.. 이런 식이다.
- Visualization
- 시각화 도구.
- 그라파나를 웹 대시보드로 많이 쓰지만 다른 클라이언트를 사용할 수도 있고 방식은 다양하다.
- Pushgateway
- Push 형식으로 짧게 실행해 데이터를 가져올 때 사용하는 방식.
- 배치를 통해 간혹 가져와야할 데이터라면 이걸 이용하면 된다.
- Alertmanager
- 알람을 해주는 기능 서버
- 그라파나를 시각화도구로 사용할 경우 그라파나 alert를 사용하기에, 거의 사용하지 않는다.
- Service Discovery
- 중앙 서버에서 데이터를 긁어올 곳을 동적으로 찾는 과정, 행위.
- 일반적으로 중앙 서버에서는 데이터를 어디에서 긁어올지 직접 설정해야 한다.
- 그러나 이 방식은 정적이고 귀찮으므로, 특정 조건을 걸어두어 그 조건에 맞게 긁어올 장소를 탐색하게 하는 기능이다.
데이터 형식
프로메테우스의 데이터 형식이 거의 표준화가 된 지금, 이 형식을 잘 아는 것이 또 하나의 관건이라고 할 수 있겠다.
http_requests_total{method="GET", status="200"} 100 @ 1609746000.0
http_requests_total{method="GET", status="200", region="us-east-1"} 50 @ 1609746000.0
http_requests_total{method="POST", status="200"} 80 @ 1609746000.0
이게 프로메테우스 서버에 저장되는 데이터의 예시이다.

실제로 익스포터에서 데이터를 긁어올 때는 이런 식으로 타임스탬프가 빠져있는데, 프로메테우스 서버가 데이터를 긁어오는 시점에 타임스탬프가 지정되기 때문이다.
메트릭 이름 {라벨1="ㅇㅇ", 라벨2 = "ㅇㄹㅇㄹ"} 값 @ 타임스탬프
단순하게 보면 key value가 메트릭이름:값인 거고, 거기에 특정 시간이 붙어있는 형태이다.
라벨은 해당 메트릭을 쉽게 분류하고 필터링하기 위해 붙는 값이다.
http_requests_total이란 메트릭을 여러 개 수집하는데, 이때 어떤 것은 POST 데이터만 모은 놈일 수도 있고 어떤 놈은 status가 200인 놈들만 모았을 수도 있다.
이런 것들을 라벨로서 구체적으로 특정할 수 있게 해주는 것이다.
메트릭 이름을 나누어 표현하지 않고 같은 이름으로 표현하는 것인가?
- 다채롭고 유연하게 쿼리를 하고 유의미한 데이터를 뽑아내는데 도움이 된다.
- 유지보수와 확장성에 용이하다.
- 메트릭 이름이 많아지면 메트릭 자체가 늘어나고, 그만큼 부하가 커진다고 한다(이건 잘 모르겠다).
데이터 유형
일단 예시의 데이터는 Counter, 사진의 데이터는 Histogram인데, 이건 유형을 말한다.
프로메테우스에서 정의되는 지표에는 아래 4가지 유형이 존재한다.
Counter
계속 누적되면서 카운팅되는 데이터.
가령 서버가 받은 http 요청 총량 같은 것은 계속 늘어나기만 하는 데이터이다.
이런 것이 counter에 해당한다.
Gauge
단순 수치 데이터.
counter와 다르게 이 값은 오르내릴 수 있다.
대표적으로는 순간 메모리 사용량 같은 것이 있다.
Histogram
버킷이란 설정 단위를 여러 개 두고, 이로부터 분포를 구한 데이터.
분포뿐 아니라 총합을 나타낼 수도 있다.

