5W - Karpenter를 활용한 클러스터 오토스케일링
개요
이번 문서에서는 클러스터 오토스케일링 툴에 대해서 알아본다.
원래는 클러스터 오토스케일러라는 툴을 먼저 활용하려고 했으나, 세팅 이슈로 제대로 동작하지 않아 시간 상 Karpenter만 다룬다.
사전 지식
Cluster Autoscaler
Cluster Autoscaler는 클러스터의 노드가 부족할 때 노드를 자동으로 늘리는 툴이다.
파드를 늘리는 HPA, VPA과는 다르게 노드를 늘려서 추가 자원을 확보한다.
이를 통해 인프라를 프로비저닝하는 환경에 대한 각종 커스텀이 필요하다.
요즘에는 Karpenter를 사용할 수 없는 환경에서만 쓰이는 것 같다.
기본적으로 클러스터 오토스케일러는 현재 클러스터의 상태를 감시한다.
그러다가 스케일을 해야 하는 상황일 경우에 외부 제공자에게 관리를 해야 함을 통지한다.
그러면 이후에 노드를 추가하거나 삭제를 해주는 것은 전적으로 외부 제공자의 책임이 된다.
가령 AWS에서는 오토스케일링그룹을 통해 노드가 추가, 삭제된다.
클러스터 스케일 업
자원 부족으로 인해 파드가 스케줄에 실패했을 때 클러스터 오토스케일러가 동작한다.
즉, 스케줄링이 실패했을 때만 발동한다는 것이다.
이것은 cpu의 사용량을 기반으로 스케일링을 하는 다른 노드 스케일러 솔루션과 차별되는 점이다.
구체적으로는 다음의 과정을 따른다.
--scan-interval(기본 10초)마다 kube-apiserver를 통해schedulable: False상태이면서 이유가unschedulable인 파드의 상태를 관찰한다.- 그러한 파드를 찾으면 노드를 증설하기 위한 시도를 한다.
- 노드들은 노드 그룹으로 묶인 것으로 간주하며, 같은 스펙의 노드를 증설한다.
이 스케일러는 노드를 만들고 노드 오브젝트를 등록하는 작업에 책임을 지지 않는다.
그저 --max-node-provision-time(기본 15분)내에 클라우드 제공자가 적절하게 노드를 붙여주기를 바랄 뿐이다.
이 시간 내에 노드가 등록되지 않으면 노드가 등록되지 않았다고 간주하고 새로 노드를 증설해달라 재요청한다.
클러스터 스케일 다운
자원이 지나치게 남아돌면서 중요도가 적은 파드들이 위치한 노드가 있을 때도 노드를 줄이는 방향으로 동작한다.
이때 어떤 파드가 있는 노드들이 살아남을 수 있을까?
- PDB로 빡센 제한이 걸린 파드
kube-system네임스페이스에서 데몬셋이 아닌 채 노드에 배치된 파드- 디플로이먼트과 같은 관리자가 따로 없는 스탠드 얼론 파드
- 로컬스토리지 종속성이 있는 파드
- hostPath 볼륨, empyDir(메모리 기반 아닌) 볼륨
"cluster-autoscaler.kubernetes.io/safe-to-evict-local-volumes": "volume-1,volume-2,.."어노테이션으로 local PV를 지정한 파드
- 스케줄링 조건에 걸려 다른 곳으로 가기 힘든 파드
"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"어노테이션이 걸린 파드
이런 파드들이 위치한 노드라면 해당 노드는 지워지지 않을 것이다.
아예 특정 노드를 사라지지 않게 하고 싶다면 노드에 "cluster-autoscaler.kubernetes.io/scale-down-disabled": "true" 어노테이션을 걸어준다.
스케일 다운은 아래의 과정을 따른다.
--scan-interval마다 쓸모없는 노드를 탐색한다.- 노드 내의
request / allocatable, 즉 사용량이--scale-down-utilization-threshold(기본 50퍼) 밑인 노드 - 그러면서 살아남을 수 있는 파드가 없는 노드
- 그러면서 스케일 다운 불가 어노테이션이 붙지 않는 노드
- 노드 내의
- 이 노드가 10분 동안 쓸모 없음 상태라면 종료시킨다.
- 그런 노드가 많더라도, 10분마다 하나씩 노드를 종료시키며 스케일 다운이 가능한지는 매번 다시 계산한다.
단점
이 친구는 실상 Karpenter를 쓸 수 없는 환경에서 사용하는 차안 같은 느낌이다.
왜냐하면 아래의 문제점들이 있기 때문이다.
- 직접적으로 노드 생성에 관여하지 않는다.
- 클러스터에서 노드는 제거됐으나, 실제 인스턴스는 살아있다던가 하는 간극이 발생할 수 있다.
- 같은 영역에 노드가 생겨야 스토리지 자원을 쓸 수 있는데 엉뚱한 AZ에 노드가 추가되어 같이 써야 할 자원을 못 쓰는 경우도 생긴다.
- 확장, 축소 정책이 다양하지 않다.
- 노드를 빠르게 줄이기도 어렵고, 스케일 업 시에도 비용 최적화를 고려하기 힘들다.
- 느리다.
- 직접 노드 생성에 관여하지 않으니 홉이 늘어나고, 이 홉에는 자체적으로 스케일링을 관리하는 리소스가 추가적으로 있다보니 실제 클러스터가 확장되는데에는 오랜 시간이 걸린다.
Karpenter
Karpenter 클러스터 오토스케일링에 있어 현재 가장 탁월하다고 평가받는 툴로 노드 관리에 대한 통합 솔루션이다.
AWS에서 개발하고 있는 오픈소스이다.
클러스터에 자원이 필요할 때 빠르게 새로운 인스턴스를 프로비저닝하고 노드로 등록시킨다.
이때 실제로 나가는 비용을 최적화하는 선택을 해주며, 반대로 여러 노드가 놀고 있다면 최대한 노드를 줄이는 등의 작업을 한다.
cluster autoscaler와의 차이
Cluster Autoscaler보다 좋다고 흔히 평가받는다.
다음의 점에서는 확실한 이점이 있다.
- 스펙 유연성
- 필요한 스펙에 따라 인스턴스의 유형을 고르고, 비용 최적화를 해준다.
- 신속한 프로비저닝
- 카펜터는 중간 과정 없이 자신이 직접 노드를 생성하라는 api를 쏘기에 속도가 매우 빠르다.
기능
크게는 두 가지로 하는 일을 나눌 수 있다.
- 스케줄링
- 파드가 펜딩이 걸릴 때 스케줄링이 될 수 있도록 필요한 노드를 프로비저닝한다.
- 중단(Disruption)
- 비용 효율적으로 노드를 통합한다(통합(consolidation)).
- 빈 노드 제거
- 여러 노드의 파드들을 한 노드로 모아줌
- 리소스 빈 패킹(가능한 적은 대상에 많은 요소를 배치하는 알고리즘)!
- 값싼 노드로 교체
- 관리자가 희망하는 노드의 스펙을 바꾸면 이를 추적하고 관리한다(이탈(drift)).
- 비용 효율적으로 노드를 통합한다(통합(consolidation)).
처음 개념을 봤을 때는 냅색 알고리즘과 비슷한 것인가 싶었다.
둘의 차이는 클러스터 관리 관점에서 이렇게 정리할 수 있다.
- knapsack
- 가능한 비용 내에서 최대의 가치를 산출하는 알고리즘
- 배치해야 할 파드가 여러 개 있고 노드의 크기와 개수가 정해져 있을 때, 어떤 파드를 배치할지를 고르는 문제이다.
- 냅색의 문제는 대체로 어떻게 해도 모든 파드를 배치할 수 없는 상황일 때의 문제이다.
- 노드의 개수와 각각의 자원이 정해져 있을 때 최대한 많은 파드를 배치하기
- bin packing
- 요구된 모든 자원을 가능한 적은 비용을 들일 수 있도록 자원을 배치하는 알고리즘
- 배치해야 할 파드가 여러 개 있고 노드의 크기가 정해져 있을 때, 어떻게 파드를 배치해서 노드를 적게 쓸지 고르는 문제이다.
- 최소한의 노드로 파드를 전부 배치하기
관련 오브젝트
카펜터에는 크게 3가지의 오브젝트가 존재한다.
- NodePool
- 카펜터가 노드를 프로비저닝할 때 어떤 인스턴스, 어떤 스펙을 고려해야 할지 지정한 오브젝트.
- 노드의 아키텍쳐는 어때야 하고, 이 노드풀에 속한 노드를 중단시킬 때는 어떻게 해야 하는지
- 어떤 파드가 이 노드에 배치될 수 있는지
- 여러 개를 둘 수 있고, 카펜터는 이 중 현재 요구사항에 맞춰 적합한 하나를 선택해 노드를 프로비저닝한다.
- 카펜터가 노드를 프로비저닝할 때 어떤 인스턴스, 어떤 스펙을 고려해야 할지 지정한 오브젝트.
- NodeClass
- 노드풀로 만들어질 노드에 대해 kubelet이나 여타 설정 사항들을 명시하는 오브젝트.
- 해당 노드에 파드는 얼마나 배치될 수 있고, 어떤 보안 그룹과 인스턴스 프로필을 가져야 하는지.
- 클라우드 제공자마다 고유한 스펙과 설정이 있을 수 있기에 각각 고유의 클래스가 있을 수 있다.
- AWS에서는
EC2NodeClass라는 오브젝트를 쓴다.
- AWS에서는
- 노드풀로 만들어질 노드에 대해 kubelet이나 여타 설정 사항들을 명시하는 오브젝트.
- NodeClaim
- 카펜터가 위의 두 오브젝트를 고려해 노드를 프로비저닝할 때, 노드와 1:1 매핑시키는 요청 오브젝트.
- NodeClaim은 불변 객체로 정의되며, 이를 통해 우리도 노드의 상태를 확인할 수 있다.
- 어떤 스펙과 설정을 가진 노드가 필요한지 정해지면 카펜터가 알아서 노드클레임을 만들고, 이를 기반으로 노드를 프로비저닝한다.
- 프로비저닝된 노드의 상태, 스펙 사항 등을 이 오브젝트를 통해 확인할 수 있다.
- 이 오브젝트는 카펜터가 자체적으로 만들기에, 관리자가 직접 세팅하는 오브젝트가 아니다.
- 카펜터가 위의 두 오브젝트를 고려해 노드를 프로비저닝할 때, 노드와 1:1 매핑시키는 요청 오브젝트.
카펜터가 버전 업 되면서, 많은 어노테이션과 오브젝트들의 이름이 변경됐다.
이 문서는 1.0 버전 이상을 기준으로 문서를 정리했다.
0.32 정도의 과거에는 Provisioner, NodeTemplate과 같은 이름으로 쓰였다고 한다.
아키텍처 및 원리
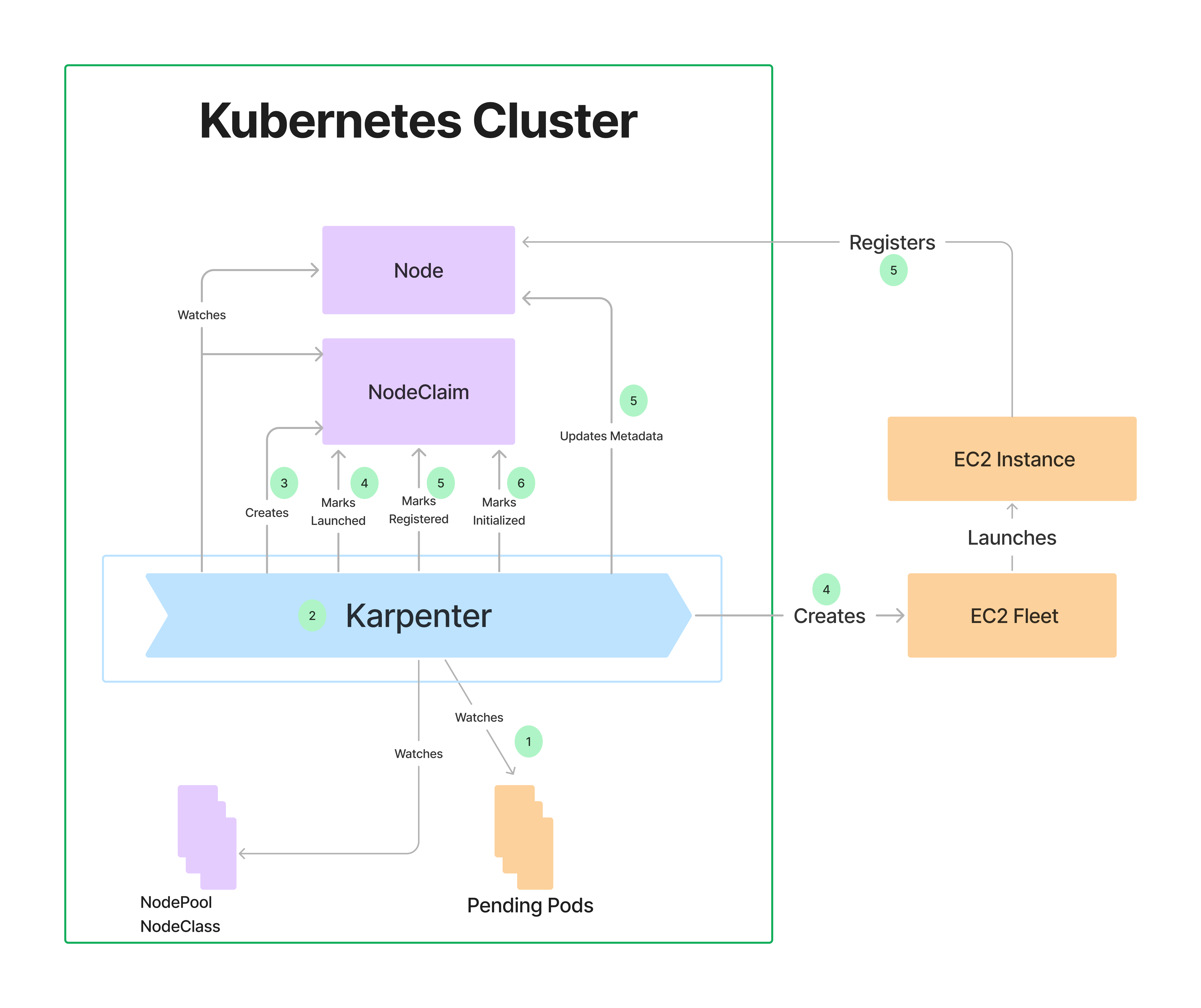
크게 보면 카펜터는 위의 방식으로 작동하는데, 위에서 봤듯 카펜터는 NodeClaim이란 오브젝트를 실제 노드와 1:1 매핑을 시켜서 관리한다.
scheldulable: false 컨디션을 가져 Pending 상태인 파드를 카펜터가 눈치채고 사전에 지정된 양식(NodePool, NodeClass)을 참고하여 NodeClaim 오브젝트를 만든다.
이 오브젝트가 수용되면 바로 클라우드 api로 인스턴스를 요청하고, 이것을 노드로 등록시킨댜.
즉 스케일링을 원할 때 바로 실제 인스턴스를 프로비저닝하도록 지원해준다.
라이프사이클
카펜터에 의해 노드 클레임이 관리되는 과정은 대충 이렇다.
