5W - HPA, KEDA를 활용한 파드 오토스케일링
개요
이번 주차에서는 운영의 탄력성을 부여하는 오토스케일링에 대해 알아본다.
이 문서는 그 중 워크로드 자체에 대한 스케일링 툴들을 중점적으로 알아본다.
스케일링 중 복제본을 늘리는 수평 스케일링을 위주로 정리했다.
이미 존재하는 워크로드의 자원을 확장은 수직 스케일링은 온프레미스 환경 보수가 끝난 뒤에 해보고자 한다.
사전 지식
리소스 확장 전략
운영적 관점에서 스케일링은 어플리케이션의 규모를 키우는 작업이다.
트래픽이 급작스레 몰리거나 많은 시간을 소모하는 작업이 진행될 때, 스토리지나 컴퓨팅 자원이 부족해져 원만한 서비스가 어려워질 수 있다.
이런 경우에 가용자원을 추가적으로 확보하거나 어플리케이션에 자원을 더 할당하는 등의 규모를 키우는 식으로 탄력적으로 대처를 하는 것이 중요하다.
서비스 로직을 개발하는 개발자 입장에서는 로직을 수정하여 기존에 사용하던 리소스를 더 효율적으로 활용할 수 있도록 최적화를 하는 전략을 고민하고 적용하는 식으로 대응할 수 있다.
그리고 운영을 하는 관리자 입장에서는 크게 두 가지 방식으로 리소스를 늘리는 전략을 선택할 수 있다.
- 수직 확장
- 현재 운영 중인 어플리케이션이 할당받은 자원을 늘린다.
- 데이터 정합성이나 상태 유지가 중요한 데이터베이스 등의 프로세스에 대해 적용하기 좋은 전략이다.
- 그러나 실제 어플리케이션 프로세스가 이를 동적으로 처리하거나 인식하지 못할 수 있다.
- 수평 확장
- 어플리케이션의 복제본(레플리카)을 늘려서 같은 기능을 수행하는 워크로드 자체를 늘린다.
- 웹서버와 같이 stateless를 기반으로 동작하는 어플리케이션에 대해서 효과적인 방식이다.
- 클라이언트 세션 유지나 캐시 등 상태 유지에 대한 요구사항이 있을 때 이를 대응하는 추가 고민이 필요하다.
상황에 맞게 각 방식을 적절하게 활용할 수 있겠으나, 이것들은 최소한 이미 자원이 확보된 상태를 전제하고 있다.
(주로 하나의 노드에 여러 어플리케이션을 배포하게 되는 클러스터 운영 관점에서 그렇다는 것이다.)
그러나 아예 클러스터 내에 가용한 자원이 부족한 경우라면, 아예 클러스터의 규모를 확장하는 클러스터 스케일링이 필요하다.
이에 대한 내용은 다음 문서에서 다룬다.
쿠버네티스 생태계에서는 이러한 스케일링이 자동으로 이뤄지도록, 오토스케일링을 지원하는 다양한 툴들이 존재한다.
HPA
Horizontal Pod Autoscaler는 디플로이먼트, 스테이트풀셋 등의 워크로드를 자동으로 스케일링하는데 도움을 주는 오브젝트이다.
관리자가 지정해둔 조건에 따라 레플리카의 개수를 늘리거나 줄이는 동작을 알아서 해주기에 편하게 사용할 수 있다.

HPA는 컨트롤러를 통해 동작한다.
이 컨트롤러는 주기적으로 대상이 된 오브젝트의 상태를 감시한다.
(kube-controller-manager에 --horizontal-pod-autoscaler-sync-period 인자를 수정하여 기간(기본 15초)을 조정할 수 있다.)
그리고 해당 워크로드의 대상이 되는 파드들을 찾아낸 후, 지표를 수집한다.
얻어낸 후에는 지표 계산을 거쳐 필요한 레플리카 수를 구한 뒤에 해당 워크로드에 스케일링 명령을 내린다!
참고로 스케일 명령 자체는 해당 오브젝트가 /scale이라는 api에 요청을 보내는 것을 말한다.
그래서 어떤 커스텀 오브젝트라도 /scale에 대한 서브리소스만 같이 만들어둔다면 똑같이 HPA의 대상으로 삼을 수 있다.
스케일링 알고리즘
그렇다면 레플리카를 몇 개로 늘릴지, 얼마나 스케일링해야 하는지는 어떻게 정하는가?
방식은 간단하다. 일단 현재 메트릭과 희망하는 메트릭을 보고 얼마나의 비율로 값이 다른지를 구한다(분수 부분). 해당 비율은 희망하는 레플리카 개수와 현제 레플리카 개수의 비율과 같으므로 현재 레플리카 개수를 곱하면 늘어나거나, 줄어들어서 맞춰져야 할 레플리카 개수가 나오게 되는 것이다. 물론 레플리카는 정수이므로 올림 처리된다.그런데 여기에서 하나의 의문이 더 발생한다.
그렇다면 현재 메트릭 값이라는 것은 무엇인가?
가령 cpu 사용률이 메트릭이라고 쳐보자.
그렇다면 각 파드의 cpu 사용량을 일단 가져와서, 이를 합하고 현재의 개수로 나눈다(평균 구하기).