가령 http 요청 처리에 걸린 시간을 이렇게 단위 별로 구분한다.
이 단위들이 버킷이 되며, 각 버킷은 개수가 누적된다.
이를 통해 히스토그램을 나타내는 것이다.
Summary
histogram과 유사한데, 조금 더 시간 단위로 요약된 데이터.
가령 전체 http 요청 중에서 중간 정도에 해당하는 값이라던가, 90분위수라던가.
서비스 디스커버리(Service Discovery)
보통은 scrape 설정에 기본적으로 메트릭을 긁어올 경로와 대상을 지정해야 한다.
그러나 서비스가 점점 많아지고 복잡해진다면, 이마저도 어렵고 불편한 과정이 될 것이다.
이를 위해 프로메테우스에서는 특정한 설정을 잡아두면 그 설정에 맞게 알아서 메트릭을 긁어올 대상을 물색하는, 서비스 탐색 기능을 지원한다.[1]
기본적으로는 두 가지 형태의 디스커버리가 있다.
- File SD
- 파일의 내용을 긁어온다.
- 파일의 변경 사항(inotify)에 즉각적으로 반응
- yaml, json 형식 가능
- 로컬 환경의 데이터만 가능
- HTTP SD
- HTTP 통신을 통해 메트릭을 긁어온다.
- refresh 간격에 따라 탐색 진행
- json 형식
기본적인 이 두 방식을 기반으로, 다양한 시스템으로부터 데이터를 편하게 받을 수 있도록 여러 세부적인 설정을 지원하고 있다.

이런 식으로 여러 가지 대상이 가능하다.[2]
scrape 부분에 이 설정을 넣어주면 된다.
scrape_configs:
- job_name: "kubernetes-apiservers"
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
# insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
- job_name: "kubernetes-cadvisor"
kubernetes_sd_configs:
- role: node
scheme: https
metrics_path: /metrics/cadvisor
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
내가 좋아하는 쿠버네티스 관련 설정만 잠시 보자.
쿠버네티스 관련해서는 크게 아래 타입을 지정하여 탐색을 할 수 있다.
- node
- service
- pod
- enpoints
- enpoinslice
- ingress
각각은 메타 라벨을 가지고 있는데, 이들을 relabel_configs.source_labels에 넣고, 매칭되는 값들을 대상으로 삼는다.
위의 예시에서는 endpoints 중 default 네임스페이스에 위치한 kubernetes 서비스의 https 엔드포인트를 대상으로 삼는 것이다.
이렇게 설정하면 해당 경로를 통해 http 요청을 날리고 /metrics에 경로로 노출된 값을 읽어오게 된다.
두번째 예시에서는 메트릭 경로까지 커스텀하는 모습이 보이며, action이 labelmap인데, 이것은 매칭되는 이름들을 다른 이름으로 변경시킬 때 쓴다.
relabel_configs에서 액션에 따라 설정이 달라진다는 것을 참고하자.
PromQL
그렇게 수집된 데이터를 효과적으로 쿼리할 때는 Prometheus Query Language를 사용한다.
SQL처럼 엄청 복잡한 것은 아니고, 조회하는 것에만 특화된 언어라고 보면 되겠다.
기본적으로 차원에 따라 쿼리는 두 가지 유형을 가진다.
일단 하나의 메트릭을 스칼라(보통 샘플이라 한다)라고 쳤을 때,
Instant Query는 한 타임의 메트릭(인스턴트 벡터)들을 쿼리하는 것을 말하며, 기본적인 사용방법이다.
Range Query는 단위 시간 내의 메트릭을 쿼리하는 것을 말한다.
각 행이 시간 단위로 쪼개진 행렬이라 봐도 되지 않을까 싶었는데, 항상 같은 수의 샘플이 들어온다는 보장이 없다.
선형대수적 연산도 불가하기에 그냥 시계열 집합으로서 range vector로 표현하는 듯하다.
instant vector
http_requests_total{job="prometheus",group="canary", env!~"staging|testing"}
기본적으로 쿼리할 때는 이런 식으로 한다.
어떤 메트릭을 잡고, 그 뒤에는 {}을 이용해 라벨 필터링을 건다.
{job=~".*"} # Bad!
참고로 이런 식으로 빈 문자열이 들어가도록 잡을 수는 없다.
최소한 하나의 문자라도 들어가게 +라도 넣어야 한다.
{__name__=~"job:.*"}
메트릭 이름은 __name__이란 예약어를 가지고 있어 이를 활용할 수 있다.
range vector
http_requests_total{job="prometheus"}[5m]
인스턴트 벡터에서 기간을 잡으면 range 벡터가 된다.
이때는 []를 이용해 기간을 넣어주면 된다.
이건 현재 시점으로부터 5분전까지의 데이터를 모아서 출력한다.
그라파나