- pre-spin
- 프로비저닝, 중단 등의 요구사항을 파악한다.
- 필요한 노드의 형식과 사이즈를 계산한다.
- 이를 통해 노드클레임을 만든다.
- launch
- 노드 클레임을 기반으로 클라우드 제공자에 맞는 api 요청으로 변환하여 요청한다.
- 클라우드 사정으로 이 요청이 실패할 수도 있는데, 이럴 경우 노드클레임을 통째로 삭제하고 다시 만든다.
- registration
- 만들어진 인스턴스를 노드 오브젝트로 등록하고 테인트, 라벨 등을 붙여준다.
- 이 작업이 15분 안에 이뤄지지 않는다면 마찬가지로 노드클레임과 인스턴스를 삭제하고 다시 노드클레임을 만든다.
- 노드 클레임과 매핑한다.
- initalization
- 노드가 정상적으로 초기화되도록 기다린다.
- startup 테인트(아래에서 보자)가 삭제되기까지 기다리는 과정이다.
스케줄링
파드가 배치되는데 있어서 고려될 사항은 크게 세 가지로 나뉠 수 있다.
- 클라우드 제공자가 제공하는 인스턴스 타입, 아키텍쳐, 존 등의 인프라 층
- 클러스터 관리자가 정의하는 노드 조건, 제약
- 이 위에 워크로드를 올리는 개발자의 스케줄링 관련 설정
이러한 요소들을 카펜터는 전부 고려하며 프로비저닝에 활용한다.
affinity, selector 등 스케줄링 라벨로 활용할 수 있는 것들은 여기를 참고하자.[1]
잘 알려진 라벨들에 대해서는 카펜터가 알아차리고 이런 파드가 펜딩에 걸릴 때, 카펜터가 동작한다.
nodeSelector:
user: only-know
그러나 유저만 아는, 커스텀 스케줄링 조건들에 대해서는 기본적으로 카펜터가 신경쓰지 않는다.
다만 NodePool 에서 설정하는 방법들이 있어서 이를 명시해주면 카펜터도 이를 인식하고 스케줄링에 관여하게 될 것이다.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: ebs
provisioner: ebs.csi.aws.com
volumeBindingMode: WaitForFirstConsumer
allowedTopologies:
- matchLabelExpressions:
- key: topology.ebs.csi.aws.com/zone
values: ["us-west-2a", "us-west-2b"]
여기에 추가적으로 카펜터는 PV 토폴로지에 대해서도 신경을 쓴다.
특정 AZ에서만 사용할 수 있는 스토리지 클래스가 있고 파드가 이걸 활용하는 PVC를 마운팅한다면, 카펜터는 해당 AZ에 파드가 배치될 수 있도록 고려해준다.
또한 여러 노드풀을 만들어뒀다면 가중치를 세팅하여 어떤 노드풀이 더 먼저 고려될지 선호도를 지정할 수 있다.
중단(Disruption) 알고리즘
중단을 위해서 카펜터에서는 Disruption, Termination 이렇게 크게 두 가지의 컨트롤러가 동작하고 있다.
(내부적으로는 더 세분화된다.)
두 컨트롤러 간 교차할 수 있는 문제를 방지하고, 사용자의 자체 노드 삭제 등을 처리하고자 기본적으로 노드에 Finalizer를 설정해준다.
Distruption Controller
위에서 말한 중단 기능들을 해주는 컨트롤러이다.
다음의 제어 흐름을 가지고 있다.
- 중단 관련 기능을 적용할 후보 리스트를 만든다.
- 축출되면 안 되는 파드가 있는 노드라면 해당 노드를 무시하고 나중에 다시 고려한다.
- 중단 가능한 노드가 없다면 다음 스텝
- 중단 가능한 노드에 대해서는 다음의 과정을 진행한다.
- 중단을 할 때 노드풀의 중단 정책에 걸리는지 체크.
- 해당 노드의 파드들을 다른 노드들이 전부 받아줄 수 있는지 스케줄링 시뮬레이션 실행.
- 체크가 완료된 노드에는
karpenter.sh/disrupted:NoSchedule테인트를 걸어 파드가 더 이상 스케줄링되지 못하도록 막는다. - 2번에서 시뮬레이션한 대로 파드를 옮기고 모두 준비 상태가 될 때까지 기다린다.
- 이 과정이 실패하면 3번을 취소하고 1번부터 다시 시작한다.
- 노드 오브젝트를 삭제하고 Termination Controller가 노드를 종료시킬 때까지 기다린다.
이 흐름을 계속 반복한다.
그렇다면 어떤 조건에 따라 후보를 만들까?
여기에는 통합(consolidation)과 이탈(drift), 두 가지 매커니즘이 존재하며 이를 통해 중단할 후보가 나오게 된다.
통합(consolidation)
클러스터의 비용을 줄이는 기능으로 다음 상황에서 다음과 같이 동작한다.
- 노드가 비어 있거나, 다른 노드에 워크로드를 옮겨도 문제없음 - 노드 삭제
- 더 작은 스펙으로 노드가 변경되도 문제없음 - 노드 교체
그리고 통합은 총 세가지 방식으로 수행될 수 있다.
- 빈 노드들을 병렬적으로 통합
- 여러 노드를 병렬적으로 중단시키고 하나의 대체 노드로 교체
- 한 노드를 더 작은 비용의 노드로 교체
여러 노드를 중단하면서 하나의 노드로 교체하는 작업은 최적의 해가 없기에, 카펜터는 휴리스틱하게 접근한다.
통합이 활성화됐다면 주기적으로 카펜터는 통합할 수 없는 이유를 노드에 대한 이벤트로 제공해준다.
참고로 어피니티나 토폴로지스프레드에서 prefferd를 활용하면 통합 효율이 떨어질 수 있다.
실제로는 스케줄링이 가능할지라도 카펜터는 최대한 기존 환경과 비슷하게 스케줄링 조건을 지키고자 노력한다.
가령 한 노드에 여러 파드가 배치되는 것이 가능하지만, 가능한 여러 노드에 배치하는 것을 선호하는 설정 때문에 카펜터가 통합을 하지않을 수 있다는 말이다.
SpotToSpot Consolidation
스팟 노드들에 대해서는 교체 없이 삭제만 하도록 설정돼있다.
SpotToSpotConsolidation 인자를 주면 교체도 지원한다.
기본적으로 스팟 인스턴스에 대해서 카펜터는 price-capacity-optimized 전략을 쓴다.
이것은 비용 효율적인 스팟을 고르되, 해당 스펙의 스팟의 인기도를 평가해 뺏길 가능성도 낮은 스팟을 고르는 전략이다.
그래서 이 기능을 활성화한다고 무턱대고 빨리 뺏길 수도 있는 스팟으로 교체하거나 하는 일은 발생하지 않는다.
번외 - 통합은 NP 문제인가
컴퓨터 과학에서의 NP(Non-deterministic Polynomial) 문제는 yes or no를 맞추는 문제(결정 문제)에서 답이 주어졌을 때 이에 대한 검산은 쉽게 할 수 있는 문제를 말한다.
(P 문제는 결정 문제에서 문제로부터 다항 시간 내의 답을 찾고 증명할 수 있는 문제를 일컫는다.)
통합 기능이란 건 결국 노드의 비용을 최적화하는 문제로서 bin packing 알고리즘을 사용해야 한다.
그리고 bin packing은 아직 다항 시간으로 해결할 수 있는 알고리즘이 발견되지 않았기에 대표적인 NP 문제 중 하나다.
이에 대한 휴리스틱 접근법 중 하나는, 큰 값들을 먼저 노드에 배치하가며 빈 공간을 채우는 그리디 알고리즘을 쓰는 것이다.[2]
카펜터 역시 이러한 FFD(First Fit Decresing)을 사용한다.[3]
순서는 대충 이렇다.
일단 배치가 필요한 파드들을 같은 존으로 묶일 수 있는 것들을 기준으로 그룹화하고, 각 그룹에 대해 다음의 알고리즘을 적용한다.
- 리소스 요청량을 기준으로 파드 리스트를 전부 내림차순 정렬한다.
- 필터링 등으로 사용가능한 인스턴스 타입 리스트를 오름차순 정렬한다.
- 인스턴스 타입을 순회한다.
- 파드 리스트를 순회한다.
- 파드가 인스턴스 타입에 맞지 않다면 더 큰 인스턴스 타입을 고른다(break).
- 맞다면 해당 파드를 넣는다.
- 파드 리스트를 순회한다.
- 가장 많은 파드가 들어가는 인스턴스 타입을 선택한다.
- 남은 파드에 대해서 다시 3번부터 적용한다.
이게 문서에 나온 알고리즘인데, 보통의 FFD는 인스턴스 타입, 즉 크기가 고정되어 있는 상태에서 근사해를 구한다.
이 문서는 3년 전의 디자인인데 그냥 이대로만 적용됐다면, 매번 무조건 큰 인스턴스 타입이 먼저 선택될 것이다.
그래서 아마 코드에서는 조금 더 로직이 수정되지 않았을까 싶은데, 그 코드 부분을 아직 못 찾아서 나중에 보충해야겠다.
이탈(drift)
Drift는 노드클레임이 속한 노드풀, 노드클래스를 변경했을 때 작동하는 매커니즘이다.
노드 자체는 카펜터가 관리하기에 사용자로서 노드의 스펙들을 낮추고 싶다던가할 때는 노드풀, 노드클래스를 변경해야 한다.
마치 디플로이먼트에서 파드의 스펙을 바꾸면 바꾼 이력을 남기기 위해 디플로이먼트가 새로운 버전을 만들어주는 것과 비슷하다.
관리자가 관련한 노드풀 스펙을 바꿨는데 속한 노드클레임이 바뀐 스펙에 포함되지 않는다면 해당 노드에 대해서 이탈됐다(drifted)고 표시한다.
이 오브젝트들에 대한 변경이 무조건 이탈 표시로 이어지진 않는다.
가령 변경이 됐는데도 현재 노드의 스펙이 포함되는 상태이거나, 중단 정책 등을 설정하는 필드에 대한 수정은 이탈로 표시할 이유가 없다.
강제적인 중단
통합과 이탈은 중단할 노드 후보 리스트를 만드는 신사적인 방식이지만.. 다급하게 종료를 시켜야 하는 노드가 있을 수 있다.
이러한 조건에서 카펜터는 해당 노드를 노드 중단 정책이나 파드들의 안전한 배치 따위 신경쓰지 않고 중단을 진행한다!
이와 관련한 요소는 3가지 정도 있다.
만료(Expiration)
NodePool에서 보겠지만 노드의 만료 시간을 지정할 수 있다.
만료 시간을 넘은 노드는 바로 이탈 표시가 되며 교체된다.
주의할 것이 PDB는 어플리케이션의 안정성을 위해 설정되는데 이것 때문에 노드의 드레인에 차질이 생길 수 있다.
그래서 이걸 설정할 때는 노드의 안전 종료 기간도 같이 설정해서 특정 시간이 지나도 파드들이 없어지지 않으면 무조건 종료시켜버리도록 강제하는 것이 좋다.
그럼 PDB가 잠시 깨지기에 서비스 안정성에 아쉬움이 생길 수 있지만, 최소한 노드 관리는 확실하게 된다.
방해(Interruption)
클러스터를 운영하면서 클러스터 외적인 이슈가 발생하여 노드에 영향이 갈 수 있는데, 이것들을 interruption이라고 부른다.
다음의 사항들이 있다.
- 스팟 중단 경고
- 유지보수를 위한 예정된 변경 이벤트
- 인스턴스 종료 이벤트
- 인스턴스 중지 이벤트