그럼 그게 현재 메트릭 값이다!
여기까지만 들으면 알고리즘 자체는 굉장히 쉽다는 것을 알 수 있다.
그러나 실제 작업이 들어갈 때는 몇가지 추가 조건이 붙는다.
- 무시되는 파드
- 일단 fail 상태인 파드와 삭제되는 중인 파드는 계산에서 완전히 제외된다.
- 특수 고려되는 파드
- 준비 상태가 아닌 파드, 메트릭이 수집되지 않고 있는 파드에 대해서는 조금 특별하게 대응한다.
- 시작된지 얼마 안 된 파드, 잠시 준비 상태가 풀린 파드를 그냥 무시하진 않는다는 것이다.
- 상태가 확인되는 파드들만 이용해서 계산을 진행하고 해당 결과를 토대로 이 친구들을 반영한다.
- 준비 상태가 아닌 파드
not yet ready상태를 매길 때가 있다.- 파드가 시작된지 얼마 안 됐다면 준비 상태가 됐더라도, 해당 파드를
not yet ready로 간주한다(--horizontal-pod-autuscaler-initial-readiness-delay인자 기본 30초). - 시작된 지 충분히 시간이 지났는데(
--horizontal-pod-autoscaler-cpu-initialization-period인자 기본 5분) 준비 상태가 풀렸다가 다시 준비상태가 된 지 얼마 안 됐다면, 이때는 바로 ready 상태로 반영한다. - 이런 파드들은 메트릭을 0퍼센트라고 가정하고 계산한다.
- 이 파드들은 조만간 원활하게 더 성능을 발휘할 수 있을 것이라 보고 오버스케일링을 피하기 위한 것이다.
- 메트릭이 수집되고 있지 않는 파드
- 이들에 대해서는 큰 동작이 일어나지 않는 방향으로 계산한다.
- 즉 스케일 다운을 해야 하는 상황이라면 해당 파드가 100퍼센트의 자원을 쓰고 있다고 가정한다.
- 반대로 스케일 아웃을 해야한다면 해당 파드가 0퍼센트를 쓰고 있다고 가정한다.
- 이를 통해 어느 쪽으로든 스케일링이 최대한 덜 일어나도록 만들어버린다.
- (이런 방식 때문에 다른 파드들의 메트릭을 토대로 먼저 결과를 꺼낸 이후에 이런 친구들을 반영한다는 것이다.)
- 준비 상태가 아닌 파드, 메트릭이 수집되지 않고 있는 파드에 대해서는 조금 특별하게 대응한다.
이로 인해 필요해서 늘어났어야 할 파드가 늘어나지 않는다던가 하는 상황은 충분히 나올 수 있다.
HPA는 꽤나 스케일링에 있어 보수적인 전략을 펼친다는 것을 알 수 있다.
그렇기에 HPA를 설정할 때는 가급적이면 넉넉하게 조건을 설정해주는 것이 안정적인 서비스를 구축하는데 도움을 줄 것이다.
추가 고려 사항 - 안정화 윈도우
여기에 HPA는 주기적으로 계산을 하는데 이전 계산 값도 현재 계산에 스케일링에 고려한다!
합산을 한다던가 하는 것은 아니고, 스케일링이 들쑥날쑥 한 기준 시간마다 변동되는 것에 제약을 걸기 위함이다.
윈도우 기간(--horizontal-pod-autoscaler-downscale-stabilization인자로 기본 5분)을 두고 이 기간 내의 시간 동안 가장 큰 값으로만 스케일링하도록 돼있다.
즉, 한번 워크로드의 레플리카가 크게 늘어난 후면 대충 5분간은 다시 떨어지지 않는다는 말이다.
이는 스케일 다운이 최대한 점진적으로, 급격하게 변동하는 메트릭값으로부터 안전하도록 하기 위한 조치다.
이러한 방식을 thrashing, flapping이라고 부른다.
메트릭 수집 경로
HPA는 주기적으로 어디에서 메트릭을 수집해서 계산에 활용할까?
기본적으로는 api 서버에 요청을 보내 메트릭을 가져오는데, 3가지의 api 엔드포인트를 활용한다.
metrics.k8s.io- 이건 메트릭 서버에서 노출해주는 값으로, 간단하게 세팅이 가능하다.
custom.metrics.k8s.io- 위의 메트릭은 cpu, 메모리 사용량만 노출하므로추가적인 메트릭을 기준 삼고 싶을 때 커스텀 메트릭을 등록해서 사용한다.
external.metrics.k8s.io- 여기에 클러스터 외부의 메트릭을 이용하고 싶을 때는 이 api에 메트릭을 등록해서 사용하면 된다.
API Aggregation Layer을 통해 api 서버의 기능을 확장시키는 식으로 구현된다.
k get --raw /apis/metrics.k8s.io
해당 메트릭들이 잘 노출되고 있는지 확인할 때는 이렇게 직접 api 경로를 명시해서 요청을 날려보면 된다.

k top pod를 쓸 때, -v 옵션을 써서 세부 과정을 디버깅해보면 먼저 aggregation layer에서 그룹 디스커버리를 호출하고, 관련 api를 찾아서 요청이 진행되는 것을 확인할 수 있다.