그라파나는 오픈소스로 개발이 진행되는 멀티 플랫폼 분석, 시각화 웹 어플리케이션이다.
Grafana Labs에서 개발을 진행하고 있으며, 이 제품이 해당 기업의 주력 기술이다.
이 기업에서는 그라파나를 주축으로 한 그라파나 생태계를 만들고 있다.
시계열 데이터를 시각화하는데 특히 탁월하며, Prometheus 와 궁합이 좋다.
최근에는 로그 데이터를 수집하기 위해 Loki를 만들어서 함께 운영하고 있다.
이밖에도 관측 가능성으로서 정의되는 트레이스, 로그 등의 유형도 통합적으로 제공하기 위해 Mimir, Tempo까지 함께 운영하고 있다.
이들을 합쳐서 LGTM(Loki, Grafana, Tempo, Mimir) 라고 부르고 있다.
Kube-State-Metrics
Kube-State-Metrics는 kube-apiserver로부터 클러스터의 정보들을 가져와 상태를 메트릭으로 표시해주는 서비스이다.
관련한 메트릭들을 모아 /metrics 경로로 프로메테우스 형식으로 노출하고 있기에 이를 활용해 쿼리를 만들 수 있다.
이걸 활용하면 한 대시보드로 클러스터에 배포된 디플로이먼트 개수, 상태 등도 알 수 있게 되므로 유용하다.
프로메테우스 오퍼레이터
쿠버네티스 환경에서 프로메테우스를 더 쉽게 사용할 수 있도록 도와주는 오퍼레이터로, 프로메테우스와 관련 컴포넌트, 그라파나를 한꺼번에 설치하여 운영할 수 있다.