관리되는 노드에 대해 이런 일이 발생하면 카펜터는 즉시 테인트, 드레인 작업을 하고 가능한 시간(스팟 중단의 경우 2분)까지 최대한 워크로드들이 다른 곳에 배치될 수 있도록 시간을 확보해준다.
이 말은 곧 2분안에 안전하게 종료되기 힘든 워크로드는 애초에 스팟에 넣지 않는 것이 좋다는 말이기도 하다.
대체로 카펜터는 새로운 노드를 2분안에 프로비저닝할 수 있기 때문에 워크로드만 잘 돌아가준다면 큰 문제는 발생하지 않을 것이다.
스팟에 관해서, 카펜터는 AWS SQS를 활용해 관련 이벤트를 받는다.
그래서 Eventbridge에서 SQS로 이벤트가 보내지도록 미리 세팅이 돼있어야하는데, 아래 실습에서 관련 리소스를 간단하게 볼 것이다.
이 기능을 쓰려면 --interruption-queue 인자에 큐 이름을 넣어줘야 한다.
사실 스팟 인스턴스를 관리하려면 필수적이라 볼 수 있다.
노드 자동 회복
클라우드 제공자가 제공하는 노드 헬스체크 및 대응 기능이 있을 수 있다.
디스크 수명, 메모리 누수, 압박 등의 진단을 해줄 때, 카펜터는 건강하지 않다는 이벤트를 체크한다.
이를 감지해서 최대한 대응해주긴 하지만, 서비스 장애 예방 차원에서 이런 이벤트가 한꺼번에 일어난다고 해도 노드풀 내에서 최대 20퍼까지만 한번에 고쳐준다.
이 기능을 쓰려면 클러스터에 노드 모니터링 에이전트나 노드 상태를 진단하는 툴이 있어야 한다.
카펜터에서는 NodeRepair=true로 인자 설정이 돼야 한다.
수동 삭제
수동으로 노드를 삭제하는 것은 disruption controller가 관여하는 일은 아니다만, 아무튼 컨트롤러 입장에서 강제라면 강제다.
노드를 삭제할 때는 노드 클레임을 먼저 없애고, 그 다음에 노드를 없애면 된다.
노드풀을 삭제해도 관련 노드 삭제가 진행된다.
Termination Controller
노드를 안전하게 종료시키고 파드 축출을 책임지는 컨트롤러이다.
위에서 말했듯이 finalizer가 설정돼 kube-apiserver에 노드 삭제를 걸어두어도 바로 삭제되지 않도록 막는다.
이를 통해 안전한 종료를 할 수 있도록 만든다.
다음의 제어 흐름을 가지고 있다.
karpenter.sh/disrupted:NoSchedule을 감지한다.- 쿠버네티스의 축출 api를 통해 파드를 축출한다.
- PDB를 고려하고, 정적 파드는 무시한다.
- 위 테인트를 용인하는 파드도, 성공 및 실패한 파드도 제거한다.
- 노드클레임을 삭제한다.
- 클라우드 제공자에는 인스턴스 삭제 api를 쏜다.
- 노드의 finalizer를 삭제하고, kube-apiserver가 노드를 삭제할 수 있게 풀어준다.
직접 삭제하는 케이스에 대해서도 finalizer가 붙어있어 가능한 안전하게 파드들이 옮겨지고 삭제되는 것이 보장된다.
또 클라우드 제공자가 인스턴스를 삭제하는 과정 역시 보장해준다.
(이 finalizer가 없으면 termination controller가 인스턴스 삭제를 보장해줄 수 없으니 함부로 finalizer 없애지 말자)
이제부터는 각 오브젝트 설정법을 보자.
실습에서 정리하게 너무 길어서 사전 지식에 스펙 작성법까지 남겨둔다.
NodePool 세부
노드풀은 스케일될 때 선택할 노드를 고르기 위한 선택지의 묶음 오브젝트이다.
여기에는 kubelet 설정, 노드 만료시간 뿐만 아니라 AZ, 서브넷 등의 클라우드 환경 제약도 걸어둘 수 있다.
심지어 온디맨드를 쓸지, 스팟을 쓸지도 설정할 수 있다.
문서에서는 관련해서 알아야 할 요소들을 이렇게 소개한다.
Unschedulable: True상태가 설정된 파드가 있을 때만 해당 파드를 스케줄하기 위해 동작한다.- 늘어날 노드풀 설정, 붕괴될 노드풀 설정을 명시할 수 있다.
- 라벨, 어노테이션, 테인트를 붙일 수 있다.
- 멀티 노드풀을 운영하는 것이 가능하다.
노드풀은 카펜터가 관리할 노드에 대한 스펙과 그 노드 위에 올라갈 수 있는 파드를 정의한다.
하나의 클러스터에 여러 개의 노드풀을 구성할 수 있다.
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
# 프로비저닝할 NodeClaim 리소스의 템플릿 정의 섹션으로, 이것이 최소한의 요구치가 된다.
template:
# 노드에 부여될 메타데이터
metadata:
labels:
billing-team: my-team
annotations:
example.com/owner: "my-team"
spec:
# 클라우드 제공자마다 지정한 NodeClass 스펙
nodeClassRef:
group: karpenter.k8s.aws # Updated since only a single version will be served
kind: EC2NodeClass
name: default
taints:
- key: example.com/special-taint
effect: NoSchedule
# 노드 초기화 시에 잠시 적용되는 테인트로, 완전히 준비 상태가 되고 파드가 배치될 수 있게 한다.
startupTaints:
- key: example.com/another-taint
effect: NoSchedule
# 장기 실행 간 메모리 누수, 파일 깨짐 현상 등의 위험을 최소화하기 위한 노드 생존 시간
# 값 수정 시 Nodeclaim이 drift된다.
expireAfter: 720h | Never
# 노드 강제 삭제 이전 드레인 유예 시간.
# 파드의 안전 종료값보다 크게 하는 것이 좋다.
# 값 수정 시 Nodeclaim이 drift된다.
terminationGracePeriod: 48h
# 프로비저닝할 노드에 대한 요구사항으로, 어피니티와 같은 파드 스케줄링 조건과 결합된다.
# In, NotIn, Exists, DoesNotExist, Gt, Lt 연산자 사용 가능
requirements:
- key: "karpenter.k8s.aws/instance-category"
operator: In
values: ["c", "m", "r"]
# 이 타입에서 최소 2개를 고르게 하는 실험적 필드.
minValues: 2
- key: "karpenter.k8s.aws/instance-family"
operator: In
values: ["m5","m5d","c5","c5d","c4","r4"]
minValues: 5
- key: "karpenter.k8s.aws/instance-cpu"
operator: In
values: ["4", "8", "16", "32"]
- key: "karpenter.k8s.aws/instance-hypervisor"
operator: In
values: ["nitro"]
- key: "karpenter.k8s.aws/instance-generation"
operator: Gt
values: ["2"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["us-west-2a", "us-west-2b"]
- key: "kubernetes.io/arch"
operator: In
values: ["arm64", "amd64"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot", "on-demand", "reserved"]
# 노드를 중단하거나 교체하는 설정을 정의하는 중단 섹션
disruption:
# 통합을 위해 카펜터가 고려할 정책
# 'WhenEmptyOrUnderutilized'일 시 모든 노드를 탐색해 최대한 통합 시도
# `WhenEmpty`일 시 워크로드 파드가 없는 노드만 고려
consolidationPolicy: WhenEmptyOrUnderutilized | WhenEmpty
# 파드가 배치된 후 통합에 고려할 대기 시간으로 Never를 쓰면 통합이 비활성화된다.
consolidateAfter: 1m | Never
# 노드 스케일 다운 속도 조절
# 한번에 최대 10%만큼 줄일 수 있고, 평일 근무 시간에는 스케일다운되지 않도록 한 예시
budgets:
- nodes: 10%
# schedule과 duration은 반드시 같이 써져야 함
- schedule: "0 9 * * mon-fri"
duration: 8h
nodes: "0"
# 노드풀의 총 사이즈 제한으로 이 값을 넘어서까지 프로비저닝하지는 않는다.
limits:
cpu: "1000"
memory: 1000Gi
nvidia.com/gpu: 2
# 노드풀 간 가중치로, 높을 수록 선택될 가능성이 올라간다.
weight: 10
status:
conditions:
- type: Initialized
status: "False"
observedGeneration: 1
lastTransitionTime: "2024-02-02T19:54:34Z"
reason: NodeClaimNotLaunched
message: "NodeClaim hasn't succeeded launch"
resources:
cpu: "20"
memory: "8192Mi"
ephemeral-storage: "100Gi"
NodeClass는 반드시 들어가야 하는 값이다.
template.spec
startupTaints
노드 초기화를 위해 네트워크 설정 등이 필요한 시간을 벌어준다.
가령 Cillium의 경우 네트워크 초기화를 위한 시간이 필요해 관련한 테인트를 걸도록 권장하고 있는데 이런 것들을 미리 걸어줄 수 있다는 것이다.
requirements
인스턴스의 요구 스펙을 정의한다.
쿠버네티스의 well-known 라벨과, 몇 가지 카펜터 한정, aws 전용 라벨들을 쓸 수 있다.
node.kuberntes.io/instance-typekarpenter.k8s,aws/instance-familykarpenter.k8s,aws/instance-categorykarpenter.k8s,aws/instance-generationtopology.kubernetes.io/zonekubernetes.io/arch-amd64,arm64kubernetes.io/os-linux,windowskarpenter.sh/capacity-type-on-demand,spot,reserved