위에처럼 그냥 --raw를 사용하면 이 중간과정없이 바로 해당 메트릭 api로 요청을 쏘는 것을 볼 수 있다.
이와 관련한 두 가지 툴을 추가적으로 알아보자.
Metrics Server
Metrics Server는 kubelet에서 수집할 수 있는 cpu와 메모리 두 가지 컴퓨팅 자원에 대한 메트릭을 수집할 수 있도록 도와주는 툴이다.
이 친구를 이용하면 kubectl top pod|node를 통해 간단하게 메트릭을 확인하는 게 가능핟.
대체로 메트릭을 측정하는 프로세스들은 많은 리소스를 차지하기도 하나, 이 친구는 목표가 딱 명확해서 최대한 효율적으로 짜여졌다.
구조
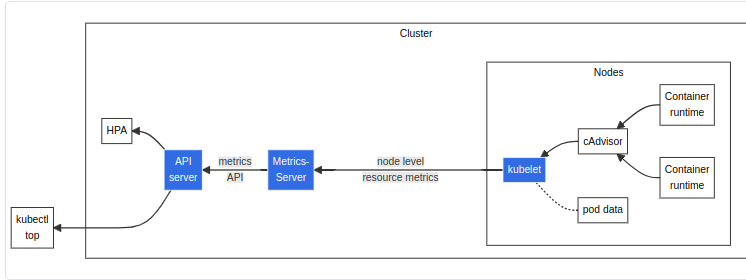
사용자 입장에서 흐름도를 보겠다.
- 사용자가 top 명령어 등으로 메트릭 조회를 시전!
- kube-apiserver가 요청을 받고 metric api 호출!
- 이를 받는 metric server가 노드의 kubelet의 노출된 포트로 정보를 수집!
- kubelet은 메트릭을 수집할 수 있는 컨테이너 런타임으로 동작해야 가능할 것이다.
즉, 메트릭 자체는 kubelet이 통계나 정보를 내주는 것이고, 이를 사용자가 볼 수 있도록 메트릭 서버가 api server에 경로를 노출해주는 것이다.
요구사항
- kube-apiserver에 API Aggregation Layer가 활성화돼야 한다.
- 노드에서는 웹훅 인가(apiserver 인자
--authorization-mode에 Node)가 돼야 한다. - kubelet의 인증서가 클러스터 CA에 의해 서명돼있어야 한다.
- 아니면
--kubelet-insecure-tls인자를 메트릭 서버에 써넣어야 한다.
- 아니면
- 컨테이너 런타임이 메트릭 관련 RPC를 구현하거나, cAdvisor[1]의 지원을 받아야 한다.
- cAdvisor는 kubelet에 내부 바이너리로 들어가 있는 간단한 메트릭 수집기라고 보면 된다.
- 네트워크 요구사항
- 컨트롤 플레인에서 메트릭 서버로 통신이 가능해야 한다.
- 메트릭 서버에서 모든 노드의 kubelet으로 통신이 가능해야 한다.
여기 사항들은 기본적인 클러스터 구성을 했다면 이미 다 충족이 돼있다.
Prom Adaptor
프로메테우스에서 제공하는 메트릭 서버 확장을 위한 어댑터.
메트릭하면? 유용한 게 또 역시 또 프메다!
프로메테우스 서버에서 데이터를 가져오고, 이를 metric api로 노출한다.
결과적으로 프로메테우스의 데이터들을 커스텀 api로 등록하여 HPA에 활용할 수 있게 된다.
기본 메트릭 api에서는 노출하는 메트릭이 cpu, 메모리밖에 없기 때문에 이를 통해 메트릭을 확장하는 것이 매우 유용하다.
구조
프로메테우스 어댑터가 하는 일에 집중해서 보자. 어떤 식으로든, 프로메테우스는 각종 메트릭을 수집하고 쿼리를 할 수 있게 노출하고 있다. 이때 어댑터가 프로메테우스 서버에 접속해 쿼리를 통해 메트릭을 긁어온다. 이제 이 어댑터는 데이터를 뿌릴 준비가 된 것이다. HPA는 계산에 사용할 메트릭을 kube-apiserver의 메트릭 경로를 이용할 텐데, API Aggregation Layer를 이용해 저 메트릭들이 api 서버의 특정 경로를 통해 노출되도록 만드는 것이다. 그리고 HPA에서 이를 가져오도록 설정만 하면, 해당 메트릭을 기준으로 스케일링이 가능해진다! ### ConfigMap 작성법 > [!warning] 꺽쇠기호 표기에 대해 >  > 아래의 예제 코드들에는 원래 꺽쇠 기호가 들어가 있다. > 그러나 현재 내 블로그를 웹사이트 정적 파일로 변환하는 플러그인에서 해당 기호를 템플릿 엔진의 변수로 인식하여 에러가 발생하고 있다. > 그래서 당장은 어쩔 수 없이 예제 코드에서 꺽쇠 기호 표기를 생략하고, `// //`와 같은 식으로 변경하여 코드를 담는다.설정법을 실습 부분에서 정리하기에 길어질 것 같아 여기에 정리했다.
rules:
- seriesQuery: '{__name__=~"^container_.*",container!="POD",namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "^container_(.*)_seconds_total$"
as: "$1_per_second"
metricsQuery: "sum(rate(//.Series//{//.LabelMatchers//,container!="POD"}[2m])) by (//.GroupBy//)"
아무 데이터나 죄다 긁어오지 않고, 특정 룰에 기반해 필요한 데이터만 긁어오도록 할 수 있다.