프로메테우스의 각 컴포넌트들을 CRD로 만들어 조금 더 편하게 관리가 가능하다.
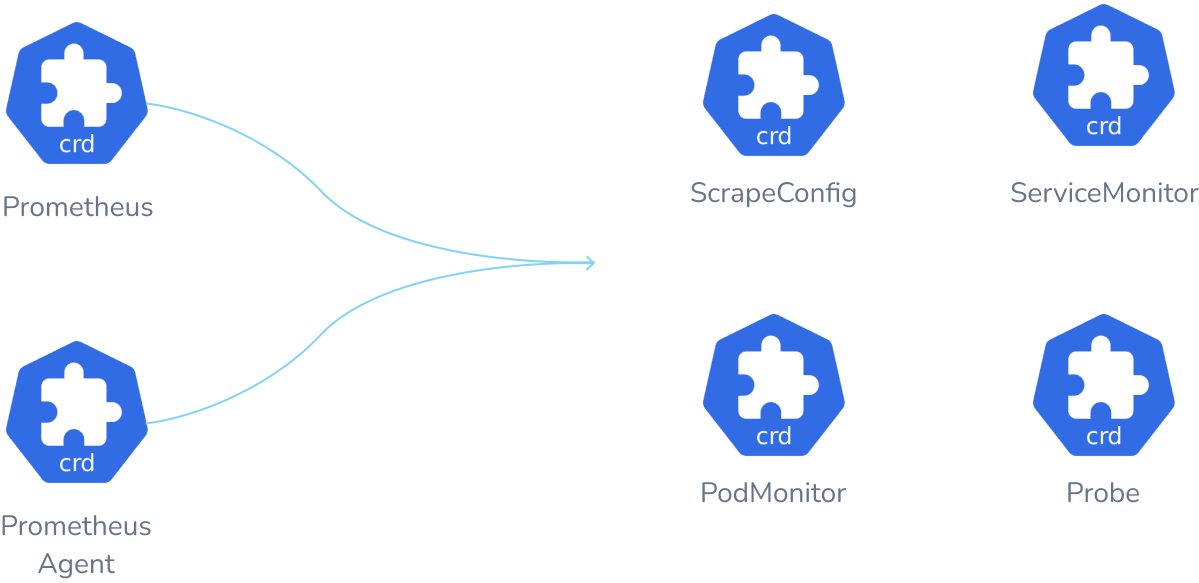
이들은 각각의 컴포넌트에 매칭되는 요소들이거나, config 파일의 한 요소를 대표한다.[3]
kind: Service
apiVersion: v1
metadata:
name: example-app
labels:
app: example-app
spec:
selector:
app: example-app
ports:
- name: web
port: 8080
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
labels:
team: frontend
spec:
selector:
matchLabels:
app: example-app
endpoints:
- port: web
가령 ServiceMonitor의 경우 이런 식으로 작성하는데, 이 오브젝트가 만들어지면 프로메테우스 오퍼레이터가 이를 감지하고 config파일을 동적으로 수정한다.
이를 통해 프로메테우스는 서비스 디스커버리 타겟으로 해당 서비스를 긁어올 수 있도록 만든다.
(서비스를 긁어온다는 것은, 서비스의 백엔드 대상인 엔드포인트슬라이스를 통해 해당 파드들의 메트릭을 긁어온다는 말이다.)
실습 진행
프로메테우스 스택
여기에 기본 스택 헬름을 활용할 것이다.[4]
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm show values prometheus-community/kube-prometheus-stack >> prom-stack-helm.yaml
아래 명령어로 values.yaml 파일을 열었는데, 5000줄이다..
어떤 리소스들이 있는지 조금은 알고 싶어서 직접 줄들을 지워가며 살펴봤다.
해당 yaml 파일에 대한 내용은 생략한다.
아래에서 테라폼으로 세팅할 때 내용을 담을 것이다.
# 배포
helm install prometheus-stack prometheus-community/kube-prometheus-stack --version 69.3.1 \
-f prom-stack-helm.yaml --create-namespace --namespace monitoring
helm을 통해 그냥 설치할 때는 이런 식으로 해준다.
그라파나의 기본 계정은 admin, prom-operator로 되어있을 것이다.
테라폼 설정
resource "helm_release" "prometheus-stack" {
name = "prometheus-stack"
repository = "https://prometheus-community.github.io/helm-charts"
chart = "kube-prometheus-stack"
version = "69.3.1"
create_namespace = true
namespace = "monitoring"
values = [
<<-EOF
defaultRules:
create: true
grafana:
enabled: true
defaultDashboardsTimezone: Asia/Seoul
adminUser: admin
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/certificate-arn : "${data.aws_acm_certificate.domain.arn}"
alb.ingress.kubernetes.io/group.name : aews
# alb.ingress.kubernetes.io/listen-ports : "[{\"HTTPS\":443}, {\"HTTP\":80}]"
alb.ingress.kubernetes.io/listen-ports : '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-name : "${local.cluster_name}-ingress-alb"
alb.ingress.kubernetes.io/scheme : "internet-facing"
alb.ingress.kubernetes.io/ssl-redirect : "443"
alb.ingress.kubernetes.io/success-codes : "200-399"
alb.ingress.kubernetes.io/target-type : "ip"
hosts:
- "grafana.${local.domain_name}"
path: /
persistence:
enabled: true
type: sts
storageClassName: "ebs-csi-default-sc"
accessModes:
- ReadWriteOnce
size: 20Gi
kubernetesServiceMonitors:
enabled: true
coreDns:
enabled: true
service:
enabled: true
port: 9153
targetPort: 9153
ipDualStack:
enabled: false
ipFamilies: ["IPv6", "IPv4"]
ipFamilyPolicy: "PreferDualStack"
kube-state-metrics:
namespaceOverride: ""
rbac:
create: true
releaseLabel: true
prometheus:
monitor:
enabled: true
selfMonitor:
enabled: false
kubeStateMetrics:
enabled: true
prometheus:
enabled: true
agentMode: false
ingress:
enabled: true
annotations:
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/certificate-arn : "${data.aws_acm_certificate.domain.arn}"
alb.ingress.kubernetes.io/group.name : aews
alb.ingress.kubernetes.io/listen-ports : '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-name : "${local.cluster_name}-ingress-alb"
alb.ingress.kubernetes.io/scheme : "internet-facing"
alb.ingress.kubernetes.io/ssl-redirect : "443"
alb.ingress.kubernetes.io/success-codes : "200-399"
alb.ingress.kubernetes.io/target-type : "ip"
hosts:
- "prometheus.${local.domain_name}"
paths:
- /*
route:
main:
enabled: false
ingressPerReplica:
enabled: false
prometheusSpec:
persistentVolumeClaimRetentionPolicy:
whenDeleted: Delete
whenScaled: Retain
scrapeInterval: "15s"
evaluationInterval: "15s"
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "5GiB"
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: ebs-csi-default-sc
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 20Gi
nodeExporter:
enabled: true
operatingSystems:
linux:
enabled: true
forceDeployDashboards: false
kubeApiServer:
enabled: false
kubelet:
enabled: false
kubeControllerManager:
enabled: false
kubeDns:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
kubeProxy:
enabled: true
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
alertmanager:
enabled: false
windowsMonitoring:
enabled: false
EOF
]
depends_on = [
helm_release.lbc,
helm_release.external_dns
]
}
테라폼에서는 이렇게 세팅해주었다.
yaml 파일이 실습에서 제공해준 것보다 조금 더 길어졌는데, 여러 세팅값을 보면서 그래도 내가 인지하면 좋겠다 싶은 것들을 남겨두었다.
실질적으로 수정을 하진 않았고 그냥 기본값이라 없어도 상관없는 값들도 많다.
기본 확인