minValue 필드는 여러 개 쓸 수 있는데, 그 중에서 최대값이 고려된다.
특정 스펙에 대해 어떤 값이든 상관없다면 value에 []를 써버리면 되는데, 권장되진 않는다.
terminationGracePeriod
노드의 안전 종료 기간을 나타낸다.
이 값은 파드의 안전 종료 기간(terminationGracePeriodSeconds)보다 높게 잡아주는 것이 좋다.
이 기간이 지나도 종료되지 않는 파드는 기냥 바로 강제 삭제 당한다.
disruption
중단(Disruption) 알고리즘에 나온 각종 설정을 할 수 있다.
budget
- nodes: "0"
schedule: "@daily"
duration: 10m
reasons:
- "Underutilized"
- nodes: "10%"
reasons:
- Drifted
중단 정책을 지정하는 필드이다.
이걸로 중단을 시킬 때 속도를 조절할 수 있고, 어느 타이밍에 될지만 정할 수도 있다.
만료(Expiration)된 노드는 강제 중단되는 케이스에 해당하니 이 정책의 적용을 받지 않으니 주의하자.
nodes에는 퍼센트와 정수를 적을 수 있다.
퍼센트를 쓸 경우, 최대 중단가능한 값은 (전체 노드 개수 * 퍼센트) - 종료되는 개수 - notready 노드 개수가 된다.
정수로 적어도 종료되거나 준비되지 않은 노드까지 고려해서 값을 정한다.
nodes를 0으로 지정하면 중단이 중단된다!
schedule에는 cron 값을 적어주면 되는데, 현재는 무조건 UTC 기준이니 헷갈리지 말자.
그리고 이게 유지되는 기간은 duration으로 지정하는데, 10h5m과 같은 식으로 써주면 된다.
reasons 필드를 작성해서 어떤 중단 사유에 대해서 지정할지도 세분화할 수 있다.
가능한 값은 Drifted, Underutilized, Empty이 있다.
NodeClass 세부
노드 클래스는 각 클라우드 제공자 별로 특별한 설정을 정의하기 위한 별도의 오브젝트이다.
AWS에서는 EC2NodeClass라는 오브젝트를 만들어서 사용하면 된다.
kind: NodePool
...
# NodePool에서 이렇게 nodeClass를 명시해준다.
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
...
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
kubelet:
podsPerCore: 2
maxPods: 20
systemReserved:
cpu: 100m
memory: 100Mi
ephemeral-storage: 1Gi
kubeReserved:
cpu: 200m
memory: 100Mi
ephemeral-storage: 3Gi
evictionHard:
memory.available: 5%
nodefs.available: 10%
nodefs.inodesFree: 10%
evictionSoft:
memory.available: 500Mi
nodefs.available: 15%
nodefs.inodesFree: 15%
evictionSoftGracePeriod:
memory.available: 1m
nodefs.available: 1m30s
nodefs.inodesFree: 2m
evictionMaxPodGracePeriod: 60
imageGCHighThresholdPercent: 85
imageGCLowThresholdPercent: 80
cpuCFSQuota: true
clusterDNS: ["10.0.1.100"]
# 인스턴스에 붙을 서브넷을 지정하며 Terms 방식
# Terms 방식: -를 이용해 명시하는 영역 간에는 OR 조건, 그외에는 AND 조건으로 간주된다.
subnetSelectorTerms:
# 두 태그가 전부 있거나, 특정 id인 서브넷을 고르는 예시.
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}"
environment: test
- id: subnet-09fa4a0a8f233a921
# 인스턴스에 붙을 보안그룹을 지정하며 Terms 방식
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}"
environment: test
- name: my-security-group
- id: sg-063d7acfb4b06c82c
# 노드의 신원을 위한 IAM 롤로, 이 값을 쓸 경우 이 값은 변경 불가다(현재는).
# 롤이나 인스턴스 프로필을 둘 중에 하나를 써줘야 한다.
role: "KarpenterNodeRole-${CLUSTER_NAME}"
instanceProfile: "KarpenterNodeInstanceProfile-${CLUSTER_NAME}"
# 유저데이터 생성과 블록 디바이스 매핑을 위해 필요한 필드로, `alias` amiSelectorTerm을 설정한다면 없어도 된다.
amiFamily: AL2
# 인스턴스의 AMI 지정하며 방식은 Terms 방식
amiSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}"
environment: test
- name: my-ami
- id: ami-123
# alias는 특정 ami를 명확하게 지목할 때 쓰며, 다른 조건과 함께 쓰일 수 없다.
# - alias: al2023@v20240703
# capacityReservation을 지정하며 Terms 방식
capacityReservationSelectorTerms:
- tags:
karpenter.sh/discovery: ${CLUSTER_NAME}
- id: cr-123
tags:
team: team-a
app: team-a-app
# IMDS 지정
metadataOptions:
httpEndpoint: enabled
httpProtocolIPv6: disabled
httpPutResponseHopLimit: 1 # 1이면 컨테이너에서는 접근이 불가능
httpTokens: required
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 100Gi
volumeType: gp3
iops: 10000
encrypted: true
kmsKeyID: "1234abcd-12ab-34cd-56ef-1234567890ab"
deleteOnTermination: true
throughput: 125
snapshotID: snap-0123456789
instanceStorePolicy: RAID0
# 노드 초기화를 위한 유저데이터와 알아서 병합되는 유저데이터
userData: |
echo "Hello world"
detailedMonitoring: true
# Public Subnet일 때 공인 IP를 받을지 지정하며, 없으면 서브넷 설정을 따라간다.
associatePublicIPAddress: true
status:
# 예약된 값들이 나온다.
subnets:
- id: subnet-0a462d98193ff9fac
zone: us-east-2b
- id: subnet-0322dfafd76a609b6
zone: us-east-2c
- id: subnet-0727ef01daf4ac9fe
zone: us-east-2b
- id: subnet-00c99aeafe2a70304
zone: us-east-2a
- id: subnet-023b232fd5eb0028e
zone: us-east-2c
- id: subnet-03941e7ad6afeaa72
zone: us-east-2a
securityGroups:
- id: sg-041513b454818610b
name: ClusterSharedNodeSecurityGroup
- id: sg-0286715698b894bca
name: ControlPlaneSecurityGroup-1AQ073TSAAPW
amis:
- id: ami-01234567890123456
name: custom-ami-amd64
requirements:
- key: kubernetes.io/arch
operator: In
values:
- amd64
- id: ami-01234567890123456
name: custom-ami-arm64
requirements:
- key: kubernetes.io/arch
operator: In
values:
- arm64
capacityReservations:
- availabilityZone: us-west-2a
id: cr-01234567890123456
instanceMatchCriteria: targeted
instanceType: g6.48xlarge
ownerID: "012345678901"
- availabilityZone: us-west-2c
id: cr-12345678901234567
instanceMatchCriteria: open
instanceType: g6.48xlarge
ownerID: "98765432109"
# 롤으로부터 생성된 인스턴스 프로필
instanceProfile: "${CLUSTER_NAME}-0123456778901234567789"
conditions:
- lastTransitionTime: "2024-02-02T19:54:34Z"
status: "True"
type: InstanceProfileReady
- lastTransitionTime: "2024-02-02T19:54:34Z"
status: "True"
type: SubnetsReady
- lastTransitionTime: "2024-02-02T19:54:34Z"
status: "True"
type: SecurityGroupsReady
- lastTransitionTime: "2024-02-02T19:54:34Z"
status: "True"
type: AMIsReady
- lastTransitionTime: "2024-02-02T19:54:34Z"
status: "True"
type: Ready
kubelet
말 그대로 kubelet에 대한 설정을 하는 필드이다.