본격적으로 이걸 어떻게 작성해야 하는지 보자.[2]
위의 설정은 총 4가지 섹션으로 구분된다.
Discovery
이 룰에 매칭돼야 하는 모든 프로메테우스 메트릭을 탐색하는 단계이다.
seriesQuery: '{__name__=~"^container_.*_total",container!="POD",namespace!="",pod!=""}'
seriesFilters:
- isNot: "^container_.*_seconds_total"
---
seriesQuery: 'http_requests_total{kubernetes_namespace!="",kubernetes_pod_name!=""}'
seriesQuery 필드를 통해 어떤 메트릭을 불러올지를 먼저 결정한다.
여기는 PromQL 작성하듯이 작성해주면 된다.
이때 조금 더 세부적으로 필터를 걸 때 seriesFilters를 이용해 is, isNot 필드를 넣어줄 수도 있다.
Association
resources:
template: "kube_//.Group//_//.Resource//"
---
resources:
overrides:
microservice: {group: "apps", resource: "deployment"}
불러온 메트릭이 쿠버네티스의 어떤 리소스에 매칭되는지 지정하는 단계로, resource 필드를 이용한다.
이걸 지정하기에 최종 api 조회를 할 때 상세 경로를 통해 원하는 리소스만 매칭하여 조회할 수 있게 된다.
가령 /apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/test/어떤 메트릭 이런 식으로 특정 네임스페이스의 특정 파드 메트릭을 조회할 때 활용할 수 있다는 말이다.
resources:
overrides:
service:
resource: service
여기에서 매칭하는 것은 메트릭의 라벨로, 메트릭 라벨에 service라는 것이 있고 이것에 쿠버 서비스와 같은 값이라면, 이런 식으로 작성하면 된다.
즉 메트릭 라벨과 쿠버 리소스를 매칭시키는 단계라고 보면 되겠다.
보통은 이렇게 overides를 이용하면 된다.
template 필드를 활용해서 // //를 쓰는 특이한 문법이 보이는데, 이것은 Go 템플릿으로 매칭을 시키는 방식이다.
//.Group//으로 apiGroup, //.Resource//로 리소스 이름을 매칭시킬 수 있다.
그래서 위의 예시의 경우 "kube_v1_pod"라는 메트릭 라벨이 있었다면 이것은 파드와 매칭이 되었을 것이다.
Naming
name:
matches: "^(.*)_total$"
as: "${1}_per_second"
해당 룰이 커스텀 메트릭 api로서 어떤 이름을 가질 것인지 지정하는 단계이다.
먼저 메트릭 이름을 matches를 이용해 매칭을 한다.
여기에서 Regex로 그룹을 지정하고나면, as에서 메트릭 이름으로 위와 같이 활용할 수 있다.
as를 넣지 않을 경우 기본적으로 첫번째로 지정한 Regex 그룹이 이름이 된다.
Querying
metricsQuery: "sum(rate(//.Series//{//.LabelMatchers//,container!="POD"}[2m])) by (//.GroupBy//)"
이 api를 호출했을 때 어떤 식의 쿼리로서 반환돼야 하는지 지정하는 단계이다.
여기에서도 PromQL을 작성하듯이 해주면 되는데, 이번에도 특이한 // //들이 눈에 띈다.
이것들을 통해 특정 경로를 통해 요청이 들어왔을 때 각각 다른 방식으로 응답을 줄 수 있게 된다.
- Series - 그냥 [[#Discovery]] 단계에서 가져온 메트릭 이름이다.
- LabelMatchers - 오브젝트와 매칭되는 라벨 리스트인데, 실질적으로 [[#Association]]에서 본 Group, Resource가 여기에 쓰인다.
- 만약 해당 오브젝트가 네임스페이스 소속이라면 여기에 namespace도 같이 들어간다.
- GroupBy - LabelMatchers의 리스트로 그룹바이하기 위한 라벨 리스트이다.
처음에 너무 생소하게 생겨서 잘 이해못했는데, 그냥 각 단계에서만 사용할 수 있는 특별 템플릿이 있다고만 생각하면 되겠다.
metric{service="dd", pod="tt", namespace="ee", verb="GET"}이런 메트릭이 있다쳐보자.
이때 HPA에서 ee 네임스페이스의 파드들에 대한 메트릭 api를 요청한다고 치면, 각 템플릿 값들은 다음과 같이 매칭된다.
(/apis/custom.metrics.k8s.io/v1beta1/namespaces/ee/pods/*/metric으로 요청이 들어온 상황)
- Series - metric
- LabelMatchers -
- GroubBy - pod
KEDA

KEDA는 쿠버네티스의 이벤트 기반 오토스케일러이다.
HPA는 메트릭을 기반으로 스케일링르 하지만 이 친구는 말 그대로 이벤트를 기반으로 오토스케일링을 할 수 있다.
설계 자체가 HPA처럼 클러스터 내부에서 같이 동작하며 간단하게 구성할 수 있는 방향으로 잡혀있다고 한다.