왜인지 잘은 모르겠는데, 그라파나는 path에 /만 넣어도 되는 반면 프로메테우스는 /*을 무조건 넣어야만 했다.
그래야 이렇게 설정이 된다.
kubectl get crd | grep monitoring
기본 확인은 대충 건너뛰고, 새로 생긴 CRD들만 보자.

이 CRD들을 통해 각종 프로메테우스에서 설정해야 하는 요소들을 재배포 없이 할 수 있게 된다.
모니터라는 CRD들은 파드와 서비스에 대해 추가적인 메트릭을 제공할 수 있도록 돕는다.

프로메테우스 도메인으로 들어가, status에 runtime information을 보면 스토리지 관련 설정이 제대로 잡힌 것이 보인다.

config 부분을 보면 rule과 scrape 설정이 어떻게 됐는지 볼 수 있다.
rule의 경우 컨피그맵으로 저장돼있다.
커스텀 메트릭 수집
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: aws-node
특정 파드의 메트릭을 수집하고 싶다면 이렇게 파드모니터를 만든다.
이 설정을 통해 프로메테우스의 설정 파일을 수정하지 않아도 알아서 프로메테우스가 해당 메트릭을 찾을 수 있게 된다.

참고로 당연히 대상으로 잡은 VPC CNI 파드는 먼저 메트릭을 노출하고 있는 상태이다.

조금 가디라니 프메 콘솔에서 서비스디스커버리에 방금 만든 녀석이 추가됐다.

타겟으로 잡혀서 헬스 상태도 표시가 되고 있다.

config 파일에서 job으로 이 메트릭을 찾아 보면 sd_config로서 잡히는 것이 확인된다.
경로는 /metric로 잡혀있으니, 여기에서 기본으로 kubeconfig파일을 이용해, kube-system의 파드들을 찾아낸 뒤에 metric이란 경로에 메트릭을 노출하고 있는 파드들의 정보를 긁어모으는 것이다.

이제 관련 메트릭들을 쿼리할 수 있게 됐다!
데몬셋에 대해서는 대체로 이런 식으로 파드 모니터를 써주지만, 다른 워크로드의 경우는 서비스 모니터를 활용하는 것이 더 좋을 수 있다.
왜냐하면 서비스모니터는 해당 서비스의 엔드포인트로 잡힌 대상들을 기준으로 하기 때문에 꺼지고 있거나, 실제 트래픽이 연결되지 않고 있는 파드의 정보를 무시할 수 있기 때문이다.
PromQL 실습
노드 기본
node_cpu_seconds_total{mode="idle"}
노드의 cpu가 사용된 시간을 확인해본다.