그래서 kubelet에 대해 설정할 수 있는 거의 모든 필드들을 그대로 넣어줄 수 있다.
그러나 이것만으로 충분하지 않다면 Cloud-init양식에 맞춰 userdata 필드로 작성해도 무방하다.
노드에 배치될 파드의 최대 개수를 여기에서 설정을 할 수는 있는데, 어차피 VPC CNI를 쓰는 경우 파드의 개수는 인스턴스 타입에 의해 결정나게 되기도 한다는 것을 명심하자.
eviction
축출 설정에 대해, soft와 hard의 설정이 나뉜다.
soft는 파드 자체에 설정된 안전 종료 필드를 존중해주지만 hard의 경우 자체적으로 무조건 kill 해버린다.
참고로 botttlerocket에서는 evitction 관련 필드를 쓰더라도 무시된다.
systemReserved
클러스터에서 활용할 수 있는 노드의 자원을 명시적으로 지정하는 필드이다.
작성하지 않더라도 카펜터에서 알아서 사용하는 ami, 인스턴스 타입에 따라 값을 등록해주긴 한다.
그러나 만약 커스텀 ami를 쓰는 케이스라면 실제 노드의 가용 자원과 등록되는 자원값이 다를 수 있다는 것을 유의해야 한다.
ami
amiFamily, amiSelectorTerms 필드를 통해 지정할 수 있다.
selectorTerms으로 ami를 지정할 때, alias를 지정할 수 있다.
- al2
- al2023
- bottlerocket
- windows2019
- windows2022
만 지원되며, 뒤에 @를 통해 구체적 버전이나 latest를 명시하면 된다.
문서에서는 amiFamily보다 셀렉터로 alias를 사용하기를 권장하고 있는데, amiFamily는 결국 어떤 ami가 선택될지를 명확하게 보장하지 않기 때문이다.
EKS 최적화 ami를 쓰고 싶다면 alias를 활용하는 것이 가장 확실하다.
참고로 al2는 Kubernetes v1.32 - Penelope까지만 지원된다..
subnetSelectorTerms
어떤 AZ에 배치되기 원할 때 설정하면 도움된다.
spec:
subnetSelectorTerms:
- tags:
Name: my-subnet
MyTag: '' # 이 태그를 가지면 모두 매칭된다.
매칭할 때 비어있게 하거나, *를 써서 와일드카드 처리를 할 수도 있다.
tags
말 그대로 태그를 다는 건데, 주의할 것은 카펜터 관련 태그는 직접 넣어도 무시된다.
karpenter.shkarpenter.k8s.awskubernetes.io/cluster
카펜터가 노드를 관리할 때 사용되기 때문에 쓰지 않는 것이 좋다.
오버프로비저닝
클러스터 오토스케일링은 결국 리소스가 전체 양을 늘리는 작업이다.
이런 작업이 필요할 때, 미리 예상되는 시점에 노드를 늘려놓는 전략이 필요할 수 있다.
이런 경우에 오버프로비저닝을 미리 해두는 전략이 유용하다.
예시를 들면, 일단 임의의 파드를 늘린다.
다만 이 파드의 우선순위를 극한으로 낮춰서 다른 필요한 파드가 배치돼야할 때 언제든지 축출될 수 있도록 한다.
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -10
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
namespace: default
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
terminationGracePeriodSeconds: 0
containers:
- name: reserve-resources
image: registry.k8s.io/pause:3.9
resources:
requests:
cpu: "200m"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning-autoscaler
namespace: default
labels:
app: overprovisioning-autoscaler
spec:
selector:
matchLabels:
app: overprovisioning-autoscaler
replicas: 1
template:
metadata:
labels:
app: overprovisioning-autoscaler
spec:
containers:
- image: registry.k8s.io/cluster-proportional-autoscaler-amd64:1.8.1
name: autoscaler
command:
- /cluster-proportional-autoscaler
- --namespace=default
- --configmap=overprovisioning-autoscaler
- --default-params={"linear":{"coresPerReplica":1}}
- --target=deployment/overprovisioning
- --logtostderr=true
- --v=2
serviceAccountName: cluster-proportional-autoscaler-service-account
이 예시는 클러스터 오토스케일러를 통해 오버 프로비저닝을 하는 예시이다.
카펜터를 활용할 때도 우선순위가 낮은 파드를 여러개 만들어두는 전략은 똑같이 사용할 수 있다.
실습 진행
이제 실습을 하면서 어떤 식으로 동작하는지, 어떻게 쓰는 게 좋은지 확인할 시간이다.
테라폼 설치
####################################################
##### karpenter
####################################################
locals {
karpenter_name_in_cluster = "karpenter"
karpenter_namespace = "karpenter"
}
module "eks_karpenter" {
source = "terraform-aws-modules/eks/aws//modules/karpenter"
version = "20.33.1"
cluster_name = module.eks.cluster_name
create = true
create_iam_role = true
enable_irsa = true
irsa_oidc_provider_arn = module.eks.oidc_provider_arn
create_node_iam_role = true
irsa_namespace_service_accounts = ["${local.karpenter_namespace}:${local.karpenter_name_in_cluster}"]
enable_v1_permissions = true
enable_spot_termination = true
queue_name = "karpenter-queue"
}
resource "aws_iam_service_linked_role" "spot" {
aws_service_name = "spot.amazonaws.com"
}
이 모듈을 최대한 활용했다.[4]
문서에는 안 나와있지만, irsa를 활용할 경우에는 irsa_oidc_provider_arn을 넣어주어야만 한다.
(eks 모듈에서 블록으로 넣을 경우에는 상관 없을 가능성이 높다.)
스팟 인스턴스를 활용할 수 있도록 세팅을 했는데, 한번도 스팟 인스턴스를 사용하지 않은 계정의 경우 service linked role이 자동으로 만들어지지 않았을 것이다.
그렇기에 최하단의 블록을 명시적으로 넣어주어야만 한다.
resource "helm_release" "karpenter" {
name = local.karpenter_name_in_cluster
repository = "oci://public.ecr.aws/karpenter"
chart = "karpenter"
version = "1.3.1"
namespace = local.karpenter_namespace
create_namespace = true
values = [
<<-EOF
additionalLabels:
app: karpenter
additionalAnnotations:
"karpenter.sh/do-not-disrupt": "true"
service:
annotations: {}
serviceAccount:
create: true
name: ${local.karpenter_name_in_cluster}
annotations:
"eks.amazonaws.com/role-arn": ${module.eks_karpenter.iam_role_arn}
serviceMonitor:
enabled: true
podAnnotations: {}
dnsPolicy: ClusterFirst
nodeSelector:
kubernetes.io/os: linux
logLevel: info
settings:
# batch window
batchMaxDuration: 10s
batchIdleDuration: 1s
clusterName: ${module.eks.cluster_name}
isolatedVPC: false
# 활성화 시 eks describe api를 통해 컨트롤 플레인 탐색.
eksControlPlane: true
# 인스턴스가 활용하는 메모리 비율
vmMemoryOverheadPercent: 0.075
# SQS로부터 interruption 핸들링
interruptionQueue: ${module.eks_karpenter.queue_name}
featureGates:
nodeRepair: false
reservedCapacity: false
spotToSpotConsolidation: true
EOF
]
}
이후에 헬름으로 카펜터를 설치해준다.
헬름 설치를 할 때 ECR을 활용하는데, 이것은 헬름 3.8버전부터 지원하는 기능이다.[5]
카펜터가 설치된 노드가 카펜터에 먹히는 것을 방지하고자 어노테이션을 달았다.
그러나 실습에서는 카펜터를 쓰지 않던 운영 환경에서 카펜터를 보조로 활용하는 방향으로 가정하고 진행했기에 실상 상관 없다.
세팅 부분에 interruptionQueue로 SQS 이름을 넣어주어 스팟 강제 중단 이벤트에 대응할 수 있도록 설정한다.
이밖에 자잘하게 세팅한 것들이 있다.