참고로 실제로 이 친구가 클러스터의 스케일링을 할 때는 사실 HPA를 만들어서 진행한다.
그러니 케다는 기본 오토스케일러가 다양한 이벤트를 기반으로 스케일링을 진행할 수 있도록 기능을 확장하는 도구라고 보면 될 것 같다.

사이트 들어가보면 스케일러로 사용할 수 있는 게 엄청 많다.

케다는 아래의 기능들을 하는데, 이것은 실제로 케다를 배포했을 때 설치되는 워크로드 단위와 정확하게 같다.
- 오토스케일링 에이전트
- 메트릭 제공
- hpa가 메트릭을 수집할 수 있도록, 메트릭을 제공해주는 역할을 한다.
- Admission Webhook
- 자신과 관련된 오브젝트에 대해 잘못된 설정을 미리 체크하고 막아준다.
- validation 체크만 한다.
아키텍쳐
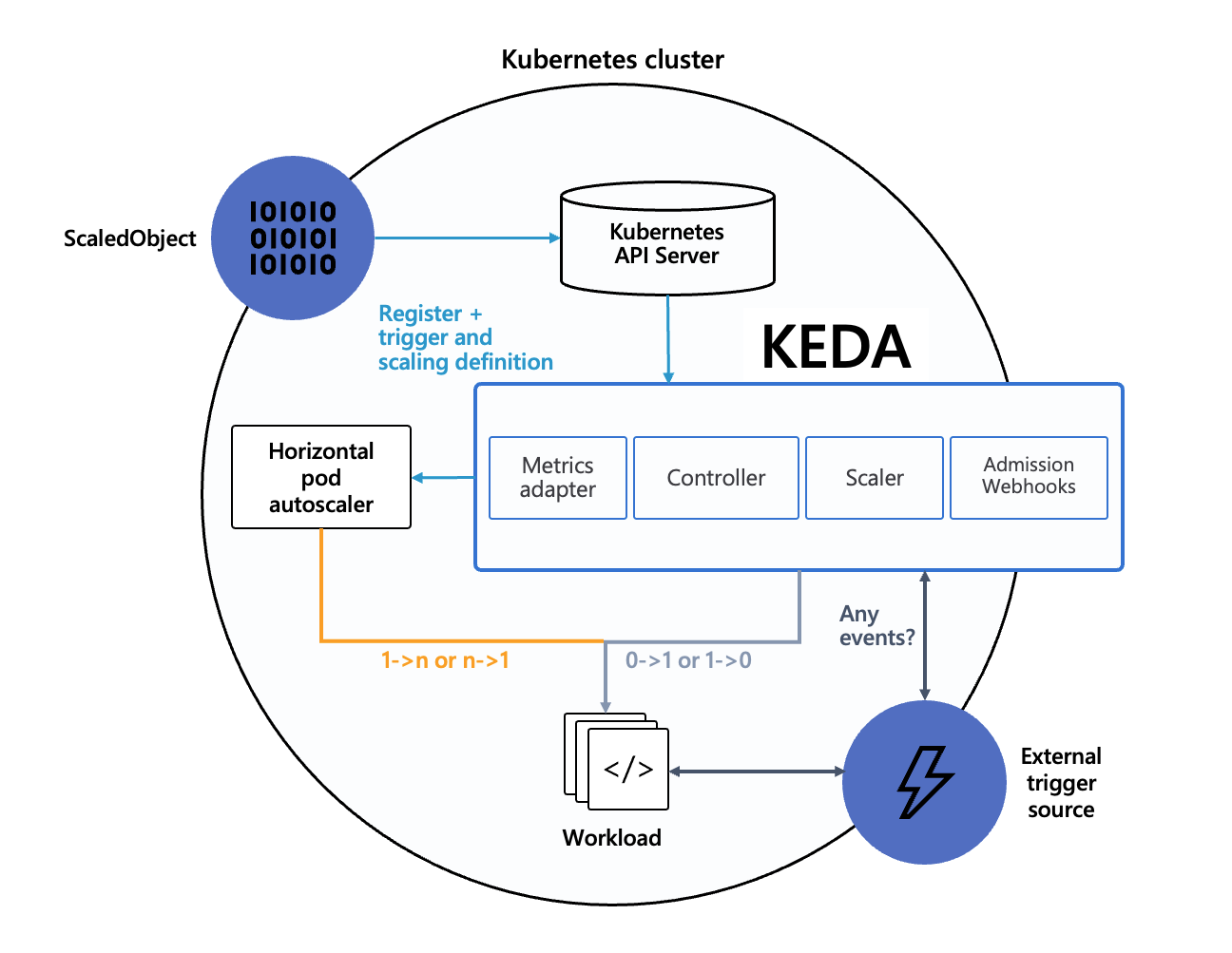
간단하게 보자면.. 케다 오퍼레이터가 있다.
이 놈이 외부 이벤트를 주기적으로 가져오고, 또한 관리자가 요구한 스케일링 양식도 확인한다.
그리고 요건이 충족되면 HPA를 작동시켜서 스케일링을 시키는 것이다.
이때 HPA는 external 메트릭을 기준으로 작동되며, 이 메트릭을 전달하는 책임자가 바로 케다이다.