노드 별로 두개의 cpu가 있어서 두 개씩 출력되는 게 확인된다.
sum without (cpu) (node_cpu_seconds_total{mode="idle"})

노드 별로만 확인하려면, cpu 라벨을 무시하고 sum을 하면 된다.
node_memory_Active_bytes /1024 /1024

바이트로 보면 불편하니 메가 바이트로 변환하여 현재 메모리 사용량을 보니 300메가 정도를 사용하고 있는 게 보인다.
Kube State Metrics 데이터 쿼리
기본 설치를 할 때 Kube-State-Metrics 역시 설치가 됐기 때문에 이를 활용할 수 있다.
kube_deployment_status_replicas{deployment="coredns"}

이런 식으로, kube_라는 접두사를 붙여 메트릭이 잡히고 각 오브젝트들에 대한 상태를 볼 수 있다.
라벨로 다양한 정보를 담고 있어 자유롭게 필터링이 가능할 것이다.
코어 컴포넌트 - coredns 메트릭 확인 후 external dns 수정
대부분의 쿠버네티스의 코어 컴포넌트들은 자체적으로 /metrics로 메트릭을 노출하고 있기 때문에 이것을 통해 쿼리를 날려볼 수도 있다.
k get servicemonitors.monitoring.coreos.com --all-namespaces

프로메테우스 스택을 배포할 때, 관련한 설정이 있는 것을 확인할 수 있는데 이것을 통해 메트릭이 자동으로 수집되기에 서비스의 이름에는 이렇게 긴 이름이 붙게된다.

어차피 자동완성이 지원되기에 굳이 쿼리를 일일히 명시하지는 않겠다.
신기한 게, AAAA레코드로 요청이 들어오는 것도 보인다.

하도 궁금해서 coredns configmap에 log 기능을 활성화해서 확인해봤다.
coredns는 configmap의 변경을 인식하고 동적으로 이를 반영하기에 바로 로그가 남는 것이 보인다.
AAAA와 A레코드로 질의를 날리는 무언가가 있다는 것을 확인했다.

트래픽 낭비의 주범은 바로 External DNS였읍니다..!
앞으로도 많이 쓸 녀석인데 나중에 이 친구 손 좀 봐줘야겠다.
보다 보니 추가적으로 설정해주면 좋을 게, aws로 가야하는 도메인에 대해서도 일단 cluster.local을 붙여대고 앉아있다.
나중에 mutating webhook policy 써서 쿼리 최적화 해본 다음에 이것까지 설정해서 비교해봐야겠다.

간단하게는 external dns의 dns policy를 clusterfirst가 아니도록 바꿔봤다.

샘플로 externaldns를 사용하는 서비스를 몇번 만들 때 요청량이 증가하는 모습이 보였다.
아마도 alb controller의 요청이 집계된 것 같다.
external dns의 쿼리가 coredns로 가지 않게 하는 것만으로도 어마무시하게 요청량이 줄어든 것이 확인된다.

보다시피 로그로도 이제 coredns로 요청이 가지는 않는 것이 보인다.
관측 가능성을 어떻게 확보하냐에 따라 클러스터를 효율적으로 운영할 수 있는 다양한 방법과 전략을 생각할 수 있게 된다.
그라파나

프로메테우스를 열심히 만진 것은, 그라파나로 예쁘게 시각화하기 위한 도움닫기이다!
그라파나를 보면 왼쪽에 다양한 탭이 있따.
- dashboard - 시각화 템플릿
- explore - promql 등을 활용해 실시간으로 지표 쿼리 날리기
- alerting - 그라파나 alert 기능
- connections - 데이터 소스 설정

스택으로 설치를 했을 때, 기본 데이터 소스로 프로메테우스가 들어가 있는 것을 확인할 수 있다.

또 미리 구성된 대시보드도 많이 제공해주고 있다.