일단 eks 클러스터의 서브넷, 보안 그룹에 karpenter.sh/discovery라는 태그를 달아 카펜터가 자동으로 각종 리소스를 알아서 추적할 수 있도록 만든다.

기본 프롬 스택에서는 프로메테우스 쪽에 추가 설정을 넣었다.
이 값은 문서에 나와있다.[6]
그라파나 대시보드도 나와있으나[7], 현재 사용하고 있는 프로메테우스 스택의 values.yaml 파일에서는 설정할 수 있는 방법이 없다.
아예 프롬스택에서 그라파나를 빼고 따로 설치할까 하다가, 고작 대시보드 2개 하자고 분리하는 것도 좀 별로다 싶어서 그라파나 대시보드는 프로비저닝된 이후 직접 세팅하도록 한다.
https://karpenter.sh/v1.3/getting-started/getting-started-with-karpenter/karpenter-capacity-dashboard.json
https://karpenter.sh/v1.3/getting-started/getting-started-with-karpenter/karpenter-performance-dashboard.json
다음의 두 대시보드를 받으면 된다.
(깃헙 레포를 가보면 다른 json 파일도 있는데 하나는 컨트롤러 전체에 관한 거고, 다른 하나는 과거 버전을 기반으로 하는지 메트릭이 없으므로 주의하자)
확인