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1"
이렇게 조회하면 keda가 HPA를 위해 노출해주는 메트릭들을 볼 수 있다.
그러나 keda는 이벤트 기반이다보니 항상 메트릭을 노출해주는 다른 메트릭 api와는 달라서, 실질적으로 메트릭을 조회한다고 해도 사실은 캐시된 값을 보게 될 확률이 높다는 점에 유의하자.
어차피 이벤트마다 메트릭이 새로 튀어나오는 거니 어쩌면 당연할지도 모르겠다.
k get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/{네임스페이스}/{메트릭이름}?labelSelector=scaledobject.keda.sh%2Fname%3D{ScaledObjectName}"
구제적으로 메트릭을 관찰하고 싶을 땐 이런 식으로 보면 된다.
유의 사항 - 레플리카 0과 1의 차이
HPA에서는 최소 레플리카 개수가 0이 될 수 없다([[#스케일링 알고리즘]]을 보면 곱 연산밖에 없어서 사실 당연하다).
그러나 케다는 레플리카를 0으로 만들어 원하는 이벤트에 따라 워크로드를 비활성화시킬 수 있는데, 대신 hpa와의 간극을 명확히 하기 위해 스케일링 프로세스를 두 가지로 구분한다.
- Activation - 0에서 늘리거나, 0으로 줄이는 스케일링 단계를 말한다.
- Scaling - 양수 범위에서 스케일링되는 단계로, HPA가 정상적으로 동작할 수 있는 단계이다.
활성화 단계가 따로 존재하는 이유는 HPA가 레플리카 0에서 동작하지 않기 때문이다.
그래서 이벤트를 이용해 메트릭을 뿌리기만 하고 HPA에게 스케일링을 위임하던 평소 방식과 다르게, 레플리카 0에서 스케일링을 할 때는 케다가 명확하게 레플리카 수를 늘리는 작업을 진행한다.
몇 가지 스케일러의 경우 이것에 대한 커스텀 설정들을 제공한다.
유의사항 - HTTP 요청량 기반 스케일링 불가
어디까지나 keda는 이벤트를 기반으로 하는 것이 주된 목적이다.
그래서 메트릭을 확장해주기도 하지만 한편으로는 동작이 다르다는 것도 감안해야 한다.
그래서 놀랍게도.. http 요청량을 기반으로 스케일링 하는 것이 기본적으로 지원되지 않는다.
(사실 프로메테우스 스케일러를 쓰면 어느 정도 아쉬움을 해소할 수 있다.)
아무튼 이를 위해 추가 애드온을 개발하고 있는데, 아직 베타 단계.[3]
실습 진행
HPA
HPA는 결국 스케일링의 기본이 되는 방식이라 잘 알아두는 것이 좋다.
테라폼 환경 세팅
####################################################
##### metric server
####################################################
resource "aws_eks_addon" "metric_server" {
cluster_name = module.eks.cluster_name
addon_name = "metrics-server"
addon_version = "v0.7.2-eksbuild.2"
resolve_conflicts_on_update = "PRESERVE"
configuration_values = jsonencode({ })
depends_on = [
module.mng_al2023_ondemand
]
}
테라폼에서는 단순히 메트릭 서버 애드온을 추가하였다.
테스트 기본 세팅
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
이걸 기본적인 스케일링 대상으로 삼는다.
이미지 이름만 봐도 알겠지만, 쿠버네티스에서 제공해주는 hpa 샘플용 이미지이다.
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>
http 요청을 보내면 자체적으로 연산을 하면서 cpu를 사용하게 돼있다.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
HPA는 이렇게 만들었다.
잠시 해석하자면, cpu 사용률이 50퍼가 아닐 때 스케일링을 하겠다는 것이다.
위의 샘플은 cpu 요청량이 200m이며, 이것이 사용률을 계산할 때 분모로 들어가게 된다.

가만히 두면 이 상태가 될 것이다.
그라파나 대시보드는 22128을 사용했다.
스케일링 테스트 - 단일 파드
while true; do curl -s 파드; sleep 0.5; done
호스트로 들어가서 파드 IP에 지속적으로 요청을 날려본다.

조금 기다리다보면 이렇게 파드가 하나 늘어나게 되는 것을 확인할 수 있다.

대시보드로도 한번 사용률이 50퍼를 넘겼기 때문에 스케일업이 진행된 것이 확인된다.

그러나 여기에서 유의 깊게 볼 점은 더 이상 스케일링이 되지 않는다는 것이다.
현재 부하를 준 파드에선 요청 리소스(request) 200m의 절반을 넘기는 값으로 cpu 자원을 활용하고 있는 것이 보인다.
그렇지만 HPA는 현재 대상이 된 파드들의 전체 평균을 가지고 계산을 진행하기에, 한 파드의 지표가 아무리 높아도 전체적인 관점에서 사용률이 50퍼를 넘지 않기에 더 이상 스케일링이 되지 않는 것이다.

실제로도 HPA 기준에서는 현재 메트릭값이 35퍼로 잡히고 있다.
조금 더 안정화 윈도우와 동작을 면밀히 살피고자 세부 스펙을 더 정의했다.