위에서 설정을 바꿔줘서 coredns의 요청이 줄어든 것을 간단하게 확인할 수 있다.
sum(rate(coredns_dns_request_count_total{job=~".*",cluster=~".*",instance=~".*"}[5m])) by (proto) or
sum(rate(coredns_dns_requests_total{job=~".*",cluster=~".*",instance=~".*"}[5m])) by (proto)
해당 그래프는 이렇게 PromQL을 통해 쿼리되어 나오는 데이터이며, 이것이 바로 PromQL을 잘 알아야 하는 이유라고 할 수 있다.
대시보드 가져오기
그라파나에는 여러 사람들이 미리 만들어둔 대시보드를 가져올 수 있다.

대시보드에서 New를 누르고, Import를 누른다.
대시보드는 json 형태로 변환이 가능하기 때문에 json 파일을 올릴 수도 있지만, 그라파나 대시보드 페이지에 이미 공유된 대시보드라면 있는 번호를 이용해서 가져오는 것도 가능하다.

15757 대시보드를 가져와본다.

노드는 3개, 네임스페이스는 5개, 파드는 30개 돌아가고 있다.

상단에 각종 기입칸이 보이는데, 이것들은 대시보드에서 사용할 수 있는 variable이다.
시각화 블록을 만들 때 이걸 활용해 다양하게 시각화하는 것이 또 가능하다.

오잉! 시각화가 제대로 되지 않는 블록이 보인다.

왜 이런 문제가 발생하는지 보려면 결국 쿼리를 만져야 한다.
container_cpu_usage_seconds_total이란 메트릭이 필요한 상황이다.

그러나 프로메테우스에서는 해당 메트릭을 제공하지 않고 있다.
컨테이너 메트릭 정보는 kubelet이 노출하는데, 처음 헬름 설치할 당시 관련 설정을 꺼두었기 때문에 이런 문제가 발생한 것이다.
helm -n monitoring upgrade prometheus-stack prometheus-community/kube-prometheus-stack --reuse-values --set kubelet.enabled=true
기존 설정에서는 kubelet의 데이터를 가져오도록 설정하지 않았으므로, 이를 업데이트 해보자.

이제는 정상적으로 모니터링이 되는 것을 확인할 수 있다.
커스텀 대시보드 - 네임스페이스 대시보드 만들기

스터디 시간에 대시보드를 보면서 네임스페이스 별로 지표를 가져와주는 대시보드가 없으면 내가 만들어야겠다 생각하고 있었는데..
막상 확인해보니 있다..
그런데 내가 생각하는 느낌과 조금 다른 측면도 있다.
그래서 나름의 커스텀 대시보드를 만들어보고자 한다.
무얼 보고 싶은가?
내 목적을 먼저 명확히 한다.
나는 관측가능성을 위한 세팅을 하게 되어 발생하는 리소스를 알고 싶다.
그리고 그것이 전체 클러스터 내에서 얼마나 비중 있는지도 확인하고 싶다.
이를 통해 어떤 툴이 리소스 효율적인지 측정하고 싶다.
다음으로는 룰을 만들어본다.

kube_pod_container_status_waiting_reason 메트릭은 파드가 CrashLoopBackOff, ImagePullError 상태일 때 생긴다.
그래서 해당 쿼리를 규칙으로 잡아본다.

이 메트릭은 해당 이슈가 발생하지 않으면 아예 생성되지 않기에, 일단 데이터가 없을 때 정상이라고 설정했다.
apiVersion: v1
kind: Pod
metadata:
name: centos
spec:
containers:
- name: centos
image: centos
command: ["sh", "-c", "exit 1"]
지속적으로 컨테이너가 종료돼 CrashLoopBackOff가 일어날 파드를 만든다.