기본적으로 이벤트브릿지로 인스턴스에 관련한 이벤트를 받을 수 있도록 설정된다.


각 룰은 각 이벤트를 받도록 돼있고, 이 이벤트를 SQS로 보낸다.

그에 맞는 SQS 또한 만들어지는데, 이 큐에서 카펜터가 이벤트를 받아서 보게 될 것이다.

프로메테우스 쪽은 디스커버리를 통해 메트릭을 수집하게 된다.

이미 한번 테스트한 상태라 메트릭이 찍힘 대시보드도 성공적으로 구축된 것이 확인된다.
테스트
현 실습에서는 카펜터를 쓰지 않고 있다가 적용하는 상황을 가정한다.
이에 따라 기존 인스턴스들은 유지한 채로 카펜터에게 관리를 맡기다가 점차 관리를 확장시키는 방식으로 실습해볼까 한다.
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
role: "카펜터를 만들 때 만들어진 node iam role"
amiSelectorTerms:
- alias: "al2023@latest" # ex) al2023@latest
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "terraform-eks"
Name: "*Public*"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "terraform-eks"
---
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"]
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
expireAfter: 720h # 30 * 24h = 720h
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1m
노드풀과 노드 클래스를 만들어본다.
노드 클래스에는 퍼블릭 서브넷에만 배치되도록 세팅했고, 스팟 인스턴스를 활용해본다.