생각보다 부하가 덜 발생하는 것 같아서, 다른 터미널을 띄우고 똑같은 명령어를 또 쳐서 부하가 두번 발생하게 만들었더니 최종적으로는 10개까지 레플리카가 늘어났다.

3분을 텀으로 안정화 윈도우를 적용했더니 일단 최대 레플리카였던 10개가 유지됐다.

그 이상을 넘어가자, 한번에 최대로 줄어들 수 있는 개수인 4개씩 줄어들기 시작한 것이 확인된다.
### 커스텀 메트릭 사용하기
```sh
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm show values >> values.yaml
# values.yaml에서 프메 서버 url 설정
helm install my-release prometheus-community/prometheus-adapter
이번에는 Prom-Adapter를 이용해 커스텀 메트릭으로 HPA를 해본다.

values 파일을 받아오는 이유는, 프로메테우스 서버 주소를 명시해줘야 하기 때문이다.

배포가 되면 디플로이먼트를 통해 어댑터 파드가 하나 생긴다.
k get apiservices.apiregistration.k8s.io

또한 apiservice 오브젝트가 하나 생긴 것도 확인할 수 있다.
버전이 앞에 등장하는데, 실제 api를 쓸 때 이 값은 하위 경로로 들어가게 된다.
k get cm prom-adaptor-prometheus-adapter -oyaml

각종 룰들은 컨피그맵으로 생긴다.
이것을 직접 수정해서 가져오는 메트릭들을 조정하는 것도 가능하다.
- seriesQuery: '{__name__=~"container_network_(receive|transmit)_packets_total",namespace!="",pod!=""}'
resources:
overrides:
namespace:
resource: namespace
pod:
resource: pod
name:
matches: ^container_network_(.*)_packets_total$
as: "packets_per_second"
metricsQuery: sum(rate(//.Series//{//.LabelMatchers//}[1m])) by (//.GroupBy//)
파드 단위로 오고가는 패킷을 메트릭으로 삼고자 이렇게 규칙을 작성했다.
k get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/packets_per_second" | jq
커스텀 메트릭이 잘 만들어졌다면 이렇게 요청을 보냈을 때 메트릭이 보여야 한다.

석세스!
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: custom-metric
spec:
minReplicas: 1
maxReplicas: 10
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
metrics:
- type: Pods
pods:
metric:
name: packets_per_second
target:
type: AverageValue
averageValue: 10000m
해당 값을 바로 이용해서 다시 HPA를 만들어본다.

다시 같은 방식으로 부하를 줄 때, 어마무시하게 빠르게 스케일링이 이뤄진다.
기준 값을 작게 설정한 것도 있지만, 스케일링된다고 해서 요청 수가 줄어드는 것도 아니라 평소 값이 크게 작아지지도 않는다.
이번에는 웹 어플리케이션을 켜고, 이걸 토대로 커스텀 메트릭을 지정해보자.
replicaCount: 3
autoscaling:
enabled: false
service:
type: ClusterIP
ingress:
enabled: true
hostname: nginx.zerotay.com
path: /
pathType: Prefix
annotations:
alb.ingress.kubernetes.io/certificate-arn: 당신의 인증서 arn..
alb.ingress.kubernetes.io/group.name: aews
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-name: terraform-eks-ingress-alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/ssl-redirect: "443"
alb.ingress.kubernetes.io/success-codes: 200-399
ingressClassName: "alb"
metrics:
enabled: true
serviceMonitor:
enabled: true
헬름 values는 이렇게 세팅했다.
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
helm install nginx bitnami/nginx --version 19.0.0 -f values.yaml
k get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/nginx_http_requests"
k get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/services/*/nginx_http_requests"
위 헬름에서 서비스 모니터를 설정했기 때문에, 바로 관련 메트릭을 조회해보는 것이 가능하다.
파드를 대상으로 메트릭을 지정할 수도 있으나, 아예 서비스를 대상으로 조회를 하는 편이 조금 더 편리할 것이다.
(근데 사실 메트릭의 근원지가 같아서 결국 다를 건 없다.)
- type: Object
object:
metric:
name: nginx_http_requests
describedObject:
apiVersion: v1
kind: Service
name: nginx
target:
type: Value
value: 10000m
hpa의 메트릭 필드는 이렇게 서비스를 대상으로 지정한다.

해당 값은 counter로, 그냥 total 값이라 줄어들지는 않는다.
아무튼 이렇게 다른 오브젝트의 메트릭을 활용하는 것도 가능하다!
KEDA
테라폼 세팅
resource "helm_release" "keda" {
name = "keda"
repository = "https://kedacore.github.io/charts"
chart = "keda"
version = "2.16.0"
create_namespace = true
namespace = "keda"
values = [
<<-EOF
metricsServer:
useHostNetwork: true
prometheus:
metricServer:
enabled: true
port: 9022
portName: metrics
path: /metrics
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
operator:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
webhooks:
enabled: true
port: 8020
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus webhooks
enabled: true
EOF
]
depends_on = [
helm_release.lbc,
helm_release.external_dns,
helm_release.prometheus-stack
]
}
테스트 - 크론 스케일러
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1" | jq

케다가 설치되면 알아서 externalMetric에 데이터를 노출할 준비를 해준다.
https://github.com/kedacore/keda/blob/main/config/grafana/keda-dashboard.json
케다에서 제공하는 그라파나 대시보드를 활용하여 모니터링을 진행한다.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: php-apache-cron
spec:
minReplicaCount: 0
maxReplicaCount: 5
pollingInterval: 30
cooldownPeriod: 60
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
triggers:
- type: cron
metadata:
timezone: Asia/Seoul
start: "*/10 * * * *"
end: "5,15,25,35,45,55 * * * *"
desiredReplicas: "1"
5분 단위로 1개를 만들었다 말았다 하는 크론 스케일러를 만들었다.