크윽..허접한 파드 때문에 경고가 날아온다!
결론
PromQL을 통해 프로메테우스 형식으로 정의된 메트릭들을 효과적으로 쿼리를 수행할 수 있고, 이를 적절하게 시각화하여 필요한 정보를 수집할 수 있다.
이를 위해서 단순 모니터링에 머무르지 않고 시스템이 관측 가능하도록 각종 툴을 설치하고, 설정하는 과정을 운영의 한 요소로서 받아들일 필요가 있다.
위에서는 간단하게 프로메테우스 스택을 설치하는 것만으로 Coredns에 발생하는 불필요한 질의를 확인하고 수정할 수 있었던 것도 이러한 과정이 들어갔기에 가능했다.
아울러, 예의주시가 필요한 상황이 발생할 때 이를 즉각 반응하거나 대처할 수 있도록 적절한 조건을 통해 알람 기능을 넣어 활용할 수 있다.
이러한 설정들은 클러스터의 안정성을 높여 나아가 서비스의 신뢰도를 높이는데도 기여할 수 있을 것이다.
이전 글, 다음 글
다른 글 보기
| 이름 | index | noteType | created |
|---|---|---|---|
| 1W - EKS 설치 및 액세스 엔드포인트 변경 실습 | 1 | published | 2025-02-03 |
| 2W - 테라폼으로 환경 구성 및 VPC 연결 | 2 | published | 2025-02-11 |
| 2W - EKS VPC CNI 분석 | 3 | published | 2025-02-11 |
| 2W - ALB Controller, External DNS | 4 | published | 2025-02-15 |
| 3W - kubestr과 EBS CSI 드라이버 | 5 | published | 2025-02-21 |
| 3W - EFS 드라이버, 인스턴스 스토어 활용 | 6 | published | 2025-02-22 |
| 4W - 번외 AL2023 노드 초기화 커스텀 | 7 | published | 2025-02-25 |
| 4W - EKS 모니터링과 관측 가능성 | 8 | published | 2025-02-28 |
| 4W - 프로메테우스 스택을 통한 EKS 모니터링 | 9 | published | 2025-02-28 |
| 5W - HPA, KEDA를 활용한 파드 오토스케일링 | 10 | published | 2025-03-07 |
| 5W - Karpenter를 활용한 클러스터 오토스케일링 | 11 | published | 2025-03-07 |
| 6W - PKI 구조, CSR 리소스를 통한 api 서버 조회 | 12 | published | 2025-03-15 |
| 6W - api 구조와 보안 1 - 인증 | 13 | published | 2025-03-15 |
| 6W - api 보안 2 - 인가, 어드미션 제어 | 14 | published | 2025-03-16 |
| 6W - EKS 파드에서 AWS 리소스 접근 제어 | 15 | published | 2025-03-16 |
| 6W - EKS api 서버 접근 보안 | 16 | published | 2025-03-16 |
| 7W - 쿠버네티스의 스케줄링, 커스텀 스케줄러 설정 | 17 | published | 2025-03-22 |
| 7W - EKS Fargate | 18 | published | 2025-03-22 |
| 7W - EKS Automode | 19 | published | 2025-03-22 |
| 8W - 아르고 워크플로우 | 20 | published | 2025-03-30 |
| 8W - 아르고 롤아웃 | 21 | published | 2025-03-30 |
| 8W - 아르고 CD | 22 | published | 2025-03-30 |
| 8W - CICD | 23 | published | 2025-03-30 |
| 9W - EKS 업그레이드 | 24 | published | 2025-04-02 |
| 10W - Vault를 활용한 CICD 보안 | 25 | published | 2025-04-16 |
| 11W - EKS에서 FSx, Inferentia 활용하기 | 26 | published | 2025-04-18 |
| 11주차 - EKS에서 FSx, Inferentia 활용하기 | 26 | published | 2025-05-11 |
| 12W - VPC Lattice 기반 gateway api | 27 | published | 2025-04-27 |
관련 문서
| 이름 | noteType | created |
|---|---|---|
| Grafana | knowledge | 2024-06-13 |
| Prometheus | knowledge | 2025-02-26 |
| Prometheus-Adapter | knowledge | 2025-03-04 |
| Prometheus Operator | knowledge | 2025-03-30 |
| E-이스티오 컨트롤 플레인 성능 최적화 | topic/explain | 2025-05-18 |
| E-이스티오 메시 스케일링 | topic/explain | 2025-06-08 |