제대로 세팅이 됐다면, 이렇게 True가 돼야 한다.

준비 상태는 검증이 성공해야 하는데, 검증 상태 역시 위의 다른 상태들이 준비 상태가 돼야 통과되므로 준비 상태가 된 것만으로도 모든 것들이 제대로 추적이 되고 있다는 것을 확인할 수 있다.
프로비저닝
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
securityContext:
allowPrivilegeEscalation: false
이번에도 괴물 파드를 만들어본다.

CPU 요청량이 크므로 스케줄이 되지 않는 파드가 발생한다.

참고로 만약 한번도 스팟을 만들어본 적이 없다면 service linked role이 없어서 이러한 에러가 발생한다.

1분도 안 되어 한 노드가 새로 프로비저닝되기 시작했다.

파드가 배치되는 데에도 시간이 거의 걸리지 않았다.

컨트롤러의 로그를 보면, 도움이 필요한 파드를 찾은 후 노드 클레임을 작동시키고 등록하는 과정이 이뤄진 것이 보인다.
디프로비저닝

이번에는 파드를 하나 줄여보았다.
처음에는 c5a.xlarge의 노드를 배치해주었는데, 더 작은 스펙의 노드로 바꿔주면 성공이다.

시간이 지나자 새로운 노드가 또 프로비저닝됐다.

조금 더 시간이 지나니 이렇게 한 노드가 사라졌다.

로그로는 underutilzed 효율화를 위해 노드를 중단한다는 말이 뜬 이후, 새로운 노드클레임 생성, 이후 노후 노드 삭제 절차를 밟는 것이 보인다.

결국 c5a.xlarge에서 c5a.large로 스펙을 줄여주었다!

중간에 이런 이벤트가 관찰됐다.
이 이벤트가 의미하는 게 15개의 인스턴스 타입 선택지를 주지 않으면 Spot2Spot을 안 해준다는 것으로 이해했었는데, 지금 보면 결국 해주기는 한다.
다만 효율적인 비용최적화를 하지 못할 가능성이 높다는 의미인 듯하다.

클라우드트레일에 들어가서 이벤트를 보면, CreateFleet 이벤트가 많이 뜨는 것을 확인할 수 있다.
이때 카펜터는 비용 절감 방안을 찾기 위해 드라이런으로도 api를 요청하는 모양이다.
파드 스케줄링 제약 조건 체크
nodeSelector:
topology.kubernetes.io/zone: ap-northeast-2a
karpenter.k8s.aws/instance-cpu: "8"
파드를 만들면서 well-known 라벨을 이용해 노드에 배치되도록 해본다.

곧바로 설정한 제약을 준수하는 새로운 노드가 프로비저닝됐다.

추가적으로, 바로 통합이 진행되어 처음 테스트할 때 만들어졌던 노드가 삭제되며 기존의 파드가 새로운 노드로 이전됐다.
노드 스케줄링 제약 조건이 존재하는 상황에서, 제약에서 자유로운 파드를 아예 옮기는 식으로 효율적으로 비용을 최적화한 것이다.
결론
클러스터 오토스케일링에는 비용 최적화까지 고려하는 막강한 카펜터가 점차 표준이 되어가는 추세라고 한다.
사람이 일일히 하기 어려운 작업(인스턴스 스펙 + 노드 설정 + 스케줄링 등 한꺼번에 고려해줌!)을 손쉽게 해주므로 매우 유용하다.
카펜터를 잘 활용하기 위한 워크샵이 제공되고 있으므로, 이를 이용해 설정법을 익히고, 효율적으로 클러스터를 운영해보자!
(시간 부족으로 나는 다 진행하지 못했으나, 추후에 조금 더 시간을 들여서 진행할 예정이다.)
이전 글, 다음 글
다른 글 보기
| 이름 | index | noteType | created |
|---|---|---|---|
| 1W - EKS 설치 및 액세스 엔드포인트 변경 실습 | 1 | published | 2025-02-03 |
| 2W - 테라폼으로 환경 구성 및 VPC 연결 | 2 | published | 2025-02-11 |
| 2W - EKS VPC CNI 분석 | 3 | published | 2025-02-11 |
| 2W - ALB Controller, External DNS | 4 | published | 2025-02-15 |
| 3W - kubestr과 EBS CSI 드라이버 | 5 | published | 2025-02-21 |
| 3W - EFS 드라이버, 인스턴스 스토어 활용 | 6 | published | 2025-02-22 |
| 4W - 번외 AL2023 노드 초기화 커스텀 | 7 | published | 2025-02-25 |
| 4W - EKS 모니터링과 관측 가능성 | 8 | published | 2025-02-28 |
| 4W - 프로메테우스 스택을 통한 EKS 모니터링 | 9 | published | 2025-02-28 |
| 5W - HPA, KEDA를 활용한 파드 오토스케일링 | 10 | published | 2025-03-07 |
| 5W - Karpenter를 활용한 클러스터 오토스케일링 | 11 | published | 2025-03-07 |
| 6W - PKI 구조, CSR 리소스를 통한 api 서버 조회 | 12 | published | 2025-03-15 |
| 6W - api 구조와 보안 1 - 인증 | 13 | published | 2025-03-15 |
| 6W - api 보안 2 - 인가, 어드미션 제어 | 14 | published | 2025-03-16 |
| 6W - EKS 파드에서 AWS 리소스 접근 제어 | 15 | published | 2025-03-16 |
| 6W - EKS api 서버 접근 보안 | 16 | published | 2025-03-16 |
| 7W - 쿠버네티스의 스케줄링, 커스텀 스케줄러 설정 | 17 | published | 2025-03-22 |
| 7W - EKS Fargate | 18 | published | 2025-03-22 |
| 7W - EKS Automode | 19 | published | 2025-03-22 |
| 8W - 아르고 워크플로우 | 20 | published | 2025-03-30 |
| 8W - 아르고 롤아웃 | 21 | published | 2025-03-30 |
| 8W - 아르고 CD | 22 | published | 2025-03-30 |
| 8W - CICD | 23 | published | 2025-03-30 |
| 9W - EKS 업그레이드 | 24 | published | 2025-04-02 |
| 10W - Vault를 활용한 CICD 보안 | 25 | published | 2025-04-16 |
| 11W - EKS에서 FSx, Inferentia 활용하기 | 26 | published | 2025-04-18 |
| 11주차 - EKS에서 FSx, Inferentia 활용하기 | 26 | published | 2025-05-11 |
| 12W - VPC Lattice 기반 gateway api | 27 | published | 2025-04-27 |
관련 문서
| 이름 | noteType | created |
|---|---|---|
| HPA | knowledge | 2024-12-29 |
| Cluster Autoscaler | knowledge | 2025-03-05 |
참고
https://karpenter.sh/docs/concepts/scheduling/#well-known-labels ↩︎
https://en.wikipedia.org/wiki/Bin_packing_problemhttps://sangwoo0727.github.io/algorithm/Algorithm-BinPacking/ ↩︎
https://github.com/aws/karpenter-provider-aws/blob/main/designs/bin-packing.md ↩︎
https://github.com/terraform-aws-modules/terraform-aws-eks/tree/v20.33.1/modules/karpenter ↩︎
https://artifacthub.io/packages/helm/aws-karpenter/karpenter ↩︎
https://github.com/aws/karpenter-provider-aws/blob/main/website/content/en/docs/getting-started/getting-started-with-karpenter/prometheus-values.yaml ↩︎
https://github.com/aws/karpenter-provider-aws/blob/main/website/content/en/docs/getting-started/getting-started-with-karpenter/grafana-values.yaml ↩︎