참고로 cooldownPeriod의 기본값이 5분이기 때문에 여기에서 명시적으로 더 작은 값으로 지정했다.

5분을 주기로 스케일링이 동작하는 것이 확인된다.

HPA의 스펙을 보면 이렇게 메트릭에 external이 들어간 것을 확인할 수 있다.
k get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/{네임스페이스}/{메트릭이름}?labelSelector=scaledobject.keda.sh%2Fname%3D{스케일오브젝트}"
이런 식으로 직접적으로 메트릭을 관찰하는 것도 가능한데, 기본적으로 케다는 이벤트 기반으로 메트릭을 내주다보니 직접적으로 메트릭을 확인한다는 것이 조금 이상한 일이기도하다.

만들어진 HPA에서도 이런 이벤트가 계속 발생하나, 실제로 동작은 잘 되고 있다.
결론
서비스의 안정성을 위해 오토스케일링을 통해 자원을 유연하게 관리할 수 있다.
쿠버네티스의 기본 오브젝트인 HPA를 활용하면 cpu, 메모리 사용량을 기반으로 스케일링이 가능하다.
다만 다른 메트릭을 활용해 스케일링을 설정하고 싶다면 커스텀 메트릭을 활용할 필요가 있다.
추가적으로 이벤트 기반 스케일러인 KEDA를 통해 스케일링 기능을 확장하면 훨씬 다양한 방법으로 스케일링 설정을 할 수 있다.
KEDA도 결국 HPA를 통해 스케일링을 지원하기에, 세밀한 설정을 해야 한다면 결국 HPA의 작동원리를 정확하게 이해하는 것이 중요하다.
이전 글, 다음 글
다른 글 보기
| 이름 | index | noteType | created |
|---|---|---|---|
| 1W - EKS 설치 및 액세스 엔드포인트 변경 실습 | 1 | published | 2025-02-03 |
| 2W - 테라폼으로 환경 구성 및 VPC 연결 | 2 | published | 2025-02-11 |
| 2W - EKS VPC CNI 분석 | 3 | published | 2025-02-11 |
| 2W - ALB Controller, External DNS | 4 | published | 2025-02-15 |
| 3W - kubestr과 EBS CSI 드라이버 | 5 | published | 2025-02-21 |
| 3W - EFS 드라이버, 인스턴스 스토어 활용 | 6 | published | 2025-02-22 |
| 4W - 번외 AL2023 노드 초기화 커스텀 | 7 | published | 2025-02-25 |
| 4W - EKS 모니터링과 관측 가능성 | 8 | published | 2025-02-28 |
| 4W - 프로메테우스 스택을 통한 EKS 모니터링 | 9 | published | 2025-02-28 |
| 5W - HPA, KEDA를 활용한 파드 오토스케일링 | 10 | published | 2025-03-07 |
| 5W - Karpenter를 활용한 클러스터 오토스케일링 | 11 | published | 2025-03-07 |
| 6W - PKI 구조, CSR 리소스를 통한 api 서버 조회 | 12 | published | 2025-03-15 |
| 6W - api 구조와 보안 1 - 인증 | 13 | published | 2025-03-15 |
| 6W - api 보안 2 - 인가, 어드미션 제어 | 14 | published | 2025-03-16 |
| 6W - EKS 파드에서 AWS 리소스 접근 제어 | 15 | published | 2025-03-16 |
| 6W - EKS api 서버 접근 보안 | 16 | published | 2025-03-16 |
| 7W - 쿠버네티스의 스케줄링, 커스텀 스케줄러 설정 | 17 | published | 2025-03-22 |
| 7W - EKS Fargate | 18 | published | 2025-03-22 |
| 7W - EKS Automode | 19 | published | 2025-03-22 |
| 8W - 아르고 워크플로우 | 20 | published | 2025-03-30 |
| 8W - 아르고 롤아웃 | 21 | published | 2025-03-30 |
| 8W - 아르고 CD | 22 | published | 2025-03-30 |
| 8W - CICD | 23 | published | 2025-03-30 |
| 9W - EKS 업그레이드 | 24 | published | 2025-04-02 |
| 10W - Vault를 활용한 CICD 보안 | 25 | published | 2025-04-16 |
| 11W - EKS에서 FSx, Inferentia 활용하기 | 26 | published | 2025-04-18 |
| 11주차 - EKS에서 FSx, Inferentia 활용하기 | 26 | published | 2025-05-11 |
| 12W - VPC Lattice 기반 gateway api | 27 | published | 2025-04-27 |
관련 문서
| 이름 | noteType | created |
|---|---|---|
| HPA | knowledge | 2024-12-29 |
| Cluster Autoscaler | knowledge | 2025-03-05 |